Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función Pandas dataframe.sem()devuelve un error estándar imparcial de la media sobre el eje solicitado. El error estándar (SE) de una estadística (generalmente una estimación de un parámetro) es la desviación estándar de su distribución de muestreo[1] o una estimación de esa desviación estándar. Si el parámetro o la estadística es la media, se denomina error estándar de la media (SEM).
Sintaxis: DataFrame.sem(axis=Ninguno, skipna=Ninguno, level=Ninguno, ddof=1, numeric_only=Ninguno, **kwargs)
Parámetros:
eje: {índice (0), columnas (1)}
skipna: Excluir NA/valores nulos. Si toda una fila/columna es NA, el resultado será un
nivel NA: Si el eje es un Multiíndice (jerárquico), cuente a lo largo de un nivel particular, colapsando en una Serie
ddof: Delta Grados de libertad. El divisor utilizado en los cálculos es N – ddof, donde N representa el número de elementos.
numeric_only : incluye solo columnas flotantes, int y booleanas. Si es Ninguno, intentará usar todo, luego use solo datos numéricos. No implementado para SerieRetorno: sem: Serie o DataFrame (si se especifica el nivel)
Para obtener un enlace al archivo CSV utilizado en el código, haga clic aquí
Ejemplo #1: Use sem()la función para encontrar el error estándar de la media del marco de datos dado sobre el eje del índice.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# Print the dataframe
df
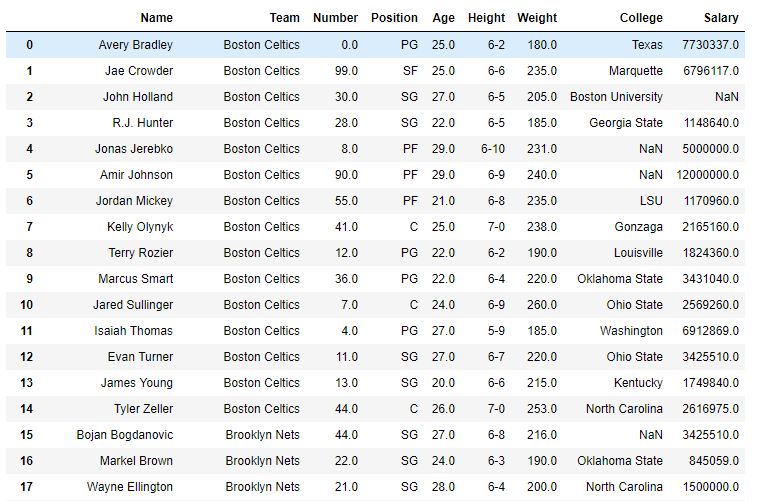
Usemos la dataframe.sem()función para encontrar el error estándar de la media sobre el eje del índice.
# find standard error of the mean of all the columns df.sem(axis = 0)
Salida: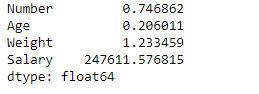
Tenga en cuenta que todas las columnas y valores no numéricos no se incluyen automáticamente en el cálculo del marco de datos. No tuvimos que ingresar específicamente las columnas numéricas para el cálculo del error estándar de la media.
Ejemplo #2: Use sem()la función para encontrar el error estándar de la media sobre el eje de la columna. Tampoco omita los NaNvalores en el cálculo del marco de datos.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# Calculate the standard error of
# the mean of all the rows in dataframe
df.sem(axis = 1, skipna = False)
Salida: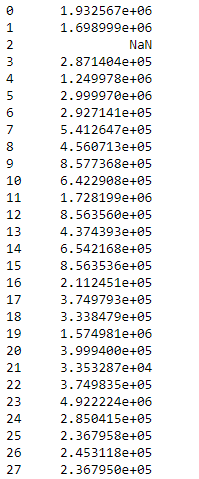
cuando incluimos los NaNvalores, hará que esa fila o columna en particular seaNaN
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA