ImageGrab y PyTesseract
ImageGrab es un módulo de Python que ayuda a capturar el contenido de la pantalla. PyTesseract es una herramienta de reconocimiento óptico de caracteres (OCR) para Python. Juntos se pueden usar para leer el contenido de una sección de la pantalla.
Instalación –
Pillow (una versión más nueva de PIL)
pip install PillowPyTesseract
pip install pytesseractAparte de esto, se debe instalar un ejecutable de tesseract .
Implementación de código
Las siguientes funciones se utilizaron principalmente en el código:
pytesseract.image_to_string(image, lang=**language**) – Toma la imagen y busca palabras del idioma en su texto.
cv2.cvtColor(imagen, **conversión de color**): se usa para hacer que la imagen sea monocromática (usando cv2.COLOR_BGR2GRAY).
ImageGrab.grab(bbox=**Coordenadas del área de la pantalla que se va a capturar**): se utiliza para capturar repetidamente (usando un bucle) una parte específica de la pantalla.
Los objetivos del código son:
- Usar un bucle para capturar repetidamente una parte de la pantalla.
- Para convertir la imagen capturada a escala de grises.
- Utilice PyTesseract para leer el texto que contiene.
Código: código de Python para usar ImageGrab y PyTesseract
# cv2.cvtColor takes a numpy ndarray as an argument import numpy as nm import pytesseract # importing OpenCV import cv2 from PIL import ImageGrab def imToString(): # Path of tesseract executable pytesseract.pytesseract.tesseract_cmd ='**Path to tesseract executable**' while(True): # ImageGrab-To capture the screen image in a loop. # Bbox used to capture a specific area. cap = ImageGrab.grab(bbox =(700, 300, 1400, 900)) # Converted the image to monochrome for it to be easily # read by the OCR and obtained the output String. tesstr = pytesseract.image_to_string( cv2.cvtColor(nm.array(cap), cv2.COLOR_BGR2GRAY), lang ='eng') print(tesstr) # Calling the function imToString()
Producción
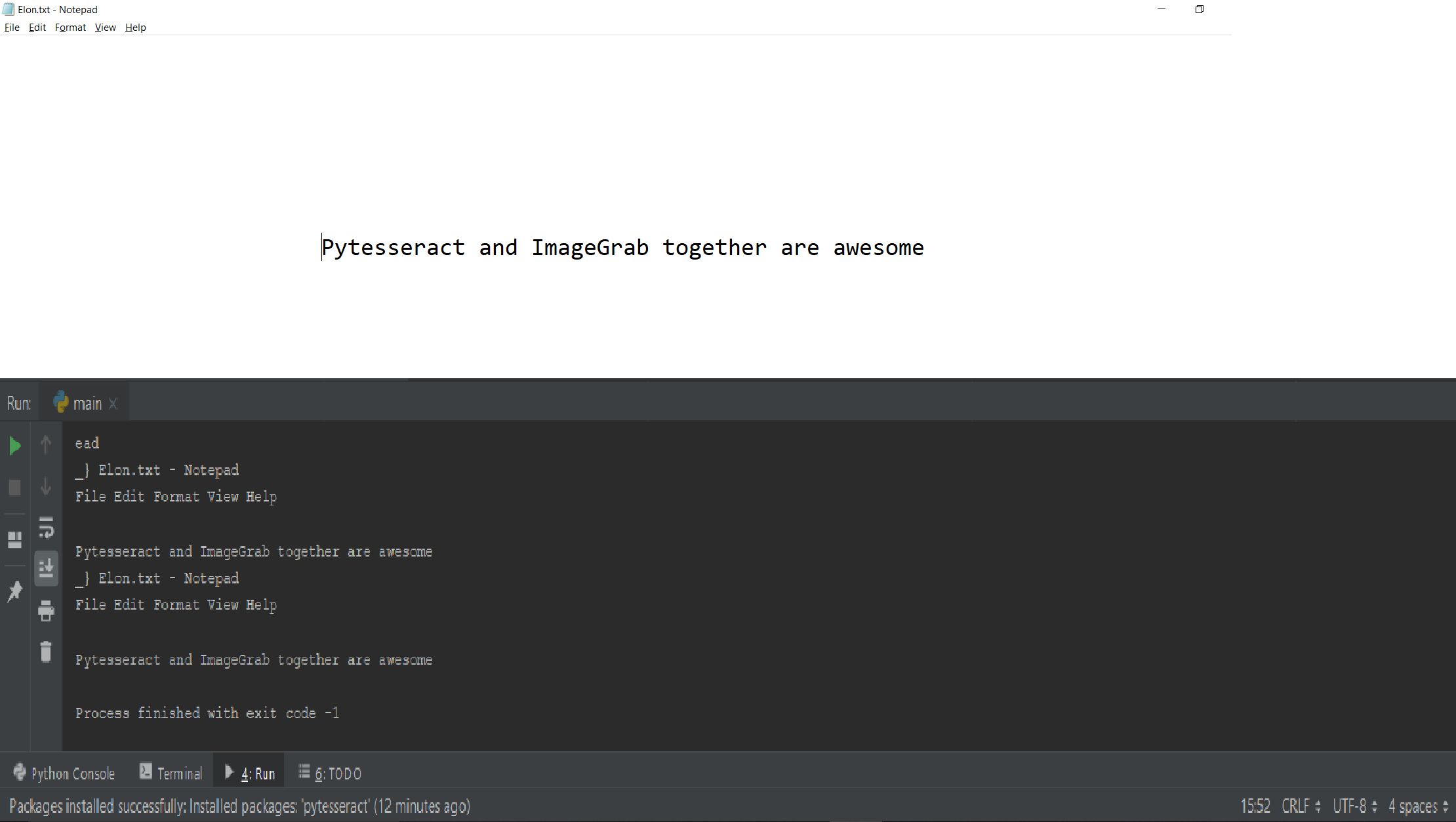
El código anterior se puede utilizar para capturar una determinada sección de la pantalla y leer el contenido de texto de la misma.