Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos. La función Pandas TimedeltaIndex.drop_duplicates() devuelve el índice con los valores duplicados eliminados. La función brinda la flexibilidad de elegir qué valor duplicado mantener y qué resto descartar.
Sintaxis: TimedeltaIndex.drop_duplicates(mantener=’primero’)
Parámetros: mantener: {‘primero’, ‘último’, Falso}, predeterminado ‘primero’ -> primero: eliminar duplicados excepto la primera aparición. -> last : elimina los duplicados excepto la última aparición. -> Falso: eliminar todos los duplicados
Retorno: deduplicado: Índice
Ejemplo #1: Use la función TimedeltaIndex.drop_duplicates() para eliminar todo el valor duplicado del objeto TimedeltaIndex dado. Conservar sólo las primeras apariciones.
Python3
# importing pandas as pd import pandas as pd # Create the TimedeltaIndex object tidx = pd.TimedeltaIndex(data =['06:05:01.000030', '+23:59:59.999999', '22 day 2 min 3us 10ns', '+23:59:59.999999', '+23:29:59.999999', '+12:19:59.999999']) # Print the TimedeltaIndex object print(tidx)
Producción :

Ahora usaremos la función TimedeltaIndex.drop_duplicates() para eliminar todos los valores duplicados manteniendo la primera aparición.
Python3
# drop all duplicates and keep the first occurrence tidx.drop_duplicates(keep ='first')
Producción :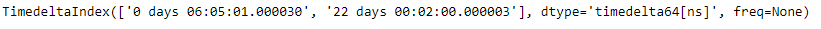
Como podemos ver en el resultado, la función TimedeltaIndex.drop_duplicates() ha devuelto un nuevo objeto que tiene todos los valores duplicados eliminados excepto la primera aparición.
Ejemplo #2: Use la función TimedeltaIndex.drop_duplicates() para eliminar todo el valor duplicado del objeto TimedeltaIndex dado. Mantenga el último valor duplicado.
Python3
# importing pandas as pd import pandas as pd # Create the TimedeltaIndex object tidx = pd.TimedeltaIndex(data =['1 days 02:00:00', '1 days 06:05:01.000030', '1 days 02:00:00', '1 days 02:00:00', '21 days 06:15:01.000030']) # Print the TimedeltaIndex object print(tidx)
Producción :

Ahora usaremos la función TimedeltaIndex.drop_duplicates() para eliminar todos los valores duplicados y mantener la última aparición.
Python3
# drop all duplicates and keep the first occurrence tidx.drop_duplicates(keep ='last')
Producción :

Como podemos ver en el resultado, la función TimedeltaIndex.drop_duplicates() ha devuelto un nuevo objeto que tiene todos los valores duplicados eliminados excepto la última aparición.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA