pandas.pivot_table(datos, valores=Ninguno, índice=Ninguno, columnas=Ninguno, aggfunc=’media’, fill_value=Ninguno, margins=False, dropna=True, margins_name=’All’) crea una tabla dinámica al estilo de una hoja de cálculo como una trama de datos.
Los niveles en la tabla dinámica se almacenarán en objetos MultiIndex (índices jerárquicos) en el índice y las columnas del DataFrame de resultados.
Parameters:datos:
valores de DataFrame : columna para agregar,
índice opcional : columna, agrupador, array o lista de las
columnas anteriores: columna, agrupador, array o lista de las anterioresaggfunc: function, list of functions, dict, default numpy.mean
-> Si se pasa la lista de funciones, la tabla dinámica resultante tendrá columnas jerárquicas cuyo nivel superior son los nombres de las funciones.
-> Si se pasa dict, la clave es la columna para agregar y el valor es la función o la lista de funcionesfill_value[escalar, predeterminado Ninguno]: Valor para reemplazar los valores faltantes con
márgenes[booleano, predeterminado Falso]: Agregue todas las filas/columnas (por ejemplo, para subtotal/gran total)
dropna[booleano, predeterminado Verdadero]: No incluya columnas cuyas entradas sean all NaN
margins_name[string, default ‘All’] : Nombre de la fila/columna que contendrá los totales cuando margins sea True.
Returns:Marco de datos
Código:
# Create a simple dataframe
# importing pandas as pd
import pandas as pd
import numpy as np
# creating a dataframe
df = pd.DataFrame({'A': ['John', 'Boby', 'Mina', 'Peter', 'Nicky'],
'B': ['Masters', 'Graduate', 'Graduate', 'Masters', 'Graduate'],
'C': [27, 23, 21, 23, 24]})
df
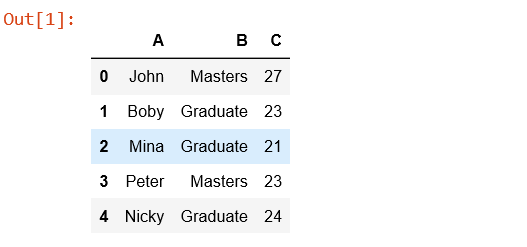
# Simplest pivot table must have a dataframe # and an index/list of index. table = pd.pivot_table(df, index =['A', 'B']) table
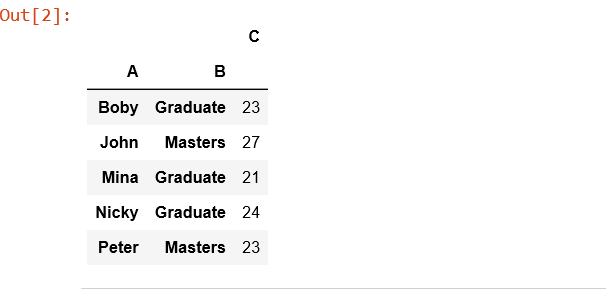
# Creates a pivot table dataframe table = pd.pivot_table(df, values ='A', index =['B', 'C'], columns =['B'], aggfunc = np.sum) table