Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función Pandas dataframe.rsub()se usa para encontrar la resta del marco de datos y otros elementos (operador binario rfloordiv). Esta función es esencialmente la misma que hacer otra: marco de datos, pero con un soporte para sustituir los datos que faltan en una de las entradas.
Sintaxis: DataFrame.rsub(other, axis=’columns’, level=None, fill_value=None)
Parámetros:
otro: Serie, DataFrame o
eje constante: Para la entrada de la serie, el eje coincide con el índice de la serie en el
nivel: Difusión a través de un nivel , haciendo coincidir los valores de índice en el nivel MultiIndex pasado
fill_value : Rellene los valores faltantes existentes (NaN) y cualquier elemento nuevo necesario para la alineación exitosa de DataFrame, con este valor antes del cálculo. Si faltan datos en ambas ubicaciones correspondientes de DataFrame, faltará el resultado.Devuelve: resultado: DataFrame
Ejemplo #1: Use rsub()la función para restar cada elemento de una serie a un valor correspondiente en un marco de datos sobre el eje de la columna.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
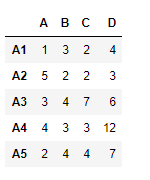
df = pd.DataFrame({"A":[1, 5, 3, 4, 2],
"B":[3, 2, 4, 3, 4],
"C":[2, 2, 7, 3, 4],
"D":[4, 3, 6, 12, 7]},
index =["A1", "A2", "A3", "A4", "A5"])
# Print the dataframe
df
Creamos la serie
# importing pandas as pd import pandas as pd # Create the series sr = pd.Series([12, 25, 64, 18], index =["A", "B", "C", "D"]) # Print the series sr

Usemos la dataframe.rsub()función para restar cada elemento de una serie con el elemento correspondiente en el marco de datos.
# equivalent to sr - df df.rsub(sr, axis = 1)
Salida: 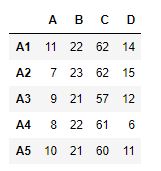
Ejemplo n.º 2: use rsub()la función para restar cada elemento en un marco de datos con el elemento correspondiente en otro marco de datos
# importing pandas as pd
import pandas as pd
# Creating the first dataframe
df1 = pd.DataFrame({"A":[1, 5, 3, 4, 2],
"B":[3, 2, 4, 3, 4],
"C":[2, 2, 7, 3, 4],
"D":[4, 3, 6, 12, 7]},
index =["A1", "A2", "A3", "A4", "A5"])
# Creating the second dataframe
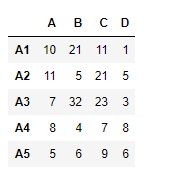
df2 = pd.DataFrame({"A":[10, 11, 7, 8, 5],
"B":[21, 5, 32, 4, 6],
"C":[11, 21, 23, 7, 9],
"D":[1, 5, 3, 8, 6]},
index =["A1", "A2", "A3", "A4", "A5"])
# Print the first dataframe
print(df1)
# Print the second dataframe
print(df2)
Vamos a realizardf2 - df1
# subtract df1 from df2 df1.rsub(df2)
Producción :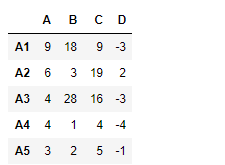
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA