Podemos raspar las clasificaciones de películas de IMDb y sus detalles con la ayuda de la biblioteca BeautifulSoup de Python.
Módulos necesarios:
A continuación se muestra la lista de módulos necesarios para raspar de IMDB.
- requests : la biblioteca de requests es una parte integral de Python para realizar requests HTTP a una URL específica. Ya sea que se trate de API REST o Web Scrapping, las requests deben aprenderse para continuar con estas tecnologías. Cuando uno realiza una solicitud a un URI, devuelve una respuesta.
- html5lib : una biblioteca de Python puro para analizar HTML. Está diseñado para cumplir con la especificación HTML de WHATWG, tal como lo implementan los principales navegadores web.
- bs4 : Beautiful Soup proporciona el objeto BeautifulSoup, que es un marco de web scraping para Python. El raspado web es el proceso de extracción de datos del sitio web utilizando herramientas automatizadas para acelerar el proceso.
- pandas : Pandas es una biblioteca creada sobre la biblioteca NumPy que proporciona varias estructuras de datos y operadores para manipular los datos numéricos.
Acercarse:
Pasos para implementar web scraping en python para extraer calificaciones de películas de IMDb y sus calificaciones:
- Importe los módulos requeridos.
Python3
from bs4 import BeautifulSoup import requests import re import pandas as pd
- Acceda al contenido HTML desde la página web asignando la URL y creando un objeto SOAP.
Python3
# Downloading imdb top 250 movie's data url = 'http://www.imdb.com/chart/top' response = requests.get(url) soup = BeautifulSoup(response.text, "html.parser")
- Extraiga las clasificaciones de películas y sus detalles. Aquí, estamos extrayendo datos del objeto BeautifulSoup usando etiquetas Html como href, título, etc.
Python3
movies = soup.select('td.titleColumn')
crew = [a.attrs.get('title') for a in soup.select('td.titleColumn a')]
ratings = [b.attrs.get('data-value')
for b in soup.select('td.posterColumn span[name=ir]')]
- Después de extraer los detalles de la película, cree una lista vacía y almacene los detalles en un diccionario y luego agréguelos a una lista.
Python3
# create a empty list for storing
# movie information
list = []
# Iterating over movies to extract
# each movie's details
for index in range(0, len(movies)):
# Separating movie into: 'place',
# 'title', 'year'
movie_string = movies[index].get_text()
movie = (' '.join(movie_string.split()).replace('.', ''))
movie_title = movie[len(str(index))+1:-7]
year = re.search('\((.*?)\)', movie_string).group(1)
place = movie[:len(str(index))-(len(movie))]
data = {"place": place,
"movie_title": movie_title,
"rating": ratings[index],
"year": year,
"star_cast": crew[index],
}
list.append(data)
- Ahora o la lista está llena de las mejores películas de IMBD junto con sus detalles. Luego muestra la lista de detalles de la película.
Python3
for movie in list:
print(movie['place'], '-', movie['movie_title'], '('+movie['year'] +
') -', 'Starring:', movie['star_cast'], movie['rating'])
- Al usar las siguientes líneas de código, los mismos datos se pueden guardar en un archivo .csv y se pueden usar más como un conjunto de datos.
Python3
#saving the list as dataframe
#then converting into .csv file
df = pd.DataFrame(list)
df.to_csv('imdb_top_250_movies.csv',index=False)
Implementación: Código Completo
Python3
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
# Downloading imdb top 250 movie's data
url = 'http://www.imdb.com/chart/top'
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
movies = soup.select('td.titleColumn')
crew = [a.attrs.get('title') for a in soup.select('td.titleColumn a')]
ratings = [b.attrs.get('data-value')
for b in soup.select('td.posterColumn span[name=ir]')]
# create a empty list for storing
# movie information
list = []
# Iterating over movies to extract
# each movie's details
for index in range(0, len(movies)):
# Separating movie into: 'place',
# 'title', 'year'
movie_string = movies[index].get_text()
movie = (' '.join(movie_string.split()).replace('.', ''))
movie_title = movie[len(str(index))+1:-7]
year = re.search('\((.*?)\)', movie_string).group(1)
place = movie[:len(str(index))-(len(movie))]
data = {"place": place,
"movie_title": movie_title,
"rating": ratings[index],
"year": year,
"star_cast": crew[index],
}
list.append(data)
# printing movie details with its rating.
for movie in list:
print(movie['place'], '-', movie['movie_title'], '('+movie['year'] +
') -', 'Starring:', movie['star_cast'], movie['rating'])
##.......##
df = pd.DataFrame(list)
df.to_csv('imdb_top_250_movies.csv',index=False)
Producción:

Junto con esto en la terminal, se guarda un archivo .csv con un nombre dado en el mismo archivo y los datos en el archivo .csv serán como se muestra en la siguiente imagen.
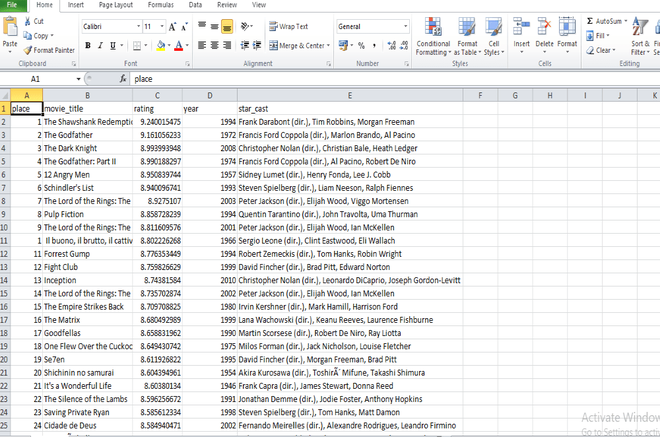
Publicación traducida automáticamente
Artículo escrito por Priyank181 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA