La serie Pandas es un ndarray unidimensional con etiquetas de eje. No es necesario que las etiquetas sean únicas, pero deben ser de tipo hashable. El objeto admite la indexación basada en enteros y etiquetas y proporciona una gran cantidad de métodos para realizar operaciones relacionadas con el índice.
La función Pandas Series.sem()devuelve un error estándar imparcial de la media sobre el eje solicitado. El resultado está normalizado por N-1 por defecto. Esto se puede cambiar usando el argumento ddof.
Sintaxis: Series.sem(axis=Ninguno, skipna=Ninguno, level=Ninguno, ddof=1, numeric_only=Ninguno, **kwargs)
Parámetro:
eje: {índice (0)}
skipna: Excluir NA/valores nulos.
level : si el eje es un MultiIndex (jerárquico), cuente a lo largo de un nivel particular, colapsando en un escalar.
ddof : Delta Grados de Libertad.
numeric_only : incluye solo columnas flotantes, int y booleanas.Devoluciones: escalar o serie (si se especifica el nivel)
Ejemplo #1: use Series.sem()la función para encontrar el error estándar de la media de los datos subyacentes en el objeto Serie dado.
# importing pandas as pd import pandas as pd # Creating the Series sr = pd.Series([100, 25, 32, 118, 24, 65]) # Print the series print(sr)
Producción :
Ahora usaremos Series.sem()la función para encontrar el error estándar de la media de los datos subyacentes.
# find standard error of the mean sr.sem()
Producción :
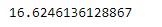
As we can see in the output, Series.sem() function has successfully calculated the standard error the mean of the underlying data in the given Series object.
Example #2 : Use Series.sem() function to find the standard error of the mean of the underlying data in the given Series object. The given Series object also contains some missing values.
# importing pandas as pd import pandas as pd # Creating the Series sr = pd.Series([19.5, 16.8, None, 22.78, None, 20.124, None, 18.1002, None]) # Print the series print(sr)
Producción :
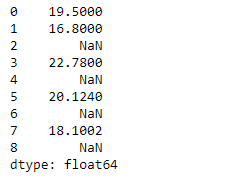
Ahora usaremos Series.sem()la función para encontrar el error estándar de la media de los datos subyacentes.
# find standard error of the mean # Skip all the missing values sr.sem(skipna = True)
Producción :
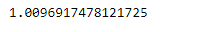
Como podemos ver en el resultado, la Series.sem()función calculó con éxito el error estándar, la media de los datos subyacentes en el objeto Serie dado.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA