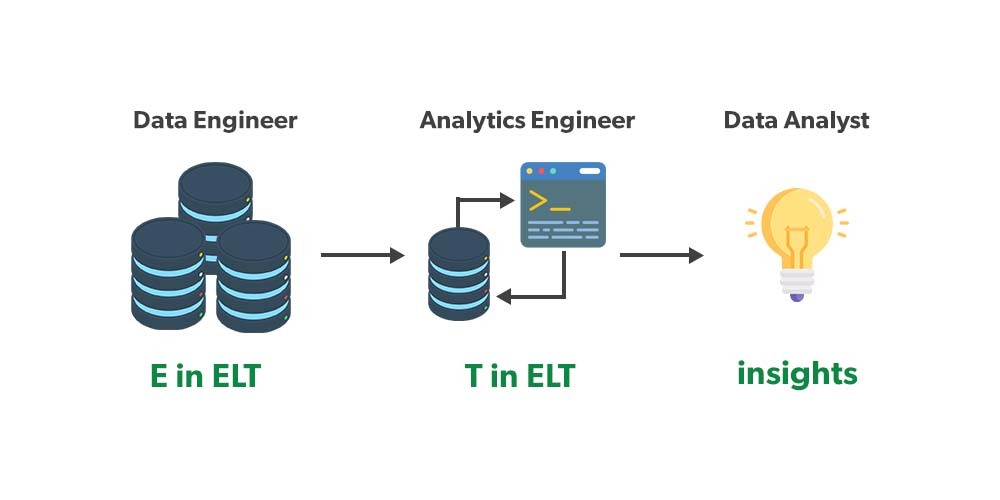
El dbt es una herramienta de conversión de código abierto que tiene como objetivo simplificar el trabajo del ingeniero analítico en el flujo de trabajo de canalización de datos. Específicamente usa solo T en el proceso ETL . La característica más importante es que se enfoca en implementar principios de software que son comunes no solo en la industria del software sino que ahora también se introducen en el mundo analítico.
Conceptos clave:
- Modelo: declaración de selección de SQL que toma las tablas como insertadas, modificadas y genera el resultado como una tabla.
- Paquete: un proyecto dbt que es un conjunto de tareas SQL.
- Fuente: la fuente es una tabla en el repositorio de datos donde comienza la conversión.
- Exposición: representación del uso de nivel inferior del proyecto dbt.
¿Por qué dbt?
En la mayoría de las canalizaciones de datos, el adjunto menos importante es el control de versiones, las pruebas y la documentación, mientras que este es un factor importante en el mantenimiento de una canalización. Se observan mejoras significativas en la gestión del tiempo cuando un error en el tablero se puede detectar rápidamente mediante una inspección exhaustiva y un gráfico de lista de datos en lugar de perder horas para encontrar el problema. La prueba será la primera en informar a los desarrolladores que algo ha fallado en lugar de que el cliente use el tablero para detectar que algo se ha apagado.
Usuarios objetivo:
- Dbt tiene dos versiones: dbt Cloud y dbt Command Line Interface (CLI). Si bien dbt Cloud tiene una interfaz de usuario que se encarga de algunas configuraciones y se puede ver una vista previa de los datos transformados, se deben aplicar los mismos comandos que en CLI a dbt Cloud. Debido a la falta de interfaz de usuario, dbt no es para analistas de negocios que prefieren usar herramientas y hacer planes lo más pequeños posible. Dbt es parte de una tecnología de transformación global enfocada en la transformación.
- Dbt es muy útil para grandes grupos de datos, ya que está diseñado para una función específica en el proceso de canalización de datos: un ingeniero analítico. Este es un nuevo rol especial para grandes grupos de datos que solo marcan la diferencia. Dbt se puede utilizar para satisfacer todas las necesidades de un ingeniero analítico. Otros roles, como ingeniero de datos y analista de datos, y el cuidado de la gestión del lago de datos, la extracción y la carga de datos en la base de datos y la información comercial.
Funcionalidades principales:
1. Documentación:
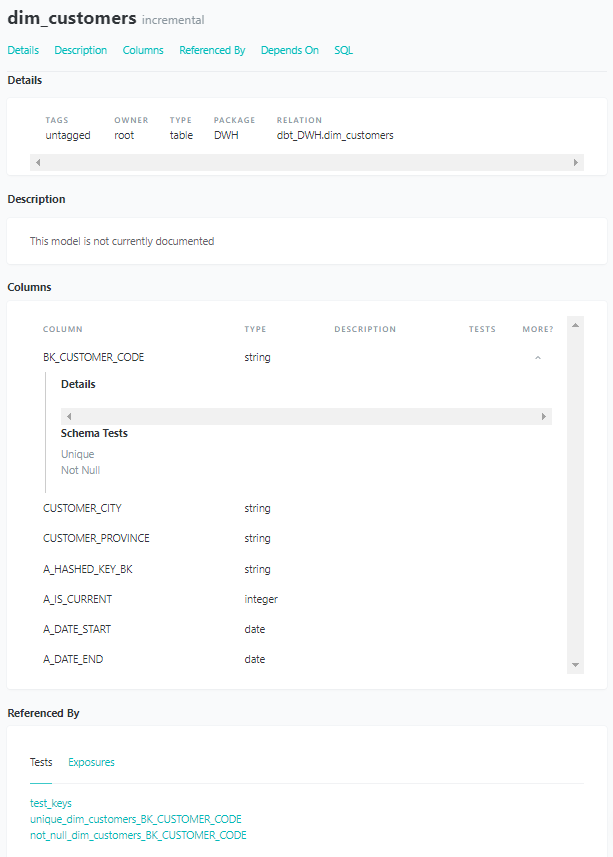
La documentación es esencial cuando se actualiza la canalización de datos con una nueva función o si otro desarrollador se hace cargo del proyecto. Los metadatos de las diferentes tablas y sus relaciones son extraídos por dbt y resumidos en una descripción general clara.
- Los diferentes modelos contienen información modificada sobre detalles específicos como tipo y paquete, descripción de la tabla, diferentes columnas con sus nombres, tipos y definiciones y qué pruebas están disponibles. Además, se pueden encontrar dependencias de otras tablas o referencias de otras tablas. Tanto el código fuente como el código combinado se almacenan aquí.
- Se incluyen diferentes paquetes con funcionalidad adicional. Nota: la comunidad de código abierto en dbt hub ya tiene muchas soluciones para problemas de análisis disponibles en paquetes.
- Se pueden especificar y documentar las fuentes donde se desarrolló el modelo de la primera etapa. Esta fuente, por ejemplo, sería una tabla Delta cargada con Databricks.
- Diferentes tableros usan tablas de hechos y tamaños, que se pueden especificar y definir en exposiciones. Tenga en cuenta que esto es solo una representación, los datos no fluirán automáticamente al tablero.
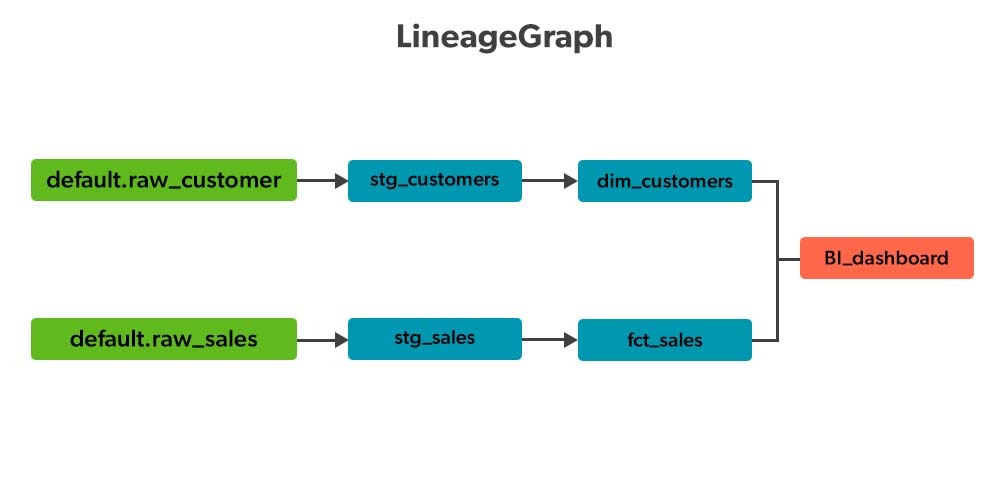
2. Linaje de datos:
El gráfico de linaje de datos es un factor importante para mostrar de dónde provienen sus datos y hacia dónde se dirigen. Muchos grupos de datos miran una lista de datos visuales para mostrar el flujo de datos desde la tabla de origen en el almacén de datos, a varias tablas después de la conversión, finalmente al tablero que brinda información sobre los datos.
3. Control de versiones:
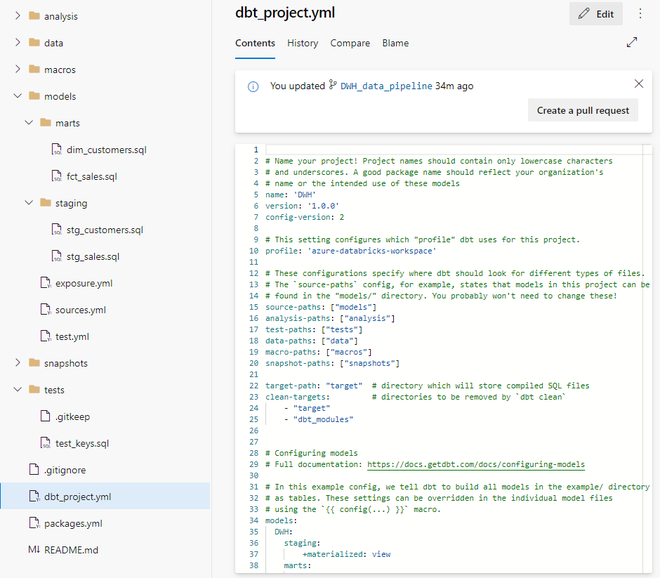
Control de versiones con git con un repositorio de git elegido para almacenar el código. Se versionan modelos, pruebas, exposiciones, fuentes, configuraciones del proyecto y los diferentes paquetes utilizados.
4. Transformaciones incrementales:
- La transformación incremental de los datos es necesaria para el manejo de big data.
- La tabla se puede configurar como incremental y se puede agregar algún código jinja para que el filtro se pueda aplicar solo a la ejecución incremental.
- Para evitar filas duplicadas, se puede establecer una clave única. Para no perder muchos datos con un corte estricto, se puede usar una ventana. Pero si los datos llegan después de la ventana de tiempo, los datos se perderán.
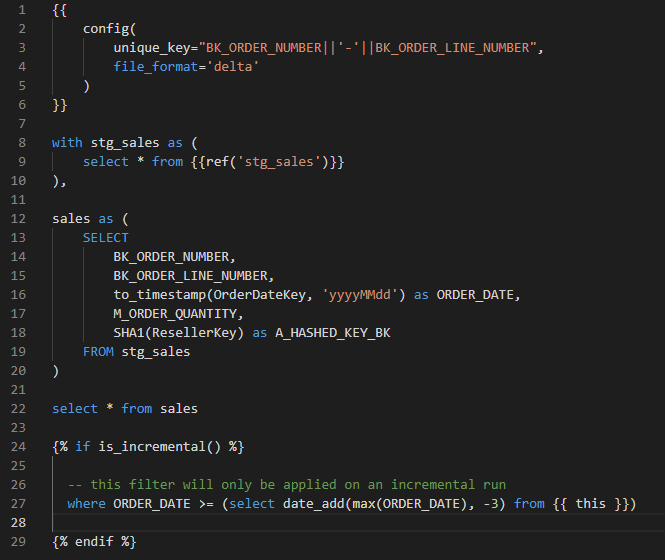
Cosas para recordar al usar la tabla incremental:
- Una columna que representa el tiempo o cuenta en la parte superior como una clave de serie.
- Una fila con una clave única o una combinación de filas que son únicas para evitar filas duplicadas.
- Cuando las actualizaciones se realizan en filas, una columna representa el momento en que se actualiza la fila para usar esta fila como el punto de corte donde se deben convertir los datos.
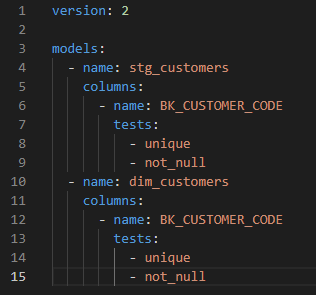
5. Pruebas:
Las pruebas son importantes para garantizar la calidad de los datos y la detección temprana de problemas. Dbt proporciona formas de integrar las pruebas en la canalización de datos. Algunas pruebas ya se enviaron en dbt, y algunas se pueden encontrar en el paquete de código abierto en dbt Hub.
Hay dos tipos de pruebas: pruebas a medida y pruebas genéricas
- Pruebas a medida: las pruebas a medida son una prueba medible que se puede reutilizar en diferentes modelos. Nota: el número de filas fallidas permitidas se puede establecer antes de dar un error. También es posible escribir filas fallidas en una tabla como referencia.
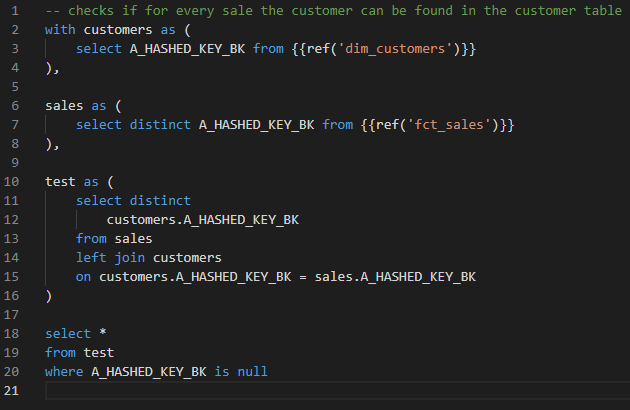
- Pruebas genéricas: las pruebas genéricas se prueban en ciertos modelos y, si no se devuelven las líneas, la prueba es exitosa. Se puede combinar cualquier número de tablas para probar una tabla específica.
Publicación traducida automáticamente
Artículo escrito por abhishekparida y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA