Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes que facilita mucho la importación y el análisis de datos. El método Pandas Series.str.replace() funciona solo como el método Python .replace() , pero también funciona en Series. Antes de llamar a .replace() en una serie de Pandas, se debe anteponer .str para diferenciarlo del método de reemplazo predeterminado de Python.
Sintaxis: Series.str.replace(pat, repl, n=-1, case=None, regex=True) Parámetros: pat: string o expresión regular compilada para ser reemplazada repl: string o invocable para reemplazar en lugar de pat n: Número de reemplazo para hacer en una sola string, el valor predeterminado es -1, lo que significa Todo. case: toma un valor booleano para decidir la distinción entre mayúsculas y minúsculas. Hacer falso para expresiones regulares que no distinguen entre mayúsculas y minúsculas : valor booleano; si es verdadero, suponga que el patrón pasado es una expresión regular Tipo de retorno: serie con valores de texto reemplazados
Para descargar el CSV utilizado en el código, haga clic aquí.
En los siguientes ejemplos, el marco de datos utilizado contiene datos de algunos jugadores de la NBA. La imagen del marco de datos antes de cualquier operación se adjunta a continuación. 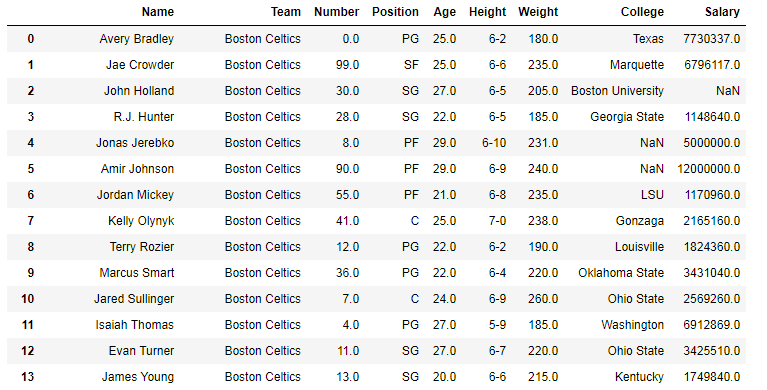
Ejemplo #1: Reemplazo de valores en la columna de edad En este ejemplo, todos los valores en la columna de edad que tienen el valor 25.0 se reemplazan con «Veinticinco» usando str.replace() Después de eso, se crea un filtro y se pasa en el método .where() para mostrar solo las filas que tienen Edad = «Veinticinco».
Python3
# importing pandas module
import pandas as pd
# reading csv file from url
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# overwriting column with replaced value of age
data["Age"]= data["Age"].replace(25.0, "Twenty five")
# creating a filter for age column
# where age = "Twenty five"
filter = data["Age"]=="Twenty five"
# printing only filtered columns
data.where(filter).dropna()
Salida: como se muestra en la imagen de salida, todos los valores en la columna Edad que tienen edad = 25.0 han sido reemplazados por «Veinticinco». 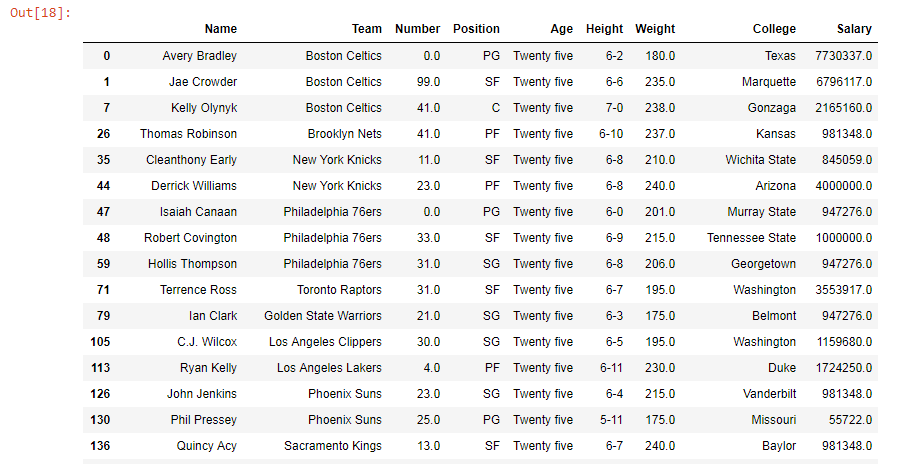 Ejemplo #2: Insensibilidad a mayúsculas y minúsculas En este ejemplo, el nombre del equipo Boston Celtics se reemplaza por New Boston Celtics . En los parámetros, en lugar de pasar Boston, se pasa boston (con ‘b’ en minúsculas) y el caso se establece en False, lo que significa que no distingue entre mayúsculas y minúsculas. Después de eso, solo los equipos que tienen el nombre de equipo «New Boston Celtics» se muestran usando el método .where().
Ejemplo #2: Insensibilidad a mayúsculas y minúsculas En este ejemplo, el nombre del equipo Boston Celtics se reemplaza por New Boston Celtics . En los parámetros, en lugar de pasar Boston, se pasa boston (con ‘b’ en minúsculas) y el caso se establece en False, lo que significa que no distingue entre mayúsculas y minúsculas. Después de eso, solo los equipos que tienen el nombre de equipo «New Boston Celtics» se muestran usando el método .where().
Python3
# importing pandas module
import pandas as pd
# reading csv file from url
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# overwriting column with replaced value of age
data["Team"]= data["Team"].str.replace("boston", "New Boston", case = False)
# creating a filter for age column
# where age = "Twenty five"
filter = data["Team"]=="New Boston Celtics"
# printing only filtered columns
data.where(filter).dropna()
Salida: como se muestra en la imagen de salida, Boston se reemplaza por New Boston independientemente de las minúsculas pasadas en los parámetros. Esto se debe a que el parámetro case se estableció en False. 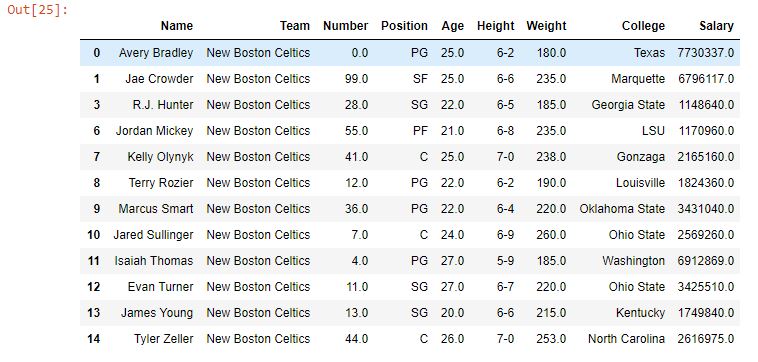
Publicación traducida automáticamente
Artículo escrito por Kartikaybhutani y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA