Aprenderás sobre el Reconocimiento automático de matrículas. Usaremos el motor de reconocimiento óptico de caracteres (OCR Engine) Tesseract OCR para reconocer automáticamente el texto en las placas de matrícula del vehículo.
Python-tesseract:
Py-tesseract es una herramienta de reconocimiento óptico de caracteres (OCR) para python. Es decir, reconocerá y “leerá” el texto incrustado en las imágenes. Python-tesseract es un contenedor para el motor Tesseract-OCR de Google. También se usa como secuencia de comandos individual, ya que puede leer todo tipo de imágenes como jpeg, png, gif, bmp, tiff, etc. Además, si se usa como secuencia de comandos, Python-tesseract imprimirá el texto reconocido en lugar de escribirlo en un archivo. Tiene la capacidad de reconocer más de 100 idiomas.
Instalación:
pip install pytesseract
OpenCV:
OpenCV es una biblioteca de visión por computadora de código abierto. La biblioteca tiene más de 2500 algoritmos optimizados. Estos algoritmos se utilizan a menudo para buscar y reconocer rostros, identificar objetos, reconocer escenarios y generar marcadores para superponer imágenes mediante realidad aumentada, etc.
Instalación:
pip install opencv-python
Nota: asegúrese de haber instalado correctamente los módulos pytesseract y OpenCV-python
Nota: debe tener el conjunto de datos listo y todas las imágenes deben ser como se muestra a continuación en las técnicas de procesamiento de imágenes para un mejor rendimiento; La carpeta del conjunto de datos debe estar en la misma carpeta en la que está escribiendo este código Python o tendrá que especificar la ruta al conjunto de datos manualmente donde sea necesario.
Procedimiento:
# Loading the required python modules import pytesseract # this is tesseract module import matplotlib.pyplot as plt import cv2 # this is opencv module import glob import os
Nota: el nombre de los archivos de imagen debe ser el número exacto en la imagen de la matrícula respectiva. ejemplo: si tiene una matrícula con el número «FTY349U», nombre el archivo de imagen como «FTY349U.jpg».
Código: Realice OCR utilizando Tesseract Engine en matrículas
# specify path to the license plate images folder as shown below
path_for_license_plates = os.getcwd() + "/license-plates/**/*.jpg"
list_license_plates = []
predicted_license_plates = []
for path_to_license_plate in glob.glob(path_for_license_plates, recursive = True):
license_plate_file = path_to_license_plate.split("/")[-1]
license_plate, _ = os.path.splitext(license_plate_file)
'''
Here we append the actual license plate to a list
'''
list_license_plates.append(license_plate)
'''
Read each license plate image file using openCV
'''
img = cv2.imread(path_to_license_plate)
'''
We then pass each license plate image file
to the Tesseract OCR engine using the Python library
wrapper for it. We get back predicted_result for
license plate. We append the predicted_result in a
list and compare it with the original the license plate
'''
predicted_result = pytesseract.image_to_string(img, lang ='eng',
config ='--oem 3 --psm 6 -c tessedit_char_whitelist = ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789')
filter_predicted_result = "".join(predicted_result.split()).replace(":", "").replace("-", "")
predicted_license_plates.append(filter_predicted_result)
Ahora tenemos las placas pronosticadas pero no hemos visto cuál es la predicción, así que para ver los datos y la predicción hacemos un poco de visualización como se muestra a continuación. también estamos calculando la precisión de la predicción sin utilizar ninguna función integrada.
print("Actual License Plate", "\t", "Predicted License Plate", "\t", "Accuracy")
print("--------------------", "\t", "-----------------------", "\t", "--------")
def calculate_predicted_accuracy(actual_list, predicted_list):
for actual_plate, predict_plate in zip(actual_list, predicted_list):
accuracy = "0 %"
num_matches = 0
if actual_plate == predict_plate:
accuracy = "100 %"
else:
if len(actual_plate) == len(predict_plate):
for a, p in zip(actual_plate, predict_plate):
if a == p:
num_matches += 1
accuracy = str(round((num_matches / len(actual_plate)), 2) * 100)
accuracy += "%"
print(" ", actual_plate, "\t\t\t", predict_plate, "\t\t ", accuracy)
calculate_predicted_accuracy(list_license_plates, predicted_license_plates)
Producción:
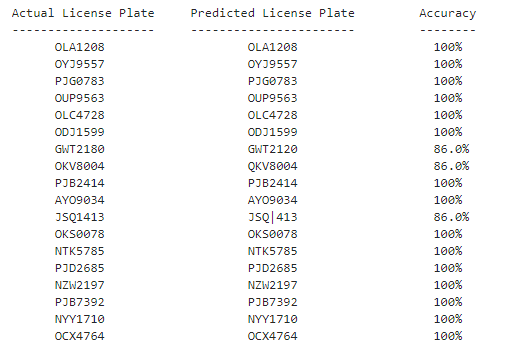
Vemos que el motor Tesseract OCR en su mayoría predice correctamente todas las matrículas con un 100 % de precisión. Para las matrículas, Tesseract OCR Engine predijo incorrectamente (es decir, GWT2180, OKV8004, JSQ1413), aplicaremos técnicas de procesamiento de imágenes en esos archivos de matrículas y los pasaremos al Tesseract OCR nuevamente. La aplicación de las técnicas de procesamiento de imágenes aumentaría la precisión del Tesseract Engine para las matrículas de GWT2180, OKV8004, JSQ1413.
Código: Técnicas de procesamiento de imágenes
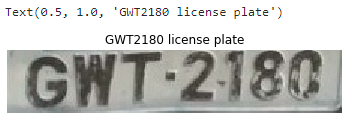
# Read the license plate file and display it
test_license_plate = cv2.imread(os.getcwd() + "/license-plates / GWT2180.jpg")
plt.imshow(test_license_plate)
plt.axis('off')
plt.title('GWT2180 license plate')
Producción:
- Redimensionamiento de imagen:
Cambie el tamaño del archivo de imagen por un factor de 2x en las direcciones horizontal y vertical usando cv2.resize
resize_test_license_plate=cv2.resize(test_license_plate,None, fx=2, fy=2,interpolation=cv2.INTER_CUBIC) - Conversión a escala de grises: A continuación, convertimos nuestro archivo de imagen redimensionado a escala de grises para optimizar la detección y reducir drásticamente la cantidad de colores presentes en la imagen, lo que ayudará en la detección de matrículas fácilmente.
grayscale_resize_test_license_plate=cv2.cvtColor(resize_test_license_plate, cv2.COLOR_BGR2GRAY) - Eliminar el ruido de la imagen:
Gaussian Blur es una técnica para eliminar el ruido de las imágenes. hace que los bordes sean más claros y suaves, lo que a su vez hace que los caracteres sean más legibles.gaussian_blur_license_plate=cv2.GaussianBlur(grayscale_resize_test_license_plate, (5,5),0)Ahora, pase el archivo de matrícula transformado al motor Tesseract OCR y vea el resultado previsto.
new_predicted_result_GWT2180=pytesseract.image_to_string(gaussian_blur_license_plate, lang='eng',config='--oem 3 -l eng --psm 6 -c tessedit_char_whitelist = ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789')filter_new_predicted_result_GWT2180="".join(new_predicted_result_GWT2180.split()).replace(":", "").replace("-", "")print(filter_new_predicted_result_GWT2180)Producción:
GWT2180
Del mismo modo, realice este procesamiento de imagen para todas las demás matrículas que no obtuvieron el 100 % de precisión. Finalmente, el modelo de detección de matrículas está listo.
Publicación traducida automáticamente
Artículo escrito por kevadiyasmeet y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA