Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
El método Pandas Dataframe.rank()devuelve un rango de cada índice respectivo de una serie aprobada. El rango se devuelve sobre la base de la posición después de la clasificación.
Syntax:
DataFrame.rank(axis=0, method=’promedio’, numeric_only=Ninguno, na_option=’keep’, ascendente=True, pct=False)
Parameters:
eje: 0 o ‘índice’ para filas y 1 o ‘columnas’ para Columna.
método: toma una entrada de string (‘promedio’, ‘mínimo’, ‘máximo’, ‘primero’, ‘denso’) que le dice a los pandas qué hacer con los mismos valores. El valor predeterminado es promedio, lo que significa asignar un promedio de rangos a los valores similares.
numeric_only: toma un valor booleano y la función de rango funciona en valores no numéricos solo si es falso.
na_option: toma la entrada de 3 strings (‘mantener’, ‘arriba’, ‘abajo’) para establecer la posición de los valores nulos, si los hay en la serie pasada.
ascendente: valor booleano que se clasifica en orden ascendente si es verdadero.
pct: valor booleano que clasifica en porcentaje si es verdadero.
Return type:Serie con rango de cada índice de serie de llamadas.
Para obtener un enlace al archivo CSV utilizado en el código, haga clic aquí.
Ejemplo #1: Columna de clasificación con valores únicos
En el siguiente ejemplo, se crea una nueva columna de clasificación que clasifica el nombre de cada jugador. Todos los valores en la columna Nombre son únicos y, por lo tanto, no es necesario describir un método.
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# creating a rank column and passing the returned rank series
data["Rank"] = data["Name"].rank()
# display
data
# sorting w.r.t name column
data.sort_values("Name", inplace = True)
# display after sorting w.r.t Name column
data
Salida:
como se muestra en la imagen, se creó un rango de columna con el rango de cada Nombre. Después de que la función sort_value clasificó el marco de datos con respecto al nombre, se puede ver que el rango también se clasificó, ya que solo se clasificaron los nombres.
Antes de ordenar – 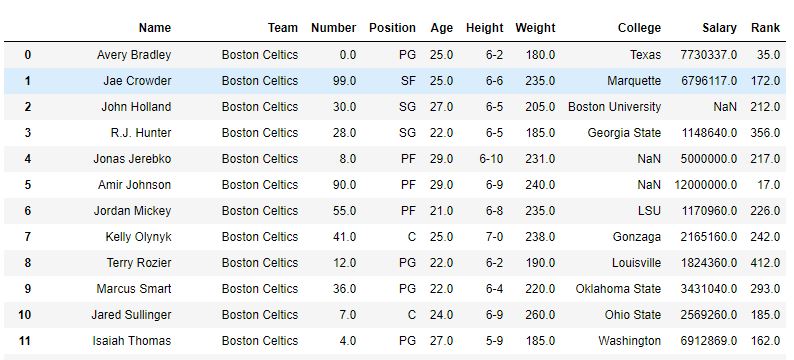
Después de ordenar – 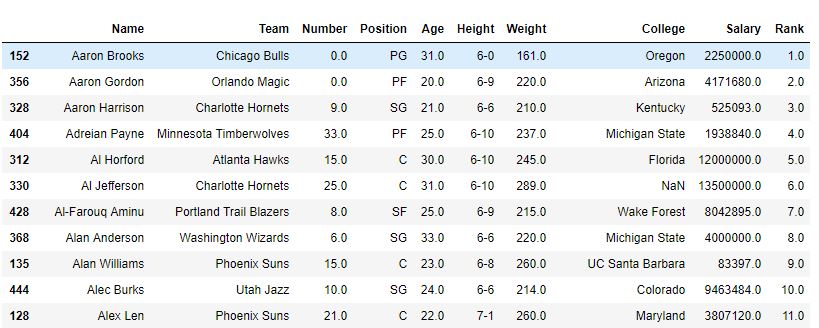
Ejemplo n.º 2: Ordenar columna con algunos valores similares
En el siguiente ejemplo, el marco de datos se ordena primero con respecto al nombre del equipo y primero el método es predeterminado (es decir, promedio) y, por lo tanto, el rango de los mismos jugadores del equipo es promedio. Después de eso, el método min también se usa para ver la salida.
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# sorting w.r.t team name
data.sort_values("Team", inplace = True)
# creating a rank column and passing the returned rank series
# change method to 'min' to rank by minimum
data["Rank"] = data["Team"].rank(method ='average')
# display
data
Producción:
Con método=’promedio’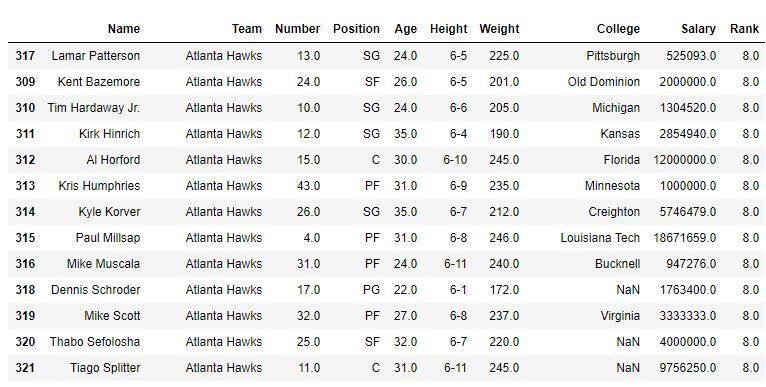
Con método=’min’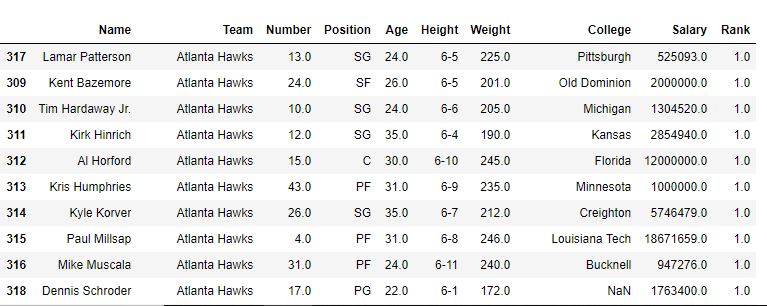
Publicación traducida automáticamente
Artículo escrito por Kartikaybhutani y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA