Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función pandas dataframe.memory_usage() devuelve el uso de memoria de cada columna en bytes. El uso de la memoria puede incluir opcionalmente la contribución del índice y los elementos del objeto dtype. Este valor se muestra en DataFrame.info de forma predeterminada.
Sintaxis: DataFrame.memory_usage(index=True, deep=False)
Parámetros:
index: especifica si se debe incluir el uso de memoria del índice de DataFrame en la serie devuelta. Si index=True, el uso de memoria del índice, el primer elemento de la salida.
deep : si es True, realice una introspección profunda de los datos interrogando los tipos de objetos para el consumo de memoria a nivel del sistema e inclúyalos en los valores devueltos.
Devuelve: una serie cuyo índice son los nombres de las columnas originales y cuyos valores son el uso de memoria de cada columna en bytes
Para obtener un enlace al archivo CSV utilizado en el código, haga clic aquí
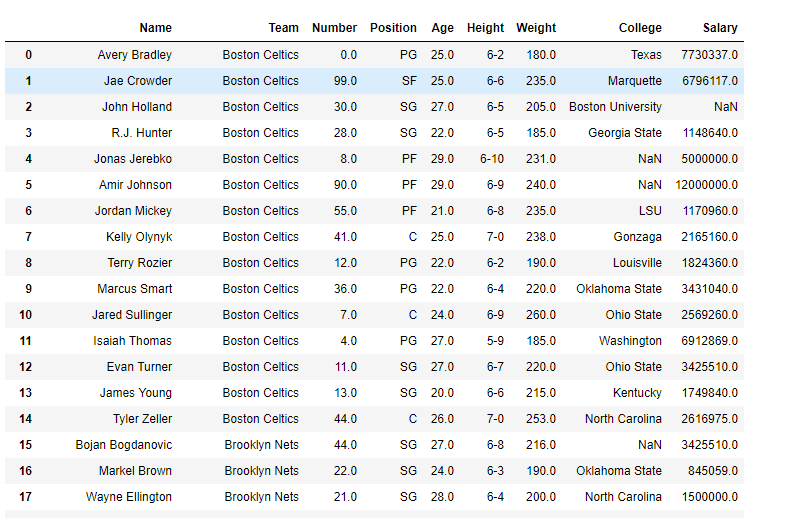
. Ejemplo n.º 1: use la función memory_usage() para imprimir el uso de memoria de cada columna en el marco de datos junto con el uso de memoria del índice.
Python3
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# Print the dataframe
df
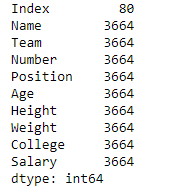
Usemos la función memory_usage() para encontrar el uso de memoria de cada columna.
Python3
# Function to find memory use of each # column along with the index # even if we do not set index = True, # it will show the index usage as well by default. df.memory_usage(index = True)
Producción :
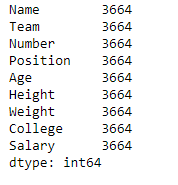
Ejemplo #2: Use la función memory_usage() para encontrar el uso de memoria de cada columna pero no del índice.
Python3
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# Function to find memory use of each
# column but not of the index
# we set index = False
df.memory_usage(index = False)
Producción :
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA