Requisito previo: instalación de Hadoop , HDFS
Python Snakebite es una biblioteca de Python muy popular que podemos usar para comunicarnos con HDFS. Usando la biblioteca de cliente de Python proporcionada por el paquete Snakebite, podemos escribir fácilmente código de Python que funcione en HDFS. Utiliza mensajes protobuf para comunicarse directamente con NameNode. La biblioteca de cliente de python funciona directamente con HDFS sin realizar una llamada del sistema a hdfs dfs . Snakebite no es compatible con python3.
El hdfs dfs proporciona múltiples comandos a través de los cuales podemos realizar múltiples operaciones en HDFS. La biblioteca cliente que proporciona Snakebite contendrá varios métodos que nos permitirán recuperar datos de HDFS. El método text() se usa para simplemente leer los datos de un archivo disponible en nuestro HDFS. Entonces, realicemos una tarea rápida para comprender cómo podemos recuperar datos de un archivo de HDFS.
Tarea: Recuperación de datos de archivos de HDFS.
Paso 1: Cree un archivo de texto con el nombre data.txt y agréguele algunos datos.
cd Documents/ # Changing directory to Documents(You can choose as per your requirement) touch data.txt # touch command is used to create file in linux environment nano data.txt # nano is a command line text editor for Unix and Linux operating system cat data.txt # to see the content of a file

Paso 2: envíe este archivo data.txt a Hadoop HDFS con la ayuda del comando copyFromLocal .
Sintaxis:
hdfs dfs -copyFromLocal /path 1 /path 2 .... /path n /destination
Usando el comando para enviar data.txt al directorio raíz de HDFS.
hdfs dfs -copyFromLocal /home/dikshant/Documents/data.txt /
Ahora, compruebe si el archivo llega al directorio raíz de HDFS o no con la ayuda del siguiente comando.
hdfs dfs -ls /
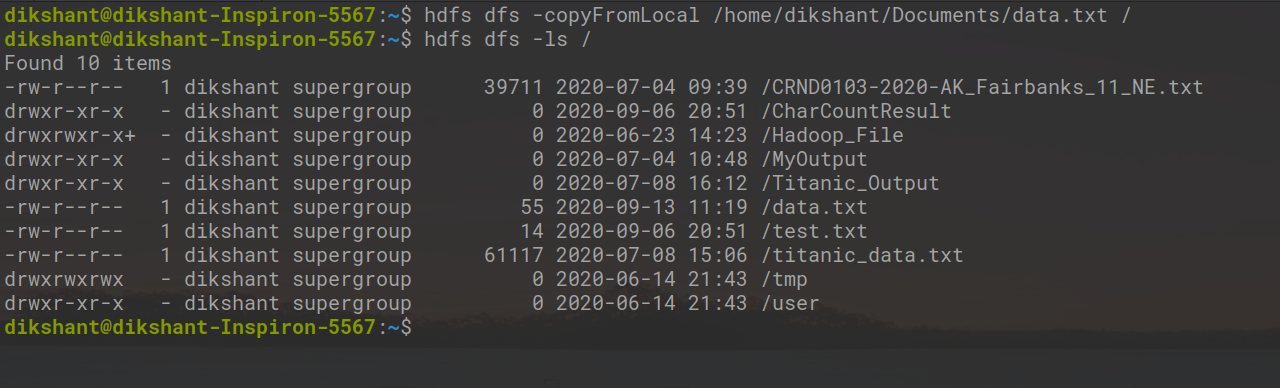
Puede verificarlo manualmente visitando http://localhost:50070/ luego Utilidades -> Examinar el sistema de archivos.
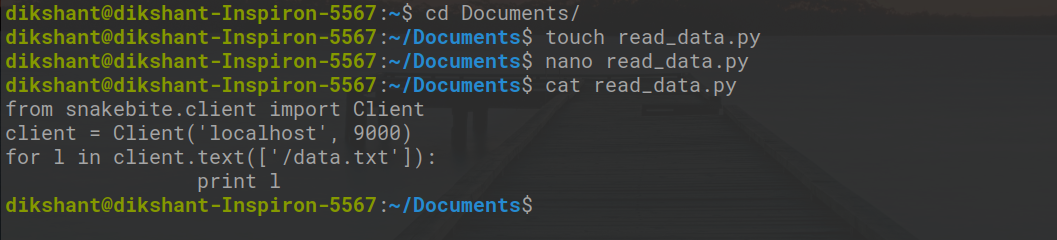
Paso 3: Ahora nuestra tarea es leer los datos de data.txt que enviamos a nuestro HDFS. Así que cree un archivo data_read.py en su sistema de archivos local y agréguele el siguiente código python.
Python
# importing the library
from snakebite.client import Client
# the below line create client connection to the HDFS NameNode
client = Client('localhost', 9000)
# iterate over data.txt file and will show all the content of data.txt
for l in client.text(['/data.txt']):
print l
Explicación del método Client():
El método Client() puede aceptar todos los argumentos enumerados a continuación:
- host (string): Dirección IP de NameNode.
- port(int): puerto RPC de Namenode.
- hadoop_version (int): versión del protocolo Hadoop (por defecto es: 9)
- use_trash (booleano): use la papelera al eliminar los archivos.
- uso_efectivo (string): usuario efectivo para las operaciones de HDFS (el usuario predeterminado es el usuario actual).
Paso 4: Ejecute el archivo read_data.py y observe el resultado.
python read_data.py

Hemos obtenido con éxito los datos de data.txt con la ayuda de la biblioteca del cliente.
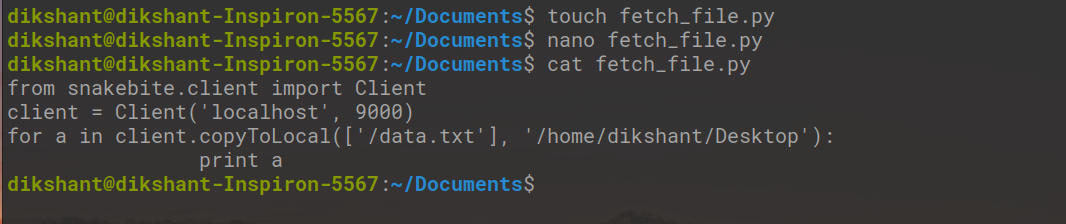
También podemos copiar cualquier archivo de HDFS a nuestro sistema de archivos local con la ayuda de Snakebite. Para copiar un archivo de HDFS, cree un archivo fetch_file.py y copie el código de Python a continuación. El método copyToLocal() se usa para lograr esto.
Python
from snakebite.client import Client
client = Client('localhost', 9000)
for a in client.copyToLocal(['/data.txt'], '/home/dikshant/Desktop'):
print a
Ahora, ejecute este archivo python y verá el siguiente resultado.
python fetch_file.py

Podemos observar que el archivo ahora se ha copiado en mi directorio /home/dikshant/desktop .

Publicación traducida automáticamente
Artículo escrito por dikshantmalidev y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA