Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
El método Pandas str.count()se usa para contar la aparición de una string o un patrón de expresiones regulares en cada string de una serie. También se pueden pasar argumentos de banderas adicionales a handle para modificar algunos aspectos de expresiones regulares como la distinción entre mayúsculas y minúsculas, la coincidencia de varias líneas, etc.
Dado que este es un método de string de pandas, solo es aplicable en series de strings y .str debe tener el prefijo cada vez antes de llamar a este método. De lo contrario, dará un error.
Sintaxis: Series.str.count(pat, flags=0)
Parámetros:
pat: string o expresión regular que se buscará en las strings presentes en la serie
indicadores: indicadores Regex que se pueden pasar (A, S, L, M, I, X), el valor predeterminado es 0, lo que significa Ninguno. Para este módulo regex (re) también se debe importar.Tipo de valor devuelto: Serie con recuento de ocurrencia de caracteres pasados en cada string.
Para descargar el CSV utilizado en el código, haga clic aquí.
En los siguientes ejemplos, el marco de datos utilizado contiene datos de algunos jugadores de la NBA. La imagen del marco de datos antes de cualquier operación se adjunta a continuación.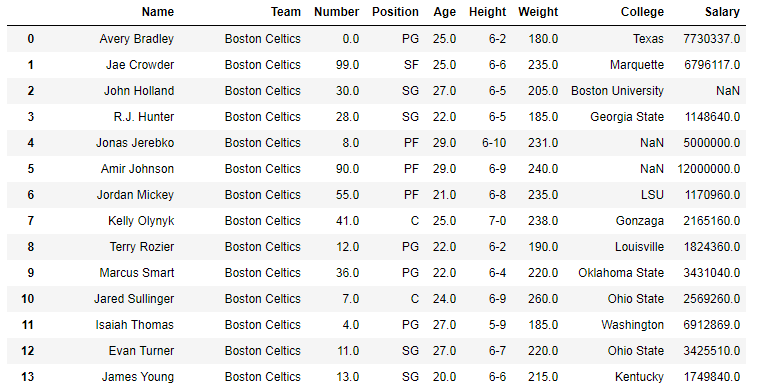
Ejemplo #1: Conteo de ocurrencia de palabras
En este ejemplo, una serie de Pandas se crea a partir de una lista y la ocurrencia de gfg se cuenta usando el método str.count().
# importing pandas package
import pandas as pd
# making list
list =["GeeksforGeeks", "Geeksforgeeks", "geeksforgeeks",
"geeksforgeeks is a great platform", "for tech geeks"]
# making series
series = pd.Series(list)
# counting occurrence of geeks
count = series.str.count("geeks")
# display
count
Salida:
como se muestra en la imagen de salida, se mostró la aparición de geeks en cada string y no se contaron los geeks debido a la primera letra mayúscula. 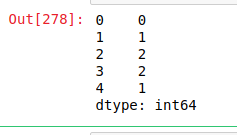
Ejemplo #2: Uso de banderas
En este ejemplo, la aparición de «a» se cuenta en la columna Nombre. El parámetro flag también se usa y se le pasa re.I, lo que significa IGNORECASE. Por lo tanto, tanto a como A se considerarán durante el conteo.
# importing pandas module
import pandas as pd
# importing module for regex
import re
# reading csv file from url
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# String to be searched in start of string
search ="a"
# count of occurrence of a and creating new column
data["count"]= data["Name"].str.count(search, re.I)
# display
data
Salida:
como se muestra en la imagen de salida, se puede comparar claramente mirando el primer índice en sí mismo, el recuento de a en Avery Bradely es 2, lo que significa que se consideraron mayúsculas y minúsculas.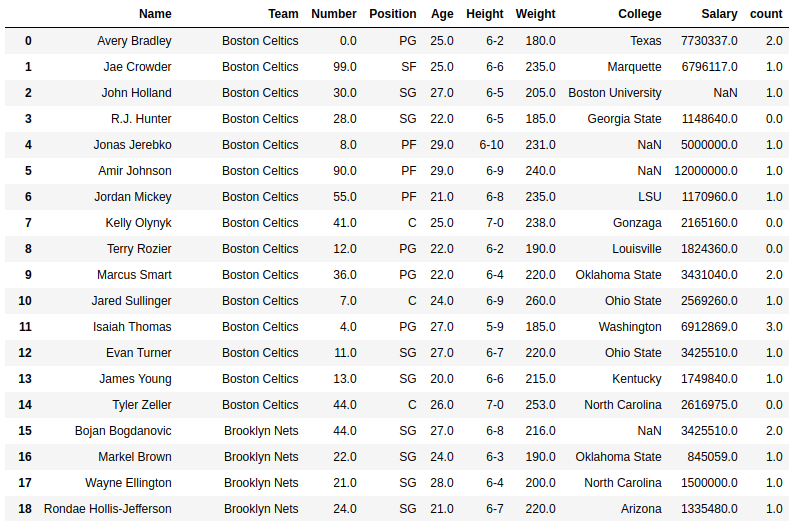
Publicación traducida automáticamente
Artículo escrito por Kartikaybhutani y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA