Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función Pandas Index.get_duplicates()extrae elementos de índice duplicados. Esta función devuelve una lista ordenada de elementos de índice que aparecen más de una vez en el Índice.
Sintaxis: Index.get_duplicates()
Devoluciones: Lista de índices duplicados.
Ejemplo #1: Use Index.get_duplicates()la función para encontrar todos los valores duplicados en el Índice.
# importing pandas as pd import pandas as pd # Creating the Index idx = pd.Index(['Labrador', 'Beagle', 'Labrador', 'Lhasa', 'Husky', 'Beagle']) # Print the Index idx
Producción :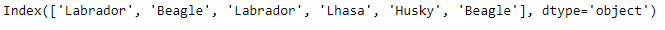
averigüemos todos los valores duplicados en el Índice.
# print the duplicated values. idx.get_duplicates()
Salida:
como podemos ver en la salida, la Index.get_duplicates()función ha devuelto todos los valores que tienen más de una aparición en el Índice.
Ejemplo #2: Use Index.get_duplicates()la función para encontrar todos los duplicados en el Índice. El índice también contiene NaNvalores.
# importing pandas as pd import pandas as pd # Creating the Index idx = pd.Index(['Labrador', 'Beagle', None, 'Labrador', 'Lhasa', 'Husky', 'Beagle', None, 'Koala']) # Print the Index idx
Salida:
como podemos ver en la salida, nos faltan algunos valores. Veamos cómo los Index.get_duplicates()trata la función.
# print the duplicate values in Index idx.get_duplicates()
Salida:
la aparición de valores faltantes más de una vez se ha tratado como duplicado.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA