Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
Pandas reset_index()es un método para restablecer el índice de un marco de datos. El método reset_index() establece una lista de enteros que van desde 0 hasta la longitud de los datos como índice.
Sintaxis:
DataFrame.reset_index(level=Ninguno, drop=False, inplace=False, col_level=0, col_fill=”)Parámetros:
nivel: int, string o una lista para seleccionar y eliminar la columna pasada del índice.
soltar: valor booleano, agrega la columna de índice reemplazada a los datos si es falso.
inplace: valor booleano, realice cambios en el marco de datos original si es True.
col_level: Seleccione en qué nivel de columna insertar las etiquetas.
col_fill: Objeto, para determinar cómo se nombran los demás niveles.Tipo de devolución: marco de datos
Para descargar el archivo CSV utilizado, haga clic aquí.
Ejemplo n.º 1: Restablecimiento del índice
En este ejemplo, para restablecer el índice, la columna de nombre se estableció primero como columna de índice y luego se generó un índice nuevo al usar el índice de restablecimiento.
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# setting first name as index column
data.set_index(["First Name"], inplace = True,
append = True, drop = True)
# resetting index
data.reset_index(inplace = True)
# display
data.head()
Salida:
como se muestra en las imágenes de salida, se ha generado una nueva etiqueta de índice denominada level_0.
Antes del reinicio – 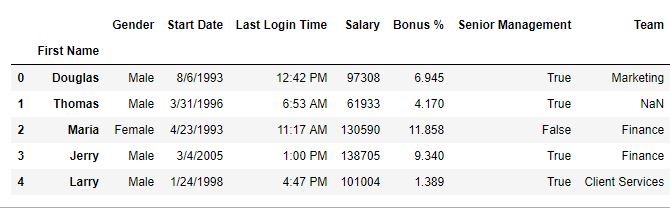
Después del reinicio –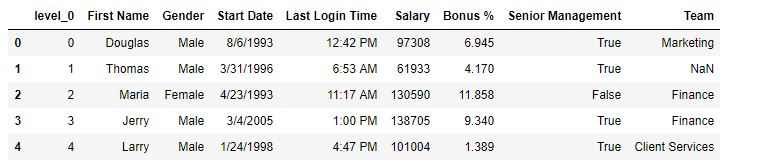
Ejemplo n.º 2: operación en el índice de niveles múltiples
En este ejemplo, se agregan 2 columnas (nombre y género) a la columna de índice y luego se elimina un nivel mediante el método reset_index().
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# setting first name as index column
data.set_index(["First Name", "Gender"], inplace = True,
append = True, drop = True)
# resetting index
data.reset_index(level = 2, inplace = True, col_level = 1)
# display
data.head()
Salida:
como se muestra en la imagen de salida, la columna de género en la columna de índice se reemplazó porque su nivel era 2.
Antes del reinicio – 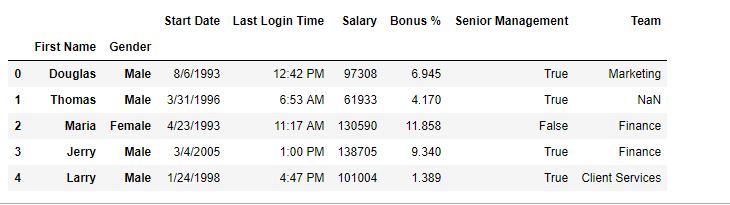
Después del reinicio –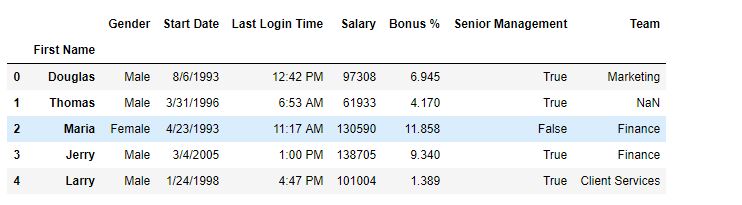
Publicación traducida automáticamente
Artículo escrito por Kartikaybhutani y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA