Veamos cómo encontrar el rango percentil de una columna en un DataFrame de Pandas. Usaremos la rank()función con el argumento pct = Truepara encontrar el rango percentil.
Ejemplo 1 :
# import the module
import pandas as pd
# create a DataFrame
data = {'Name': ['Mukul', 'Rohan', 'Mayank',
'Shubham', 'Aakash'],
'Location' : ['Saharanpur', 'Meerut', 'Agra',
'Saharanpur', 'Meerut'],
'Pay' : [50000, 70000, 62000, 67000, 56000]}
df = pd.DataFrame(data)
# create a new column of percentile rank
df['Percentile Rank'] = df.Pay.rank(pct = True)
# displaying the percentile rank
display(df)
Producción :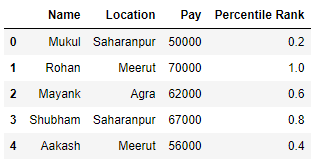
Ejemplo 2:
# import the module
import pandas as pd
# create a DataFrame
ODI_runs = {'name': ['Tendulkar', 'Sangakkara', 'Ponting',
'Jayasurya', 'Jayawardene', 'Kohli',
'Haq', 'Kallis', 'Ganguly', 'Dravid'],
'runs': [18426, 14234, 13704, 13430, 12650,
11867, 11739, 11579, 11363, 10889]}
df = pd.DataFrame(ODI_runs)
# create a new column of percentile rank
df['Percentile Rank'] = df.runs.rank(pct = True)
# displaying the percentile rank
display(df)
Producción :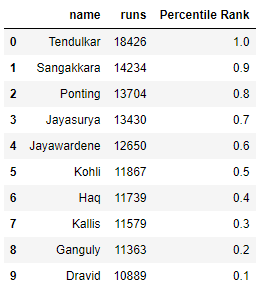
Publicación traducida automáticamente
Artículo escrito por mukulsomukesh y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA