Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función Pandas dataframe.mad()devuelve la desviación absoluta media de los valores para el eje solicitado. La desviación absoluta media de un conjunto de datos es la distancia promedio entre cada punto de datos y la media. Nos da una idea sobre la variabilidad en un conjunto de datos.
Sintaxis: DataFrame.mad(eje=Ninguno, skipna=Ninguno, nivel=Ninguno)
Parámetros:
eje: {índice (0), columnas (1)}
skipna: Excluir NA/valores nulos al calcular el
nivel de resultado: Si el eje es un índice múltiple (jerárquico), cuente a lo largo de un nivel particular, colapsando en una serie
numeric_only: Incluya solo columnas flotantes, int y booleanas. Si es Ninguno, intentará usar todo, luego use solo datos numéricos. No implementado para Serie.Devoluciones: loco: Serie o DataFrame (si se especifica el nivel)
Ejemplo #1: Use mad()la función para encontrar la desviación absoluta media de los valores sobre el eje del índice.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.DataFrame({"A":[12, 4, 5, 44, 1],
"B":[5, 2, 54, 3, 2],
"C":[20, 16, 7, 3, 8],
"D":[14, 3, 17, 2, 6]})
# Print the dataframe
df
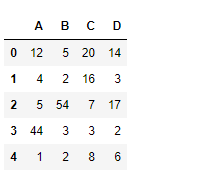
Usemos la dataframe.mad()función para encontrar la desviación absoluta media.
# find the mean absolute deviation # over the index axis df.mad(axis = 0)
Producción :
Ejemplo #2: Use mad()la función para encontrar la desviación media absoluta de los valores sobre el eje de la columna que tiene algunos Navalores.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.DataFrame({"A":[12, 4, 5, None, 1],
"B":[7, 2, 54, 3, None],
"C":[20, 16, 11, 3, 8],
"D":[14, 3, None, 2, 6]})
# To find the mean absolute deviation
# skip the Na values when finding the mad value
df.mad(axis = 1, skipna = True)
Producción :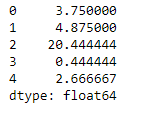
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA