Seaborn es una biblioteca de visualización de datos de Python basada en matplotlib. Proporciona una interfaz de alto nivel para dibujar gráficos estadísticos atractivos e informativos. Seaborn ayuda a resolver los dos principales problemas que enfrenta Matplotlib; los problemas son?
- Parámetros predeterminados de Matplotlib
- Trabajar con marcos de datos
Como Seaborn complementa y amplía Matplotlib, la curva de aprendizaje es bastante gradual. Si conoce Matplotlib, ya está a la mitad de Seaborn. La biblioteca Seaborn ofrece muchas ventajas sobre otras bibliotecas de trazado:
- Es muy fácil de usar y requiere menos sintaxis de código.
- Funciona muy bien con estructuras de datos «pandas», que es justo lo que necesita como científico de datos.
- Está construido sobre Matplotlib, otra biblioteca de visualización de datos amplia y profunda.
Sintaxis: seaborn.catplot(*, x=Ninguno, y=Ninguno, hue=Ninguno, data=Ninguno, fila=Ninguno, col=Ninguno, kind=’strip’, e, palette=Ninguno, **kwargs)
Parámetros
- x, y, hue: nombres de variables en datos
Entradas para trazar datos de formato largo. Ver ejemplos para la interpretación.- data: DataFrame Conjunto de datos
de formato largo (ordenado) para trazar. Cada columna debe corresponder a una variable, y cada fila debe corresponder a una observación.- fila, columna: nombres de variables en datos, opcional
Variables categóricas que determinarán el facetado de la cuadrícula.- kind: str, opcional
El tipo de diagrama a dibujar, corresponde al nombre de una función de diagrama categórica a nivel de ejes. Las opciones son: “strip”, “swarm”, “box”, “violin”, “boxen”, “point”, “bar” o “count”.- color: matplotlib color, color opcional
para todos los elementos o semilla para una paleta de degradado.- paleta: nombre de paleta, lista o dictado
Colores a usar para los diferentes niveles de la variable de matiz. Debería ser algo que pueda ser interpretado por color_palette(), o un diccionario que mapee los niveles de tono a los colores matplotlib.- kwargs: emparejamientos de clave y valor
Otros argumentos de palabras clave se pasan a través de la función de trazado subyacente.
Ejemplos:
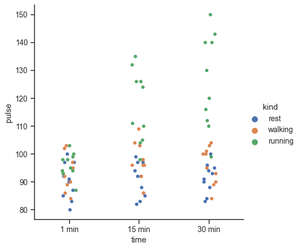
Si está trabajando con datos que involucran variables categóricas como respuestas de encuestas, sus mejores herramientas para visualizar y comparar diferentes características de sus datos serían gráficos categóricos. Trazar parcelas categóricas es muy fácil en seaborn. En este ejemplo, x,y y hue toman los nombres de las características de sus datos. Los parámetros de tono codifican los puntos con diferentes colores con respecto a la variable de destino.
Python3
import seaborn as sns
exercise = sns.load_dataset("exercise")
g = sns.catplot(x="time", y="pulse",
hue="kind",
data=exercise)
Producción:
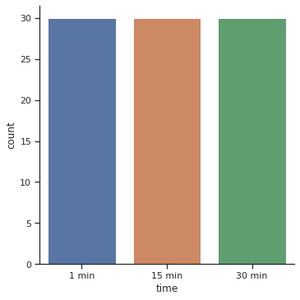
Para el gráfico de conteo, configuramos un parámetro de tipo para contar y alimentar los datos usando parámetros de datos. Comencemos explorando la función de tiempo. Comenzamos con la función catplot() y usamos el argumento x para especificar el eje que queremos mostrar en las categorías.
Python3
import seaborn as sns
sns.set_theme(style="ticks")
exercise = sns.load_dataset("exercise")
g = sns.catplot(x="time",
kind="count",
data=exercise)
Producción:
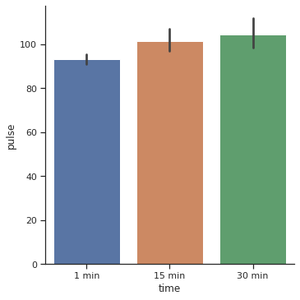
Otra opción popular para graficar datos categóricos es un gráfico de barras. En el ejemplo del diagrama de conteo, nuestro diagrama solo necesitaba una variable. En el gráfico de barras, a menudo usamos una variable categórica y una cuantitativa. Veamos cómo se compara el tiempo entre sí.
Python3
import seaborn as sns
exercise = sns.load_dataset("exercise")
g = sns.catplot(x="time",
y="pulse",
kind="bar",
data=exercise)
Producción:
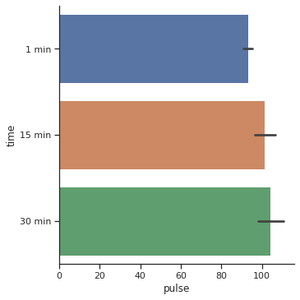
Para crear el gráfico de barras horizontales, tenemos que cambiar las funciones x e y. Cuando tiene muchas categorías o nombres de categoría largos, es una buena idea cambiar la orientación.
Python3
import seaborn as sns
exercise = sns.load_dataset("exercise")
g = sns.catplot(x="pulse",
y="time",
kind="bar",
data=exercise)
Producción:
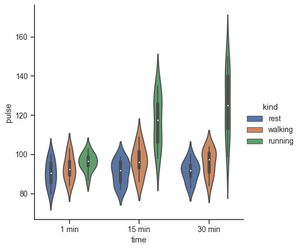
Use un tipo de gráfico diferente para visualizar los mismos datos:
Python3
import seaborn as sns
exercise = sns.load_dataset("exercise")
g = sns.catplot(x="time",
y="pulse",
hue="kind",
data=exercise,
kind="violin")
Producción:
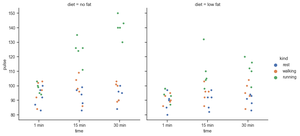
Python3
import seaborn as sns
exercise = sns.load_dataset("exercise")
g = sns.catplot(x="time",
y="pulse",
hue="kind",
col="diet",
data=exercise)
Producción:
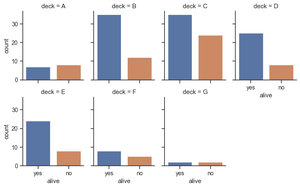
Haga muchas facetas de columna y envuélvalas en las filas de la cuadrícula. El aspecto cambiará el ancho mientras mantiene la altura constante.
Python3
titanic = sns.load_dataset("titanic")
g = sns.catplot(x="alive", col="deck", col_wrap=4,
data=titanic[titanic.deck.notnull()],
kind="count", height=2.5, aspect=.8)
Producción:
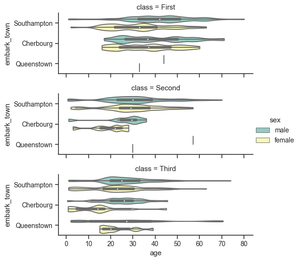
Traza horizontalmente y pasa otros argumentos de palabras clave a la función de trazado:
Python3
g = sns.catplot(x="age", y="embark_town", hue="sex", row="class", data=titanic[titanic.embark_town.notnull()], orient="h", height=2, aspect=3, palette="Set3", kind="violin", dodge=True, cut=0, bw=.2)
Producción:
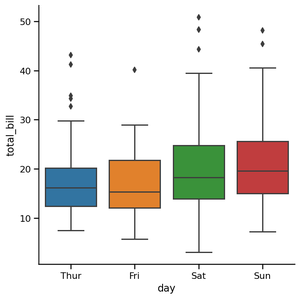
Los diagramas de caja son elementos visuales que pueden ser un poco difíciles de entender, pero representan la distribución de los datos de manera muy hermosa. Lo mejor es comenzar la explicación con un ejemplo de diagrama de caja. Voy a utilizar uno de los conjuntos de datos incorporados comunes en Seaborn:
Python3
tips = sns.load_dataset('tips')
sns.catplot(x='day',
y='total_bill',
data=tips,
kind='box');
Producción:
Detección de valores atípicos mediante diagrama de caja:
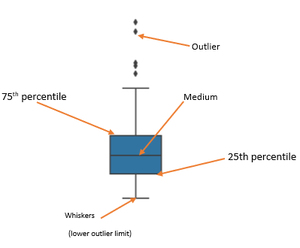
Los bordes de la caja azul son los percentiles 25 y 75 de la distribución de todas las facturas. Esto significa que el 75% de todos los billetes del jueves fueron inferiores a 20 dólares, mientras que otro 75% (de abajo hacia arriba) fue superior a casi 13 dólares. La línea horizontal en el cuadro muestra el valor mediano de la distribución.
- Encuentre el rango intercuartílico (RIC) restando el percentil 25 del 75: 75 % — 25 %
- El límite inferior de valores atípicos se calcula restando 1,5 veces el IQR del 25: 25 % — 1,5*IQR
- El límite superior de valores atípicos se calcula sumando 1,5 veces el IQR al 75: 75 % + 1,5*IQR
Publicación traducida automáticamente
Artículo escrito por vivekpisal12345 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA