Cuando se trata de ciencia de datos en R , ¡los paquetes de Tidyverse son sus mejores amigos! Estos paquetes de Tidyverse se diseñaron especialmente para Data Science con una filosofía de diseño común. Incluyen todos los paquetes necesarios en el flujo de trabajo de la ciencia de datos, desde la exploración de datos hasta la visualización de datos. Por ejemplo, readr es para importar datos, tibble y tidyr ayudan a ordenar los datos, dplyr y stringr contribuyen a la transformación de datos y ggplot2 es vital para la visualización de datos.

Paquetes Tidyverse en R
Hay ocho paquetes principales de Tidyverse, a saber, ggplot2, dplyr, tidyr, readr, purrr, tibble, stringr y forcats que se mencionan en este artículo. Todos estos paquetes se cargan automáticamente a la vez con el comando install.packages(“tidyverse”). Además de estos paquetes, Tidyverse también tiene algunos paquetes especializados que no se cargan automáticamente pero necesitan su propia llamada. Estos incluyen el DBI para bases de datos relacionales. httr para API web, rvest para web scraping, etc. Ahora, veamos los paquetes principales de Tidyverse y aprendamos más sobre ellos.
Paquetes de Tidyverse en R siguientes:
- Visualización y exploración de datos
- ggplot2
- Gestión y transformación de datos
- dplyr
- ordenar
- cuerda
- gatos forzados
- Importación y gestión de datos
- tibble
- leer
- Programación funcional
- ronroneo
Visualización y exploración de datos
1. ggplot2 :
ggplot2 es una biblioteca de visualización de datos R que se basa en The Grammar of Graphics. ggplot2 puede crear visualizaciones de datos como gráficos de barras, gráficos circulares, histogramas, diagramas de dispersión, gráficos de error, etc. utilizando una API de alto nivel. También le permite agregar diferentes tipos de componentes o capas de visualización de datos en una sola visualización. Una vez que se le ha dicho a ggplot2 qué variables asignar a qué estética en la trama, hace el resto del trabajo para que el usuario pueda concentrarse en interpretar las visualizaciones y dedicar menos tiempo a crearlas. Pero esto también significa que no es posible crear gráficos altamente personalizados en ggplot2. Pero hay muchos recursos en la comunidad RStudio y Stack Overflow que pueden brindar ayuda en ggplot2 cuando sea necesario.
Si desea instalar ggplot2, el mejor método es instalar tidyverse usando:
install.packages("tidyverse")
O simplemente puede instalar ggplot2 usando:
install.packages("ggplot2")
También puede instalar la versión de desarrollo desde GitHub usando:
devtools::install_github("tidyverse/ggplot2")
Ejemplo:
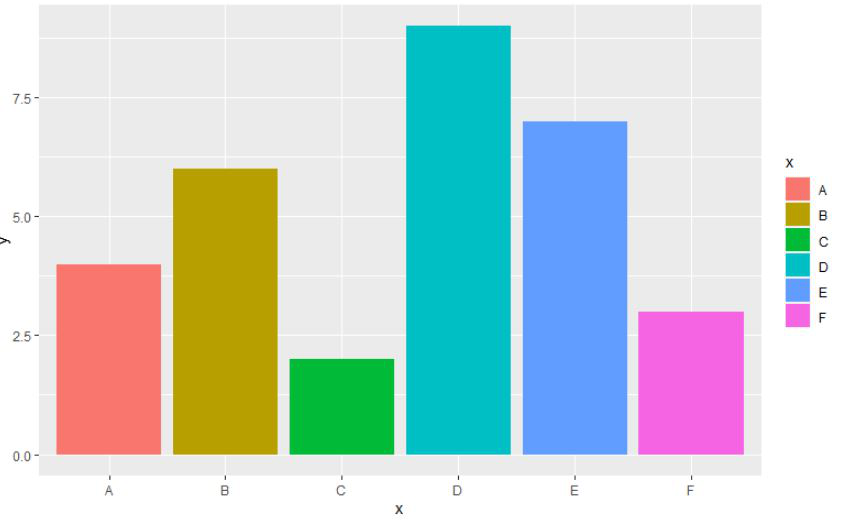
Usaremos 6 puntos de datos diferentes para el gráfico de barras y luego, con la ayuda del argumento de relleno dentro de la función aes, aplicaremos los colores predeterminados al gráfico de barras en el lenguaje de programación R.
R
# load the library
library("ggplot2")
# create the dataframe with letters and numbers
gfg < -data.frame(
x=c('A', 'B', 'C', 'D', 'E', 'F'),
y=c(4, 6, 2, 9, 7, 3))
# display the bar
ggplot(gfg, aes(x, y, fill=x)) + geom_bar(stat="identity")
Producción:
Gestión y transformación de datos
1. dplyr :
dplyr es una biblioteca de manipulación de datos muy popular en R. Tiene cinco funciones importantes que se combinan naturalmente con la función group_by() que puede ayudar a realizar estas funciones en grupos. Estas funciones incluyen la función mutate() que puede agregar nuevas variables que son funciones de variables existentes, la función select() que selecciona las variables según sus nombres, la función filter() que selecciona las variables según sus valores, summarise() función que reduce múltiples valores en un resumen, y la función de arreglar() que organiza el ordenamiento de las filas. Si desea instalar dplyr, el mejor método es instalar tidyverse usando:
install.packages("tidyverse")
O simplemente puede instalar dplyr usando:
install.packages("dplyr")
También puede instalar la versión de desarrollo desde GitHub usando:
devtools::install_github("tidyverse/dplyr")
Ejemplo:
R
library(dplyr) print(starwars %>% filter(species == "Droid"))
Producción:
# A tibble: 6 x 14 name height mass hair_color skin_color eye_color birth_year sex gender <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> 1 C-3PO 167 75 <NA> gold yellow 112 none masculi~ 2 R2-D2 96 32 <NA> white, blue red 33 none masculi~ 3 R5-D4 97 32 <NA> white, red red NA none masculi~ 4 IG-88 200 140 none metal red 15 none masculi~ 5 R4-P17 96 NA none silver, red red, blue NA none feminine 6 BB8 NA NA none none black NA none masculi~ # ... with 5 more variables: homeworld <chr>, species <chr>, films <list>, # vehicles <list>, starships <list>
2. ordenado :
tidyr es una biblioteca de limpieza de datos en R que ayuda a crear datos ordenados. Datos ordenados significa que todas las celdas de datos tienen un solo valor, siendo cada una de las columnas de datos una variable y las filas de datos una observación. Estos datos ordenados son un elemento básico en el tidyverse y garantiza que se dedique más tiempo al análisis de datos y a obtener valor de los datos en lugar de limpiar los datos continuamente y modificar las herramientas para manejar datos desordenados. Las funciones en tidyr se dividen en cinco categorías, a saber, Pivotar, que cambia los datos entre formas largas y anchas, Anidar, que cambia los datos agrupados para que un grupo sea una sola fila con un marco de datos anidado, Dividir columnas de caracteres y luego combinarlas, Rectangular que convierte listas anidadas en tibbles ordenados y convierte valores faltantes implícitos en valores explícitos. Si desea instalar tidyr,
install.packages("tidyverse")
O simplemente puede instalar tidyr usando:
install.packages("tidyr")
También puede instalar la versión de desarrollo desde GitHub usando:
devtools::install_github("tidyverse/tidyr")
Ejemplo:
La función de recopilación() en tidr tomará múltiples columnas y las colapsará en pares clave-valor, duplicando todas las demás columnas según sea necesario.
R
# load the tidyr package library(tidyr) n = 10 # creating a data frame tidy_dataframe = data.frame( S.No = c(1:n), Group.1 = c(23, 345, 76, 212, 88, 199, 72, 35, 90, 265), Group.2 = c(117, 89, 66, 334, 90, 101, 178, 233, 45, 200), Group.3 = c(29, 101, 239, 289, 176, 320, 89, 109, 199, 56)) # print the elements of the data frame print(head(tidy_dataframe)) # using gather() function on tidy_dataframe long <- tidy_dataframe %>% gather(Group, Frequency, Group.1:Group.3) # print the data frame in a long format print(head(long))
Producción:
S.No Group.1 Group.2 Group.3 1 1 23 117 29 2 2 345 89 101 3 3 76 66 239 4 4 212 334 289 5 5 88 90 176 6 6 199 101 320 S.No Group Frequency 1 1 Group.1 23 2 2 Group.1 345 3 3 Group.1 76 4 4 Group.1 212 5 5 Group.1 88 6 6 Group.1 199
3. Cuerda:
stringr es una biblioteca que tiene muchas funciones que se utilizan para tareas de limpieza y preparación de datos. También está diseñado para trabajar con strings y tiene muchas funciones que hacen que este sea un proceso fácil. stringr se basa en stringi, que es una biblioteca de componentes internacionales para Unicode C. Entonces, si hay alguna función que desea usar pero no puede encontrar en stringr, entonces el mejor lugar para buscarla es stringi. Esto también significa que una vez que dominas stringr, stringi no es tan difícil de usar ya que ambos paquetes tienen convenciones similares. Todas las funciones en stringr comienzan con str y toman un vector de string como su primer argumento. Algunas de estas funciones incluyen str_detect(), str_extract(), str_match(), str_count(), str_replace(), str_subset(), etc. Si desea instalar stringr,
install.packages("tidyverse")
O simplemente puede instalar stringr desde CRAN usando:
install.packages("stringr")
También puede instalar la versión de desarrollo desde GitHub usando:
devtools::install_github("tidyverse/stringr")
Ejemplo:
R
# R program for finding length of string
# Importing package
library(stringr)
# Calculating length of string
str_length("hello")
Producción:
5
4. Fortalezas:
forcats es una biblioteca de R que se ocupa del manejo de problemas asociados con los vectores. Estos vectores son variables que tienen un conjunto fijo de posibles valores que pueden tomar y que ya se conoce de antemano. Así que forecats se ocupa de cuestiones como cambiar el orden de los valores en los vectores, reordenar los vectores, etc. Algunas de las funciones en forecats son fct_relevel() que reordena los vectores a mano, fct_reorder() que reordena un factor usando otra variable, fct_infreq( ) que reordena un factor por valores de frecuencia, etc. Si desea instalar forcats, el mejor método es instalar tidyverse usando:
install.packages("tidyverse")
O simplemente puede instalar forcats usando:
install.packages("forcats")
También puede instalar la versión de desarrollo desde GitHub usando:
devtools::install_github("tidyverse/forcats")
Ejemplo:
R
library(forcats) library(dplyr) library(ggplot2) print(head(starwars %>% filter(!is.na(species)) %>% count(species, sort = TRUE)))
Producción:
# A tibble: 6 x 2 species n <chr> <int> 1 Human 35 2 Droid 6 3 Gungan 3 4 Kaminoan 2 5 Mirialan 2 6 Twi'lek 2
Importación y gestión de datos
1. leer:
Esta biblioteca proporciona un método simple y rápido para leer datos rectangulares como los que tienen formatos de archivo tsv, csv, delim, fwf, etc. readr puede analizar muchos tipos diferentes de datos usando una función que analiza el archivo total y otra que se enfoca en el columna específica. Esta especificación de columna define el método para convertir los datos de la columna de un vector de caracteres al tipo de datos más adecuado. Readr lo hace automáticamente en la mayoría de los casos. readr puede leer diferentes tipos de formatos de archivo utilizando diferentes funciones, a saber, read_csv() para archivos separados por comas, read_tsv() para archivos separados por tabuladores, read_table() para archivos tabulares, read_fwf() para archivos de ancho fijo, read_delim() para archivos delimitados y read_log() para archivos de registro web. Si desea instalar readr, el mejor método es instalar tidyverse usando:
install.packages("tidyverse").
O simplemente puede instalar readr usando:
install.packages("readr").
También puede instalar la versión de desarrollo desde GitHub usando:
devtools::install_github("tidyverse/readr")
Ejemplo:
Lectura de archivos con la biblioteca readr.
R
# R program to read text file
# using readr package
# Import the readr library
library(readr)
# Use read_tsv() to read text file
myData = read_tsv("geeksforgeeks.txt", col_names = FALSE)
print(myData)
Producción:
# A tibble: 1 x 1
X1
1 A computer science portal for geeks.
2. tibble:
Un tibble es una forma de marco de datos que incluye las partes útiles y descarta las partes que no son tan importantes. Por lo tanto, los tibbles no cambian los nombres o tipos de variables como data.frames ni hacen coincidencias parciales, pero traen problemas mucho antes, como cuando una variable no existe. Entonces, un código con tibbles es mucho más limpio y efectivo que antes. Tibbles también es más fácil de usar con conjuntos de datos más grandes que contienen objetos más complejos, en parte antes de un método print() mejorado. Puede crear nuevos tibbles a partir de vectores de columnas usando la función tibble() y también puede crear un tibble fila por fila usando la función tribble(). Si desea instalar tibble, el mejor método es instalar tidyverse usando:
install.packages("tidyverse"):
O simplemente puede instalar tibble usando:
install.packages("tibble")
También puede instalar la versión de desarrollo desde GitHub usando:
devtools::install_github("tidyverse/tibble")
Ejemplo:
R
library(tibble) data <- data.frame(a = 1:3, b = letters[1:3], c = Sys.Date() - 1:3) print(data)
Producción:
a b c 1 1 a 2021-11-24 2 2 b 2021-11-23 3 3 c 2021-11-22
Programación funcional
1. ronroneo:
Purrr es un conjunto detallado de herramientas para funciones y vectores y se usa principalmente para administrar la programación funcional en R. Un buen ejemplo de esto son las funciones map() que se usan para reemplazar múltiples bucles for que complican y estropean el código. inro código más simple que es fácil de leer. Además de eso, todas las funciones purrr son de tipo estable, lo que significa que devuelven el tipo de salida anunciado y, si eso no es posible, dan un error. Si desea instalar purrr, el mejor método es instalar tidyverse usando:
install.packages("tidyverse")
O simplemente puede instalar purrr usando:
install.packages("purrr")
También puede instalar la versión de desarrollo desde GitHub usando:
devtools::install_github("tidyverse/purrr")
Ejemplo:
R
library(purrr)
mtcars %>%
split(.$cyl) %>% # from base R
map(~ lm(mpg ~ wt, data = .)) %>%
map(summary) %>%
map_dbl("r.squared")
Producción:
4 0.50863259632314 6 0.464510150550548 8 0.422965536496112
Publicación traducida automáticamente
Artículo escrito por harkiran78 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA