En el campo del procesamiento de imágenes, la compresión de imágenes es un paso importante antes de comenzar el procesamiento de imágenes o videos más grandes. La compresión de imágenes se lleva a cabo mediante un codificador y genera una forma comprimida de una imagen. En los procesos de compresión, las transformaciones matemáticas juegan un papel vital. Un diagrama de flujo del proceso de compresión de la imagen se puede representar como:

En este artículo, tratamos de explicar la descripción general de los conceptos involucrados en las técnicas de compresión de imágenes. La representación general de la imagen en una computadora es como un vector de píxeles. Cada píxel está representado por un número fijo de bits. Estos bits determinan la intensidad del color (en escala de grises si se trata de una imagen en blanco y negro y tiene tres canales de RGB si se trata de imágenes en color).
¿Por qué necesitamos compresión de imágenes?
Considere una imagen en blanco y negro que tiene una resolución de 1000*1000 y cada píxel usa 8 bits para representar la intensidad. Entonces, el número total de bits requeridos = 1000*1000*8 = 80,00,000 bits por imagen. Y considere si es un video con 30 fotogramas por segundo de las imágenes de tipo mencionadas anteriormente, entonces el total de bits para un video de 3 segundos es: 3*(30*(8, 000, 000))=720, 000, 000 pedacitos
Como vemos, solo para almacenar un video de 3 segundos necesitamos muchos bits, lo cual es muy grande. Por lo tanto, también necesitamos una forma de tener una representación adecuada para almacenar la información sobre la imagen en un número mínimo de bits sin perder el carácter de la imagen. Por lo tanto, la compresión de imágenes juega un papel importante.
Pasos básicos en la compresión de imágenes:
- Aplicando la transformación de imagen
- Cuantización de los niveles.
- Codificación de las secuencias.
Transformando la imagen
¿Qué es una transformación (matemáticamente):
Es una función que mapea de un dominio (espacio vectorial) a otro dominio (otro espacio vectorial). Suponga que T es una transformada, f(t):X->X’ es una función, entonces, T(f(t)) se llama la transformada de la función.
En un sentido simple, podemos decir que T cambia la forma (representación) de la función, ya que es un mapeo de un espacio vectorial a otro (sin cambiar la función básica f (t), es decir, la relación entre el dominio y co-dominio) .
Generalmente llevamos a cabo la transformación de la función de un espacio vectorial a otro porque cuando lo hacemos en el espacio vectorial recién proyectado inferimos más información sobre la función.
Un ejemplo de la vida real de una transformación:

Aquí podemos decir que el prisma es una función de transformación en la que divide la luz blanca (f(t)) en sus componentes, es decir, la representación de la luz blanca.
Y observamos que podemos inferir más información sobre la luz en su representación componente que la luz blanca. Así es como transforma ayuda en la comprensión de las funciones de una manera eficiente.
Transformaciones en el procesamiento de imágenes
La imagen también es una función de la ubicación de los píxeles. es decir, I(x, y) donde (x, y) son las coordenadas del píxel en la imagen. Entonces, generalmente transformamos una imagen del dominio espacial al dominio de frecuencia.
Por qué es importante la transformación de la imagen:
- Se vuelve fácil saber cuáles son todos los componentes principales que componen la imagen y ayudan en la representación comprimida.
- Facilita los cálculos.
- Ejemplo: encontrar la convolución en el dominio del tiempo antes de la transformación:
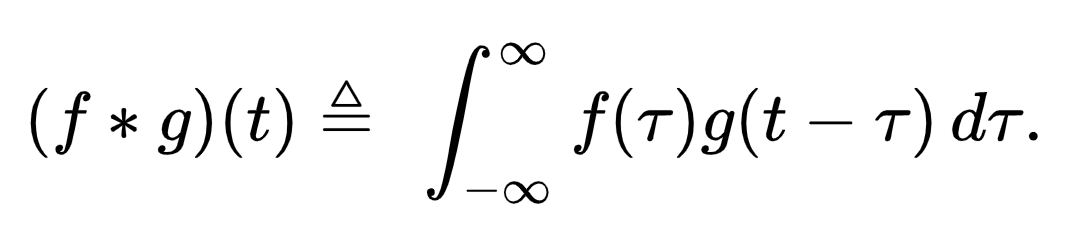
- Encontrar la convolución en el dominio de la frecuencia después de la transformación:
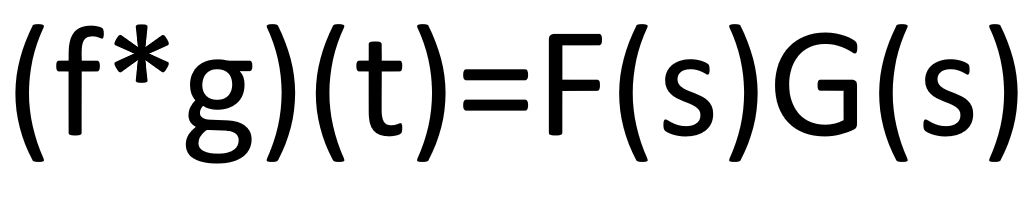
- Entonces podemos ver que el costo de cómputo se ha reducido a medida que cambiamos al dominio de la frecuencia. También podemos ver que en el dominio del tiempo la convolución era equivalente a un operador de integración pero en el dominio de la frecuencia se vuelve igual al producto simple de términos. Entonces, de esta manera se reduce el costo de cómputo.
Así, cuando transformamos la imagen de un dominio a otro, realizar las operaciones de filtrado espacial se vuelve más fácil.
cuantización
El proceso de cuantificación es un paso vital en el que los distintos niveles de intensidad se agrupan en un nivel particular basado en la función matemática definida en los píxeles. Generalmente, el nivel más nuevo se determina tomando un tamaño de filtro fijo de «m» y dividiendo cada uno de los términos «m» del filtro y redondeándolo al entero más cercano y multiplicando nuevamente por «m».
Función de cuantificación básica: [valor de píxel/m] * m
Por lo tanto, el valor de píxel más cercano se aproxima a un solo nivel, por lo tanto, el número de niveles distintos involucrados en la imagen se vuelve menor. Por lo tanto, reducimos la redundancia en el nivel de la intensidad. Entonces, la cuantización ayuda a reducir los distintos niveles.
Por ejemplo: (m=9)
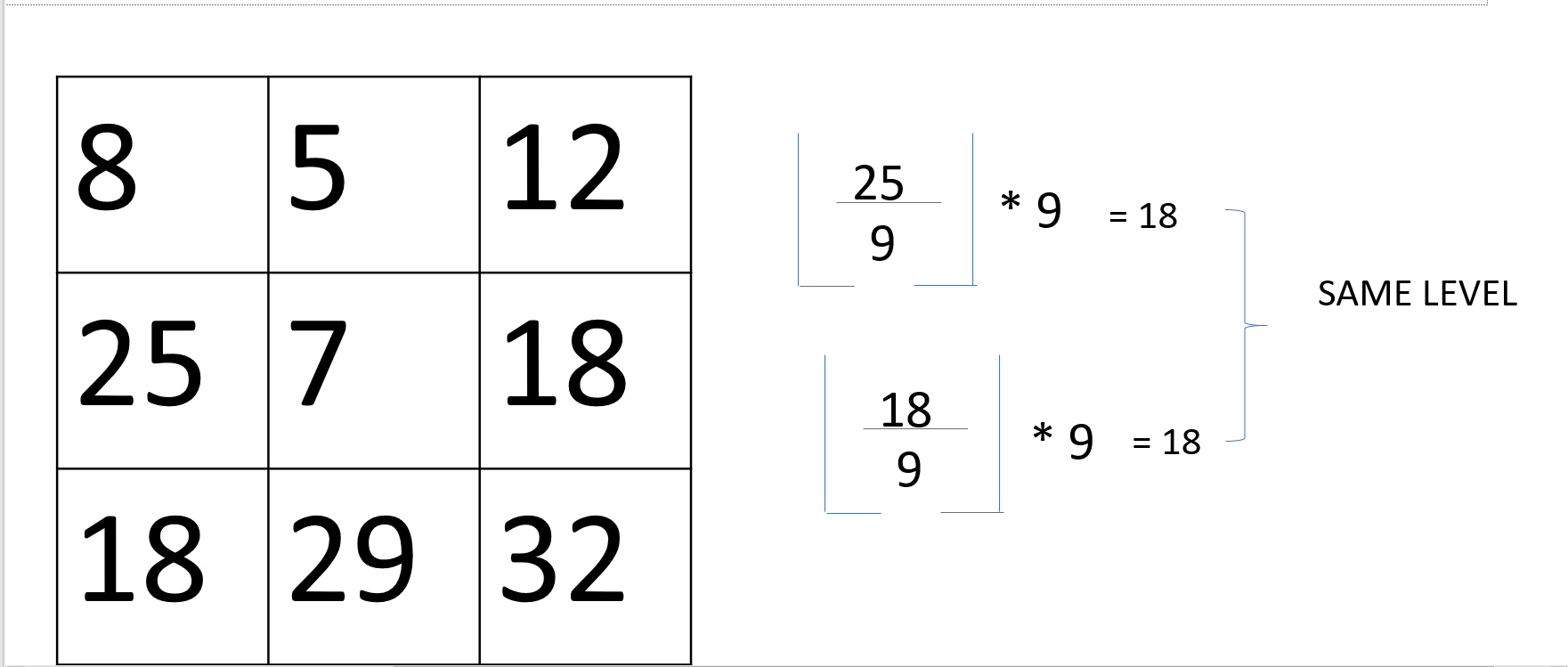
Por lo tanto, vemos en el ejemplo anterior que ambos valores de intensidad se redondean a 18, por lo que reducimos el número de niveles distintos (caracteres involucrados) en la especificación de la imagen.
Codificación de símbolos
La etapa del símbolo consiste en que los distintos caracteres que intervienen en la imagen se codifican de manera que el no. de bits necesarios para representar un carácter es óptimo en función de la frecuencia de aparición del carácter. En términos simples, en esta etapa se generan palabras clave para los diferentes personajes presentes. Al hacerlo, nuestro objetivo es reducir el no. de bits necesarios para representar los niveles de intensidad y representarlos en un número óptimo de bits.
Hay muchos algoritmos de codificación. Algunos de los más populares son:
- Codificación de longitud variable Huffman.
- Codificación de longitud de ejecución.
En el esquema de codificación de Huffman, tratamos de encontrar los códigos de tal manera que ninguno de los códigos sea el prefijo del otro. Y en función de la probabilidad de aparición del carácter, se determina la longitud del código. Para tener una solución óptima, el carácter más probable tiene el código de menor longitud.
Ejemplo:
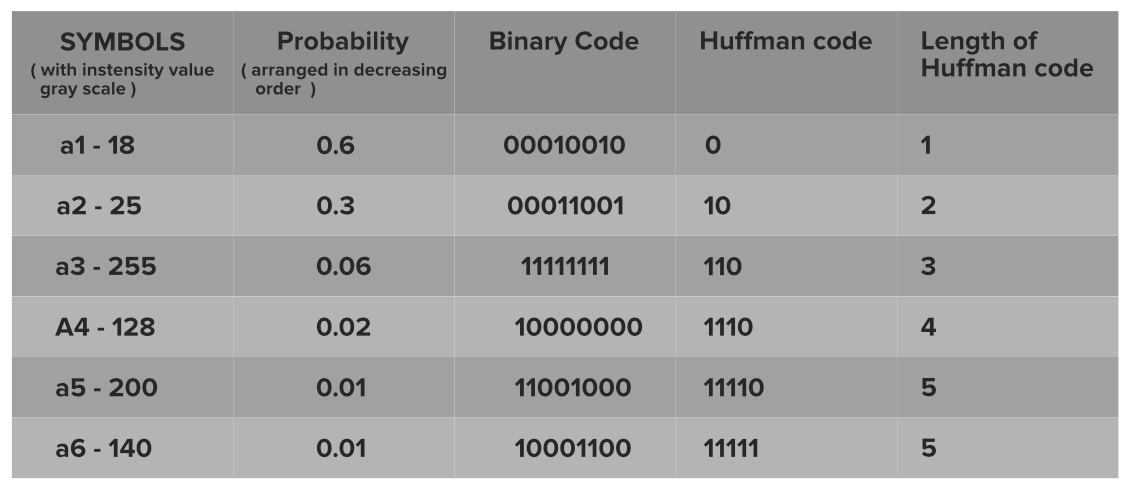
Vemos la representación real de 8 bits, así como los nuevos códigos de menor longitud. El mecanismo de generación de códigos es:
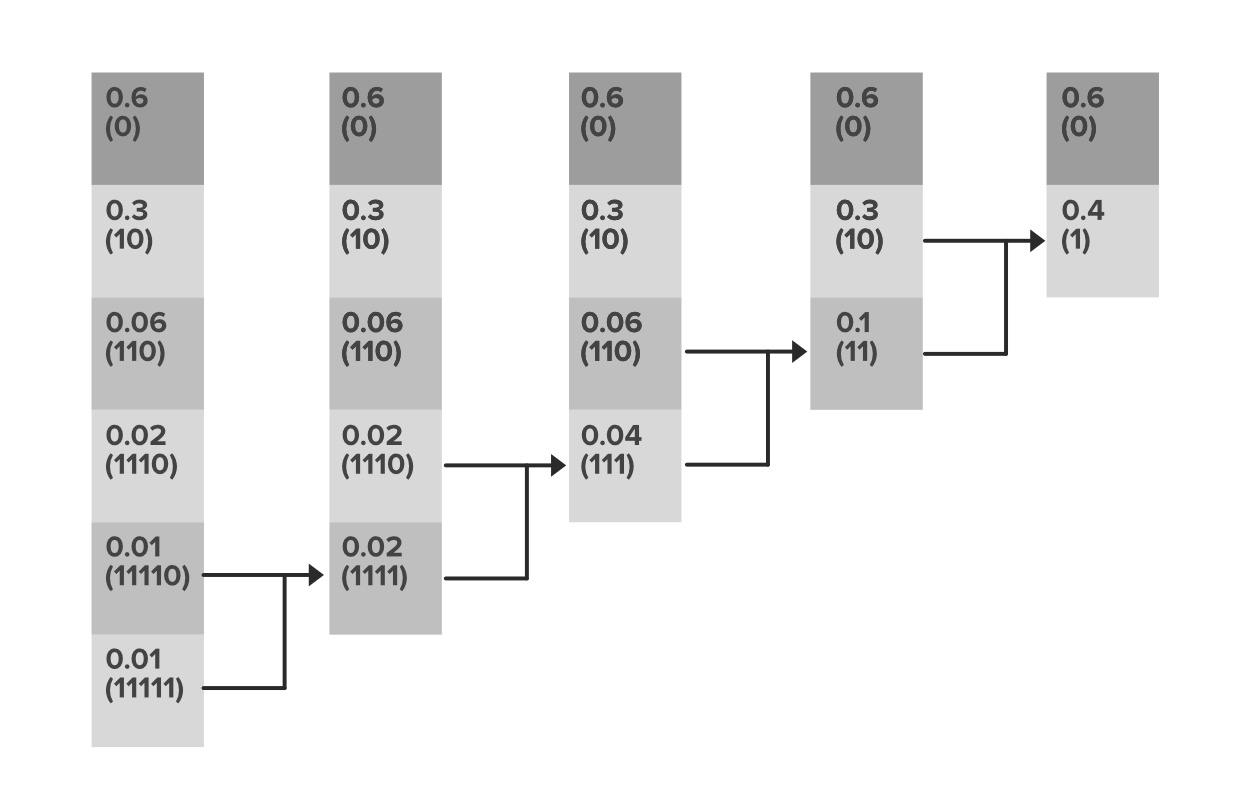
Entonces vemos cómo el requisito de almacenamiento para el número de bits se reduce como:
Representación inicial: longitud promedio del código: 8 bits por nivel de intensidad.
Después de la codificación: longitud promedio del código: (0,6*1)+(0,3*2)+(0,06*3)+(0,02*4)+(0,01*5)+(0,01*5)=1,56 bits por nivel de intensidad
Por lo tanto, el número de bits necesarios para representar la intensidad de los píxeles se reduce drásticamente.
Así, de esta manera, el mecanismo de cuantificación ayuda en la compresión. Una vez comprimidas las imágenes, es fácil almacenarlas en un dispositivo o transferirlas. Y en función del tipo de transformadas utilizadas, el tipo de cuantificación y el esquema de codificación, los decodificadores se diseñan en función de la lógica inversa de la compresión para que la imagen original pueda reconstruirse en función de los datos obtenidos de las imágenes comprimidas.
Publicación traducida automáticamente
Artículo escrito por srinidhi2810 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA