En este artículo vamos a ver cómo raspar Reddit con Python y BeautifulSoup. Aquí usaremos Beautiful Soup y el módulo de solicitud para raspar los datos.
Módulo necesario
- bs4 :Beautiful Soup (bs4) es una biblioteca de Python para extraer datos de archivos HTML y XML. Este módulo no viene integrado con Python. Para instalar este tipo, escriba el siguiente comando en la terminal.
pip install bs4
- requests :Request le permite enviar requests HTTP/1.1 de manera extremadamente fácil. Este módulo tampoco viene integrado con Python. Para instalar este tipo, escriba el siguiente comando en la terminal.
pip install requests
Acercarse:
- Importe todos los módulos necesarios.
- Pase la URL en la función getdata (UDF) a la que solicitará una URL, devuelve una respuesta. Estamos usando el método GET para recuperar información del servidor dado usando una URL dada.
Sintaxis: requests.get(url, argumentos)
- Ahora analice el contenido HTML usando bs4.
Sintaxis: sopa = BeautifulSoup(r.content, ‘html5lib’)
Parámetros:
- r.content : es el contenido HTML sin procesar.
- html.parser : especificando el analizador HTML que queremos usar.
- Ahora filtre los datos requeridos usando la función de sopa.Find_all.
Veamos la ejecución paso a paso del script.
Paso 1: importar todas las dependencias
Python3
# import module import requests from bs4 import BeautifulSoup
Paso 2: Cree una función de obtención de URL
Python3
# user define function # Scrape the data def getdata(url): r = requests.get(url, headers = HEADERS) return r.text
Paso 3: ahora tome la URL y pásela a la función getdata() y convierta esos datos en código HTML.
Python3
url = "https://www.reddit.com/r/learnpython/comments/78qnze/web_scraping_in_20_lines_of_code_with/" # pass the url # into getdata function htmldata = getdata(url) soup = BeautifulSoup(htmldata, 'html.parser') # display html code print(soup)
Producción:
Nota: Esto es solo código HTML o datos sin procesar.
Obtener el nombre del autor
Ahora busque autores con una etiqueta div donde class_ =”NAURX0ARMmhJ5eqxQrlQW”. Podemos abrir la página web en el navegador e inspeccionar el elemento relevante presionando el botón derecho como se muestra en la figura.
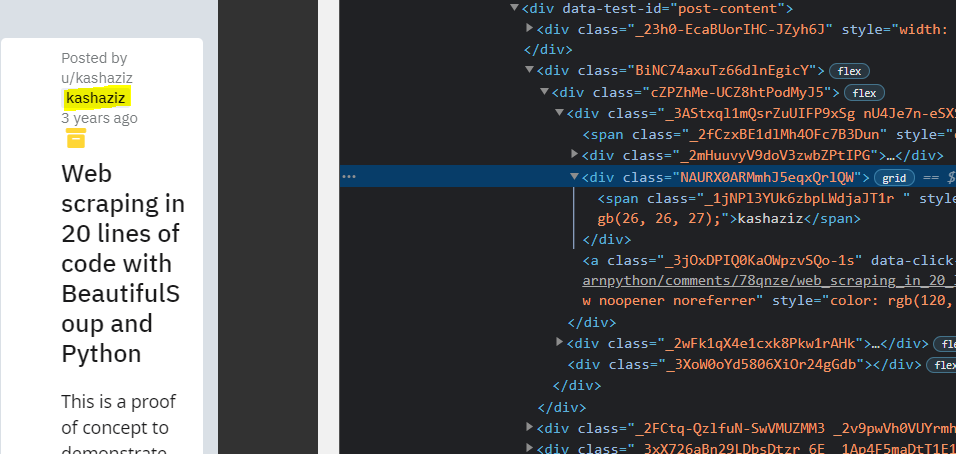
Ejemplo:
Python3
# find the Html tag
# with find()
# and convert into string
data_str = ""
for item in soup.find_all("div", class_="NAURX0ARMmhJ5eqxQrlQW"):
data_str = data_str + item.get_text()
print(data_str)
Producción:
kashaziz
Obtener el artículo contiene
Ahora busque el texto del artículo, aquí seguiremos los mismos métodos que en el ejemplo anterior.
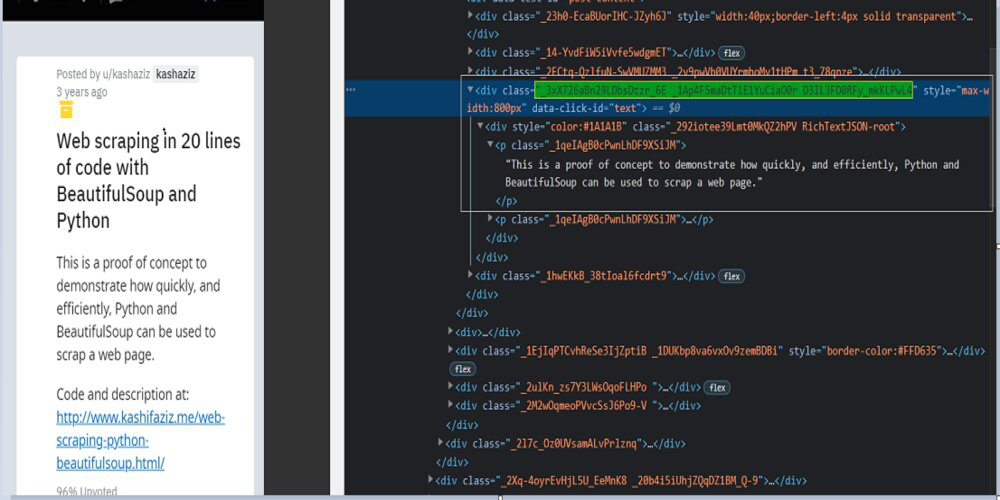
Ejemplo:
Python3
# find the Html tag
# with find()
# and convert into string
data_str = ""
result = ""
for item in soup.find_all("div", class_="_3xX726aBn29LDbsDtzr_6E _1Ap4F5maDtT1E1YuCiaO0r D3IL3FD0RFy_mkKLPwL4"):
data_str = data_str + item.get_text()
print(data_str)
Producción:

Obtener los comentarios
Ahora elimine los comentarios, aquí seguiremos los mismos métodos que en el ejemplo anterior.
Python3
# find the Html tag
# with find()
# and convert into string
data_str = ""
for item in soup.find_all("p", class_="_1qeIAgB0cPwnLhDF9XSiJM"):
data_str = data_str + item.get_text()
print(data_str)
Producción:

Publicación traducida automáticamente
Artículo escrito por kumar_satyam y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA