Existen principalmente dos formas de extraer datos de un sitio web:
- Utilice la API del sitio web (si existe). Por ejemplo, Facebook tiene la API Graph de Facebook que permite la recuperación de datos publicados en Facebook.
- Acceda al HTML de la página web y extraiga información/datos útiles de ella. Esta técnica se llama raspado web o recolección web o extracción de datos web.
En este artículo, usaremos la API de newsapi. Puede crear su propia clave de API haciendo clic aquí .
Ejemplos: Determinemos la preocupación de una personalidad como el presidente de un estado citado por los periódicos, tomemos el caso de MERKEL
import pprint
import requests
secret = "Your API"
# Define the endpoint
url = 'https://newsapi.org/v2/everything?'
# Specify the query and
# number of returns
parameters = {
'q': 'merkel', # query phrase
'pageSize': 100, # maximum is 100
'apiKey': secret # your own API key
}
# Make the request
response = requests.get(url,
params = parameters)
# Convert the response to
# JSON format and pretty print it
response_json = response.json()
pprint.pprint(response_json)
Producción:
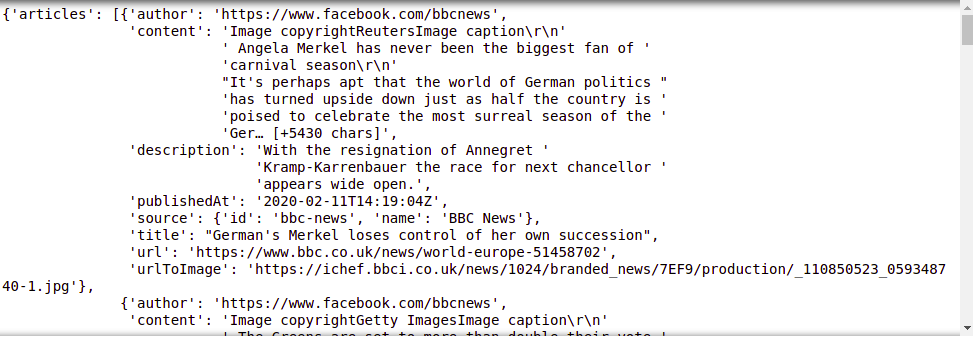
Combinemos todos los textos y ordenemos las palabras del mayor número al menor.
from wordcloud import WordCloud
import matplotlib.pyplot as plt
text_combined = ''
for i in response_json['articles']:
if i['description'] != None:
text_combined += i['description'] + ' '
wordcount={}
for word in text_combined.split():
if word not in wordcount:
wordcount[word] = 1
else:
wordcount[word] += 1
for k,v, in sorted(wordcount.items(),
key=lambda words: words[1],
reverse = True):
print(k,v)
Producción:

Esta evaluación es ambigua, podemos aclararla si eliminamos las palabras malas o inútiles. Definamos algunas de las malas_palabras que se muestran a continuación
bad_words = [“a”, “the”, “of”, “in”, “to”, “and”, “on”, “de”, “with”,
“by”, “at”, “dans” , “ont”, “été”, “les”, “des”, “au”, “et”,
“après”, “avec”, “qui”, “par”, “leurs”, “ils”, “ a”, “pour”,
“les”, “on”, “as”, “france”, “eux”, “où”, “son”, “le”, “la”,
“en”, “with” , “es”, “tiene”, “por”, “eso”, “un”, “pero”, “ser”,
“son”, “du”, “eso”, “à”, “tenía”, “ ist”, “Der”, “um”, “zu”, “den”,
“der”, “-“, “und”, “für”, “Die”, “von”, “als”,
“sich” , “nicht”, “nach”, “auch”]
Ahora podemos eliminar y formatear el texto eliminando malas palabras
# initializing bad_chars_list
bad_words = ["a", "the" , "of", "in", "to", "and", "on", "de", "with",
"by", "at", "dans", "ont", "été", "les", "des", "au", "et",
"après", "avec", "qui", "par", "leurs", "ils", "a", "pour",
"les", "on", "as", "france", "eux", "où", "son", "le", "la",
"en", "with", "is", "has", "for", "that", "an", "but", "be",
"are", "du", "it", "à", "had", "ist", "Der", "um", "zu", "den",
"der", "-", "und", "für", "Die", "von", "als",
"sich", "nicht", "nach", "auch" ]
r = text_combined.replace('\s+',
' ').replace(',',
' ').replace('.',
' ')
words = r.split()
rst = [word for word in words if
( word.lower() not in bad_words
and len(word) > 3) ]
rst = ' '.join(rst)
wordcount={}
for word in rst.split():
if word not in wordcount:
wordcount[word] = 1
else:
wordcount[word] += 1
for k,v, in sorted(wordcount.items(),
key=lambda words: words[1],
reverse = True):
print(k,v)
Producción:

Tracemos la salida
word = WordCloud(max_font_size = 40).generate(rst)
plt.figure()
plt.imshow(word, interpolation ="bilinear")
plt.axis("off")
plt.show()
Producción:

Como puede ver en las descripciones de los artículos, la preocupación más dominante con Merkel es su ministra de defensa, Kramp-Karrenbauer, Kanzlerin solo significa canciller. Podemos hacer el mismo trabajo usando solo títulos
title_combined = ''
for i in response_json['articles']:
title_combined += i['title'] + ' '
titles = title_combined.replace('\s+',
' ').replace(',',
' ').replace('.',
' ')
words_t = titles.split()
result = [word for word in words_t if
( word.lower() not in bad_words and
len(word) > 3) ]
result = ' '.join(result)
wordcount={}
for word in result.split():
if word not in wordcount:
wordcount[word] = 1
else:
wordcount[word] += 1
word = WordCloud(max_font_size=40).generate(result)
plt.figure()
plt.imshow(word, interpolation="bilinear")
plt.axis("off")
plt.show()
Producción:

A partir de los títulos, descubrimos que la mayor preocupación con Merkel es Ardogan, presidente de Turquía.
Publicación traducida automáticamente
Artículo escrito por boularouksaid y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA