Web Scraping es una poderosa herramienta para recopilar información de un sitio web. Para raspar varias URL, podemos usar una biblioteca de Python llamada Newspaper3k . El paquete Newspaper3k es una biblioteca de Python utilizada para artículos de Web Scraping. Está construido sobre requests y para analizar lxml . Este módulo es una versión mejorada y modificada del módulo Periódico que también se utiliza para el mismo propósito.
Instalación:
Para instalar este módulo, escriba el siguiente comando en la terminal.
pip install newspaper3k
Enfoque paso a paso:
- Primero definiremos una lista que contiene las URL o asignaremos una sola URL.
- Crearemos un objeto Article pasando parámetros como el nombre de la URL y parámetros opcionales como language=’en’, para inglés
- A continuación, descargaremos y analizaremos el archivo.
- Finalmente, muestre los datos extraídos.
A continuación se muestran algunos ejemplos basados en el enfoque anterior:
Ejemplo 1
A continuación se muestra un programa para desechar datos de una URL determinada.
Python3
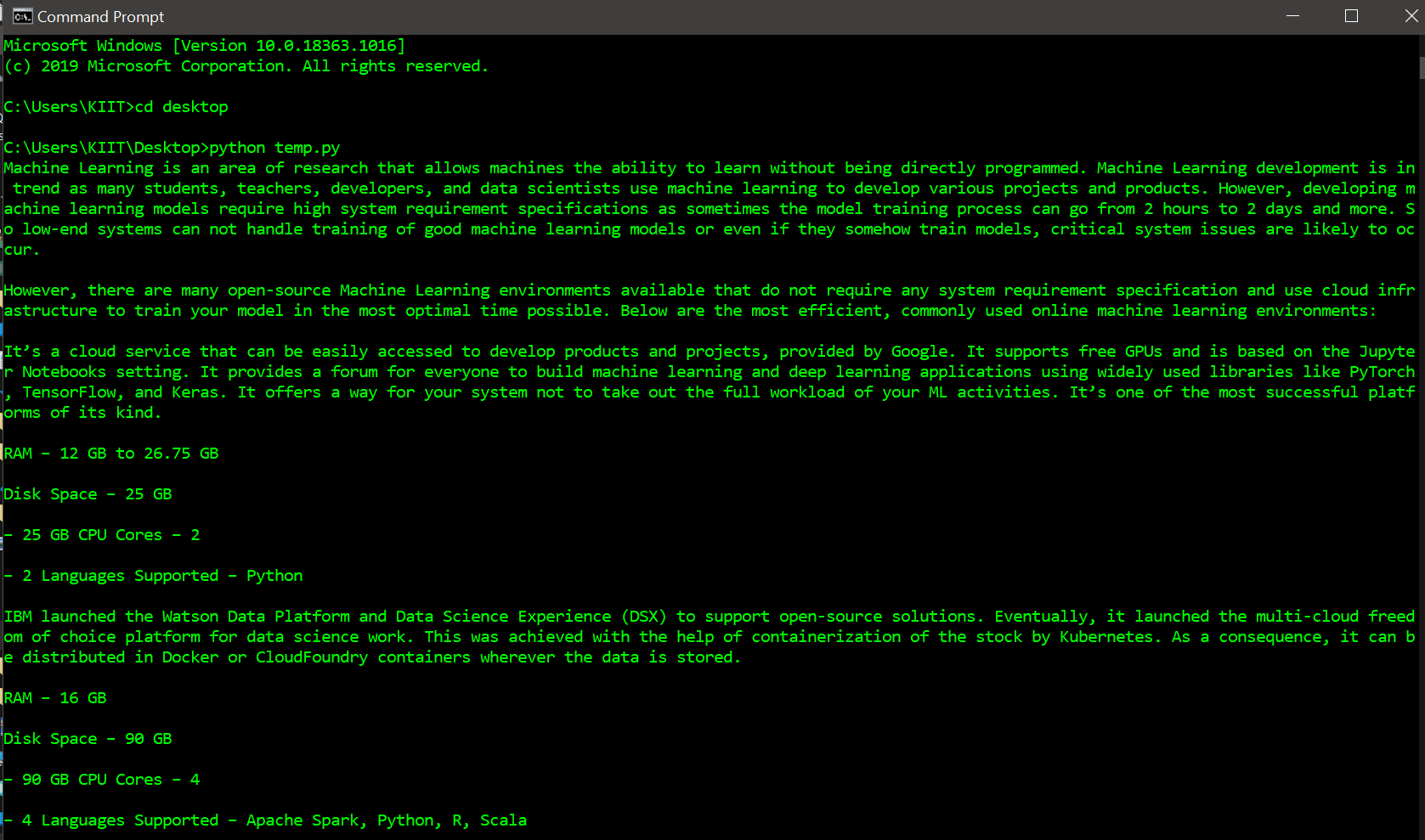
# Import required module import newspaper # Assign url url = 'https://www.geeksforgeeks.org/top-5-open-source-online-machine-learning-environments/' # Extract web data url_i = newspaper.Article(url="%s" % (url), language='en') url_i.download() url_i.parse() # Display scrapped data print(url_i.text)
Producción:
Ejemplo 2
Aquí, desechamos datos de varias URL y luego los mostramos.
Python3
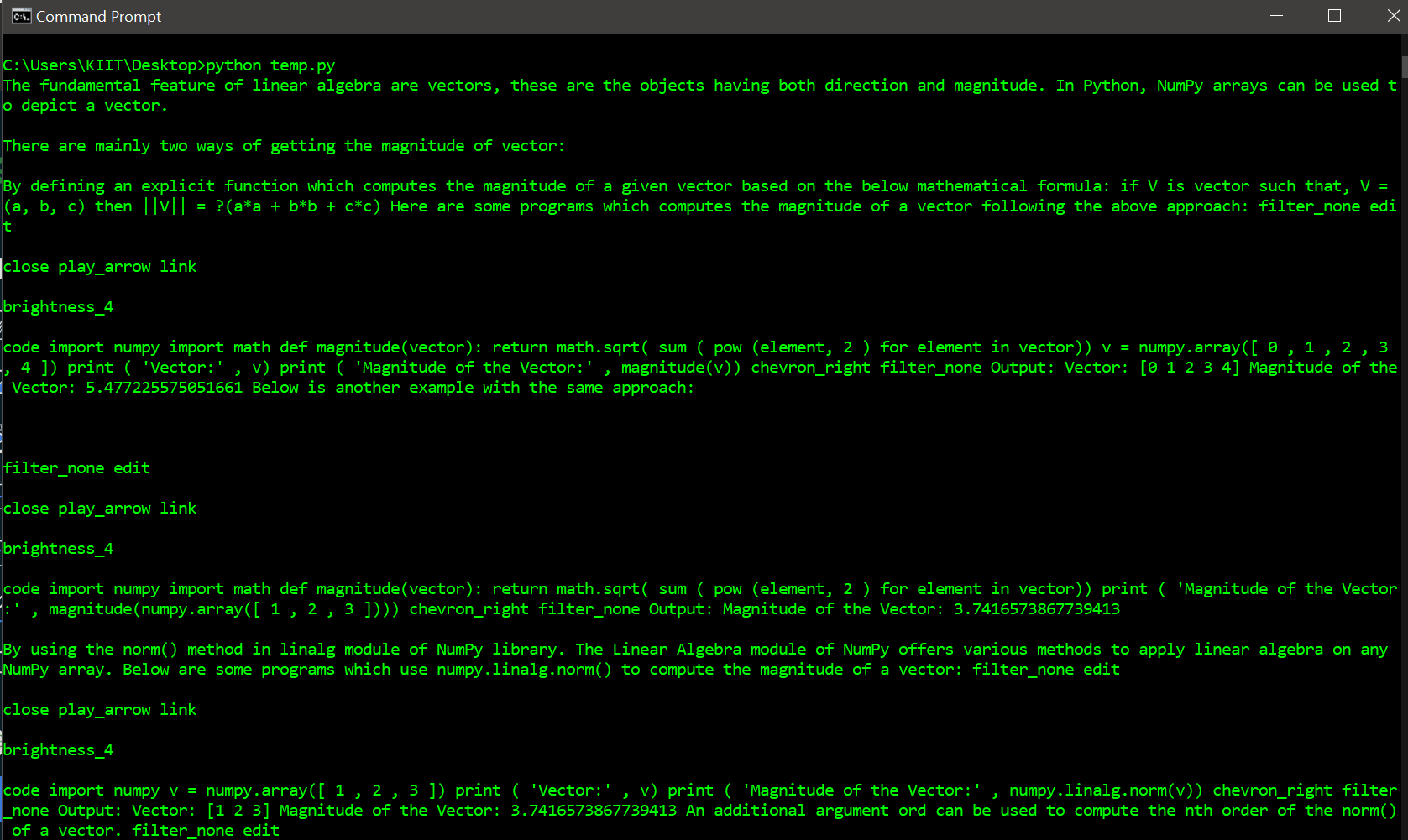
# Import required modules import newspaper # Define list of urls list_of_urls = ['https://www.geeksforgeeks.org/how-to-get-the-magnitude-of-a-vector-in-numpy/', 'https://www.geeksforgeeks.org/3d-wireframe-plotting-in-python-using-matplotlib/', 'https://www.geeksforgeeks.org/difference-between-small-data-and-big-data/'] # Parse through each url and display its content for url in list_of_urls: url_i = newspaper.Article(url="%s" % (url), language='en') url_i.download() url_i.parse() print(url_i.text)
Producción: