Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
Pandas set_index() es un método para establecer una lista, una serie o un marco de datos como índice de un marco de datos. La columna de índice también se puede configurar al crear un marco de datos. Pero a veces, un marco de datos se compone de dos o más marcos de datos y, por lo tanto, el índice posterior se puede cambiar utilizando este método.
Sintaxis:
DataFrame.set_index(claves, soltar=Verdadero, agregar=Falso, en el lugar=Falso, verificar_integridad=Falso)
Parámetros:
claves: Nombre de columna o lista de nombres de columna.
drop: valor booleano que elimina la columna utilizada para el índice si es True.
agregar: agrega la columna a la columna de índice existente si es Verdadero.
inplace: realiza los cambios en el marco de datos si es True.
verificar_integridad: verifica la nueva columna de índice en busca de duplicados si es Verdadero.
Para descargar el archivo CSV utilizado, haga clic aquí.
Código n.º 1: Cambio de columna de índice
En este ejemplo, la columna Nombre se convirtió en la columna de índice del marco de datos.
Python3
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# setting first name as index column
data.set_index("First Name", inplace = True)
# display
data.head()
Salida:
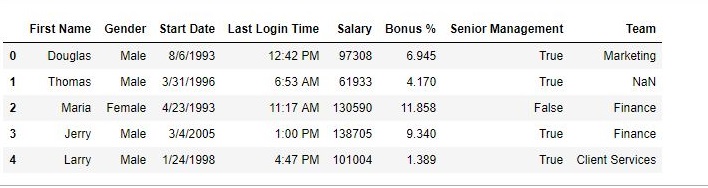
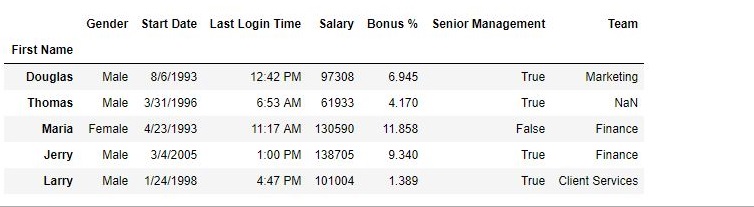
como se muestra en las imágenes de salida, anteriormente la columna de índice era una serie de números, pero luego se reemplazó con Nombre.
Antes de la operación –
Después de la operación –
Código #2: Columna de índice múltiple
En este ejemplo, se crearán dos columnas como columna de índice. El parámetro de eliminación se usa para eliminar la columna y el parámetro de adición se usa para agregar columnas pasadas a la columna de índice ya existente.
Python3
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# setting first name as index column
data.set_index(["First Name", "Gender"], inplace = True,
append = True, drop = False)
# display
data.head()
Salida:
como se muestra en la imagen de salida, los datos tienen 3 columnas de índice.
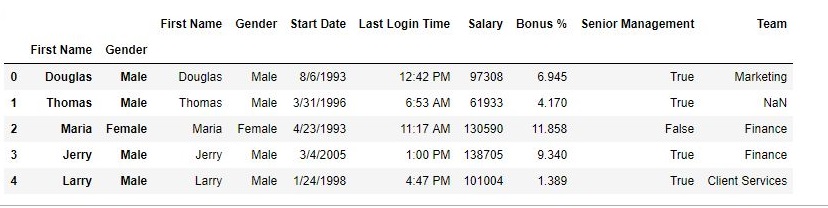
Código n. ° 3: configuración de una sola columna flotante como índice en Pandas DataFrame
Python3
# importing pandas library
import pandas as pd
# creating and initializing a nested list
students = [['jack', 34, 'Sydeny', 'Australia',85.96],
['Riti', 30, 'Delhi', 'India',95.20],
['Vansh', 31, 'Delhi', 'India',85.25],
['Nanyu', 32, 'Tokyo', 'Japan',74.21],
['Maychan', 16, 'New York', 'US',99.63],
['Mike', 17, 'las vegas', 'US',47.28]]
# Create a DataFrame object
df = pd.DataFrame(students,
columns=['Name', 'Age', 'City', 'Country','Agg_Marks'],
index=['a', 'b', 'c', 'd', 'e', 'f'])
# here we set Float column 'Agg_Marks' as index of data frame
# using dataframe.set_index() function
df = df.set_index('Agg_Marks')
# Displaying the Data frame
df
Producción :
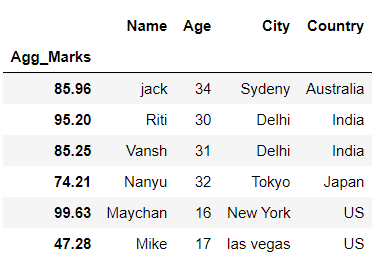
En el ejemplo anterior, configuramos la columna ‘ Agg_Marks ‘ como un índice del marco de datos.
Código n. ° 4: Configuración de tres columnas como MultiIndex en Pandas DataFrame
Python3
# importing pandas library import pandas as pd # creating and initializing a nested list students = [['jack', 34, 'Sydeny', 'Australia',85.96,400], ['Riti', 30, 'Delhi', 'India',95.20,750], ['Vansh', 31, 'Delhi', 'India',85.25,101], ['Nanyu', 32, 'Tokyo', 'Japan',74.21,900], ['Maychan', 16, 'New York', 'US',99.63,420], ['Mike', 17, 'las vegas', 'US',47.28,555]] # Create a DataFrame object df = pd.DataFrame(students, columns=['Name', 'Age', 'City', 'Country','Agg_Marks','ID'], index=['a', 'b', 'c', 'd', 'e', 'f']) # Here we pass list of 3 columns i.e 'Name', 'City' and 'ID' # to dataframe.set_index() function # to set them as multiIndex of dataframe df = df.set_index(['Name','City','ID']) # Displaying the Data frame df
Producción :
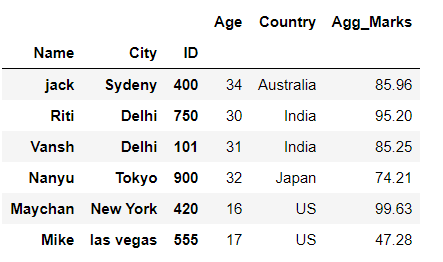
En el ejemplo anterior, configuramos las columnas ‘ Nombre ‘, ‘ Ciudad ‘ e ‘ ID ‘ como índice múltiple del marco de datos.
Publicación traducida automáticamente
Artículo escrito por Kartikaybhutani y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA