Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función Pandas dataframe.reindex()ajusta DataFrame al nuevo índice con lógica de llenado opcional, colocando NA/NaN en ubicaciones que no tienen valor en el índice anterior. Se produce un nuevo objeto a menos que el nuevo índice sea equivalente al actual y copy=False
Sintaxis: DataFrame.reindex(etiquetas=Ninguno, índice=Ninguno, columnas=Ninguno, eje=Ninguno, método=Ninguno, copia=Verdadero, nivel=Ninguno, valor_relleno=nan, límite=Ninguno, tolerancia=Ninguno)
Parámetros:
etiquetas: Nuevas etiquetas/índice para conformar el eje especificado por ‘eje’.
índice, columnas: Nuevas etiquetas / índice para cumplir. Preferiblemente, un objeto de índice para evitar la duplicación del eje de datos
: eje al objetivo. Puede ser el nombre del eje (‘índice’, ‘columnas’) o el número (0, 1).
método: {Ninguno, ‘relleno’/’bfill’, ‘pad’/’relleno’, ‘más cercano’},
copia opcional: Devolver un nuevo objeto, incluso si los índices pasados son del mismo
nivel: Transmitir a través de un nivel, haciendo coincidir Valores de índice en el nivel MultiIndex pasado
fill_value :Rellene los valores faltantes existentes (NaN) y cualquier elemento nuevo necesario para la alineación exitosa de DataFrame, con este valor antes del cálculo. Si faltan datos en ambas ubicaciones correspondientes de DataFrame, faltará el resultado.
límite: número máximo de elementos consecutivos para completar hacia adelante o hacia atrás
tolerancia: distancia máxima entre etiquetas originales y nuevas para coincidencias inexactas. Los valores del índice en las ubicaciones coincidentes satisfacen la ecuación abs (índice [indexador] – objetivo) <= tolerancia.Devoluciones: reindexado: DataFrame
Ejemplo n.º 1: utilice reindex()la función para volver a indexar el marco de datos. De forma predeterminada, los valores en el nuevo índice que no tienen registros correspondientes en el marco de datos se asignan a NaN.
Nota: podemos completar los valores faltantes pasando un valor a la palabra clave fill_value.
# importing pandas as pd
import pandas as pd
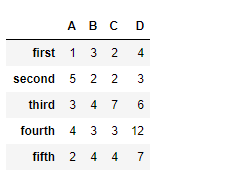
# Creating the dataframe
df = pd.DataFrame({"A":[1, 5, 3, 4, 2],
"B":[3, 2, 4, 3, 4],
"C":[2, 2, 7, 3, 4],
"D":[4, 3, 6, 12, 7]},
index =["first", "second", "third", "fourth", "fifth"])
# Print the dataframe
df
Usemos la dataframe.reindex()función para reindexar el marco de datos.
# reindexing with new index values df.reindex(["first", "dues", "trois", "fourth", "fifth"])
Salida: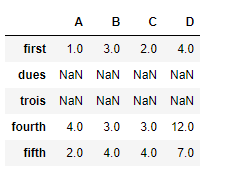
observe la salida, los nuevos índices se completan con NaNvalores, podemos completar los valores faltantes usando el parámetro, fill_value
# filling the missing values by 100 df.reindex(["first", "dues", "trois", "fourth", "fifth"], fill_value = 100)
Salida: 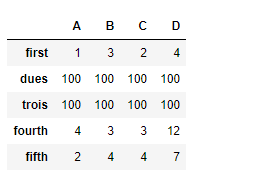
Ejemplo n.º 2: use reindex()la función para volver a indexar el eje de la columna
# importing pandas as pd
import pandas as pd
# Creating the first dataframe
df1 = pd.DataFrame({"A":[1, 5, 3, 4, 2],
"B":[3, 2, 4, 3, 4],
"C":[2, 2, 7, 3, 4],
"D":[4, 3, 6, 12, 7]})
# reindexing the column axis with
# old and new index values
df.reindex(columns =["A", "B", "D", "E"])
Salida: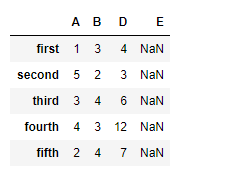
tenga en cuenta que tenemos NaNvalores en las nuevas columnas después de la reindexación, podemos ocuparnos de los valores faltantes en el momento de la reindexación. Pasando un argumento fill_value a la función.
# reindex the columns # fill the missing values by 25 df.reindex(columns =["A", "B", "D", "E"], fill_value = 25)
Producción :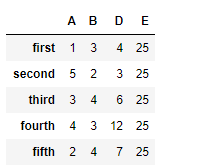
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA