Pandas DataFrame es una estructura de datos tabulares potencialmente heterogénea, de tamaño mutable, bidimensional con ejes etiquetados (filas y columnas). Las operaciones aritméticas se alinean en las etiquetas de fila y columna. Se puede considerar como un contenedor similar a un dictado para objetos Series. Esta es la estructura de datos principal de Pandas.
La función Pandas DataFrame.truncate()se usa para truncar una serie o un marco de datos antes y después de algún valor de índice. Esta es una abreviatura útil para la indexación booleana basada en valores de índice por encima o por debajo de ciertos umbrales.
Sintaxis: DataFrame.truncate(before=Ninguno, after=Ninguno, axis=Ninguno, copy=True)
Parámetro:
before: trunca todas las filas antes de este valor de índice.
after: trunca todas las filas después de este valor de índice.
axis : Eje a truncar. Trunca el índice (filas) de forma predeterminada.
copy : Devuelve una copia de la sección truncada.Devuelve: la serie truncada o el marco de datos.
Ejemplo #1: Use DataFrame.truncate()la función para truncar algunas entradas antes y después de las etiquetas pasadas del marco de datos dado.
# importing pandas as pd
import pandas as pd
# Creating the DataFrame
df = pd.DataFrame({'Weight':[45, 88, 56, 15, 71],
'Name':['Sam', 'Andrea', 'Alex', 'Robin', 'Kia'],
'Age':[14, 25, 55, 8, 21]})
# Create the index
index_ = pd.date_range('2010-10-09 08:45', periods = 5, freq ='H')
# Set the index
df.index = index_
# Print the DataFrame
print(df)
Producción :
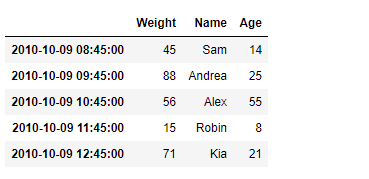
Ahora usaremos DataFrame.truncate()la función para truncar las entradas antes de ‘2010-10-09 09:45:00’ y después de ‘2010-10-09 11:45:00’ en el marco de datos dado.
# return the truncated dataframe result = df.truncate(before = '2010-10-09 09:45:00', after = '2010-10-09 11:45:00') # Print the result print(result)
Producción :
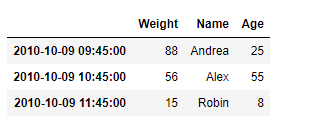
Como podemos ver en el resultado, la DataFrame.truncate()función ha truncado con éxito las entradas antes y después de las etiquetas pasadas en el marco de datos dado.
Ejemplo #2: Use DataFrame.truncate()la función para truncar algunas entradas antes y después de las etiquetas pasadas del marco de datos dado.
# importing pandas as pd
import pandas as pd
# Creating the DataFrame
df = pd.DataFrame({"A":[12, 4, 5, None, 1],
"B":[7, 2, 54, 3, None],
"C":[20, 16, 11, 3, 8],
"D":[14, 3, None, 2, 6]})
# Create the index
index_ = ['Row_1', 'Row_2', 'Row_3', 'Row_4', 'Row_5']
# Set the index
df.index = index_
# Print the DataFrame
print(df)
Producción :
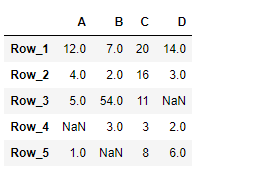
Ahora usaremos DataFrame.truncate()la función para truncar las entradas antes de ‘Row_3’ y después de ‘Row_4’ en el marco de datos dado.
# return the truncated dataframe result = df.truncate(before = 'Row_3', after = 'Row_4') # Print the result print(result)
Producción :
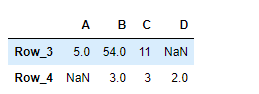
Como podemos ver en el resultado, la DataFrame.truncate()función ha truncado con éxito las entradas antes y después de las etiquetas pasadas en el marco de datos dado.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA