Usando la biblioteca de Pandas, podemos realizar múltiples operaciones en un DataFrame. Incluso podemos crear y acceder al subconjunto de un DataFrame en múltiples formatos. La tarea aquí es crear un subconjunto DataFrame por nombre de columna. Podemos elegir diferentes métodos para realizar esta tarea. Estos son los métodos posibles que se mencionan a continuación:
Antes de realizar cualquier acción, debemos escribir algunas líneas de código para importar las bibliotecas necesarias y crear un DataFrame.
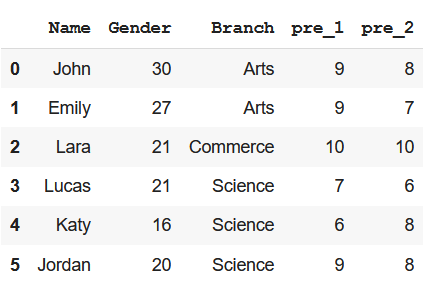
Crear el marco de datos
Python3
#import pandas
import pandas as pd
# create dataframe
data = {'Name': ['John', 'Emily', 'Lara', 'Lucas', 'Katy', 'Jordan'],
'Gender': [30, 27, 21, 21, 16, 20],
'Branch': ['Arts', 'Arts', 'Commerce', 'Science',
'Science', 'Science'],
'pre_1': [9, 9, 10, 7, 6, 9],
'pre_2': [8, 7, 10, 6, 8, 8]}
df = pd.DataFrame(data)
df
Producción:
Método 1: Usar la función iloc() de Python
Esta función nos permite crear un subconjunto eligiendo valores específicos de columnas basadas en índices.
Sintaxis:
df_name.iloc[beg_index:end_index+1,beg_index:end_index+1]
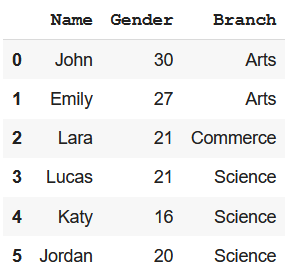
Ejemplo: Cree un subconjunto con la columna Nombre, Sexo y Rama
Python3
# create a subset of all rows # and Name, Gender and Branch column df.iloc[:, 0:3]
Producción :
Método 2: usar el operador de indexación
Podemos usar el operador de indexación, es decir, corchetes para crear un marco de datos de subconjunto
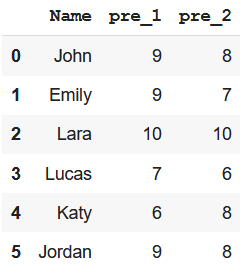
Ejemplo: crear un subconjunto con las columnas Nombre, pre_1 y pre_2
Python3
# creating subset dataframe using # indexing operator df[['Name', 'pre_1', 'pre_2']]
Producción –
Método 3: Usar el método filter() con la palabra clave similar
Podemos usar este método particularmente cuando tenemos que crear un marco de datos de subconjunto con columnas que tienen nombres con patrones similares.
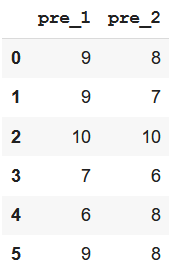
Ejemplo: crear un subconjunto con las columnas pre_1 y pre_2
Python3
# create a subset of columns pre_1 and pre_2 # using filter() method df.filter(like='pre')
Producción:
Publicación traducida automáticamente
Artículo escrito por devanshigupta1304 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA