En la capa de red, antes de que la red pueda realizar garantías de calidad de servicio, debe saber qué tráfico se garantiza. Una de las principales causas de la congestión es que el tráfico suele estar a ráfagas.
Para entender este concepto, primero tenemos que saber poco sobre la conformación del tráfico. Traffic Shaping es un mecanismo para controlar la cantidad y la velocidad del tráfico enviado a la red. El enfoque de la gestión de la congestión se denomina conformación del tráfico. El modelado del tráfico ayuda a regular la tasa de transmisión de datos y reduce la congestión.
Hay 2 tipos de algoritmos de modelado de tráfico:
- Cubo agujereado
- Cubo de fichas
Supongamos que tenemos una cubeta en la que estamos vertiendo agua en un orden aleatorio pero tenemos que sacar agua a un ritmo fijo, para ello haremos un agujero en el fondo de la cubeta. Asegurará que el agua que sale tenga una tasa fija, y también si el balde se llena, dejaremos de verterlo.
La tasa de entrada puede variar, pero la tasa de salida permanece constante. De manera similar, en las redes, una técnica llamada cubeta con fugas puede suavizar el tráfico en ráfagas. Los fragmentos en ráfaga se almacenan en el cubo y se envían a una velocidad promedio.
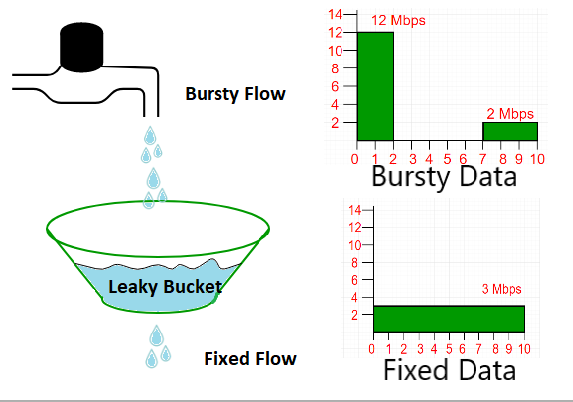
En la figura, asumimos que la red ha comprometido un ancho de banda de 3 Mbps para un host. El uso de la cubeta con fugas da forma al tráfico de entrada para que se ajuste a este compromiso. En la Figura, el host envía una ráfaga de datos a una velocidad de 12 Mbps durante 2 s, para un total de 24 Mbits de datos. El host permanece en silencio durante 5 s y luego envía datos a una velocidad de 2 Mbps durante 3 s, para un total de 6 Mbits de datos. En total, el host ha enviado 30 Mbits de datos en 10 s. El cubo con fugas suaviza el tráfico enviando datos a una velocidad de 3 Mbps durante los mismos 10 s.
Sin el depósito con fugas, la ráfaga inicial podría haber dañado la red al consumir más ancho de banda del reservado para este host. También podemos ver que el balde con fugas puede evitar la congestión.
Se puede implementar un algoritmo simple de balde con fugas utilizando la cola FIFO. Una cola FIFO contiene los paquetes. Si el tráfico consta de paquetes de tamaño fijo (p. ej., celdas en redes ATM), el proceso elimina una cantidad fija de paquetes de la cola en cada tic del reloj. Si el tráfico consta de paquetes de longitud variable, la tasa de salida fija debe basarse en el número de bytes o bits.
El siguiente es un algoritmo para paquetes de longitud variable:
- Inicialice un contador en n en el tictac del reloj.
- Si n es mayor que el tamaño del paquete, envíe el paquete y disminuya el contador según el tamaño del paquete. Repita este paso hasta que n sea más pequeño que el tamaño del paquete.
- Restablezca el contador y vaya al paso 1.
Ejemplo: Sea n=1000
Paquete=

Dado que n> frente a la cola, es decir, n>200
, por lo tanto, n=1000-200=800
El tamaño de paquete de 200 se envía a la red.
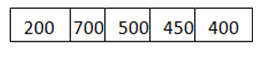
Ahora de nuevo n>delante de la cola, es decir, n > 400
Por lo tanto, n=800-400=400
El tamaño de paquete de 400 se envía a la red.

Dado que n< frente a la cola , por
lo tanto, el procedimiento se detiene.
Inicialice n=1000 en otro tic del reloj.
Este procedimiento se repite hasta que todos los paquetes se envían a la red.
A continuación se muestra la implementación del enfoque anterior:
C++
// cpp program to implement leakybucket
#include<bits/stdc++.h>
using namespace std;
int main()
{
int no_of_queries, storage, output_pkt_size;
int input_pkt_size, bucket_size, size_left;
// initial packets in the bucket
storage = 0;
// total no. of times bucket content is checked
no_of_queries = 4;
// total no. of packets that can
// be accommodated in the bucket
bucket_size = 10;
// no. of packets that enters the bucket at a time
input_pkt_size = 4;
// no. of packets that exits the bucket at a time
output_pkt_size = 1;
for(int i = 0; i < no_of_queries; i++) //space left
{
size_left = bucket_size - storage;
if(input_pkt_size <= size_left)
{
// update storage
storage += input_pkt_size;
printf("Buffer size= %d out of bucket size= %d\n", storage, bucket_size);
}
else
{
printf("Packet loss = %d\n", (input_pkt_size-(size_left)));
// full size
storage=bucket_size;
printf("Buffer size= %d out of bucket size= %d\n", storage, bucket_size);
}
storage -= output_pkt_size;
}
return 0;
}
// This code is contributed by bunny09262002
Java
//Java Implementation of Leaky bucket
import java.io.*;
import java.util.*;
class Leakybucket {
public static void main (String[] args) {
int no_of_queries,storage,output_pkt_size;
int input_pkt_size,bucket_size,size_left;
//initial packets in the bucket
storage=0;
//total no. of times bucket content is checked
no_of_queries=4;
//total no. of packets that can
// be accommodated in the bucket
bucket_size=10;
//no. of packets that enters the bucket at a time
input_pkt_size=4;
//no. of packets that exits the bucket at a time
output_pkt_size=1;
for(int i=0;i<no_of_queries;i++)
{
size_left=bucket_size-storage; //space left
if(input_pkt_size<=(size_left))
{
storage+=input_pkt_size;
System.out.println("Buffer size= "+storage+
" out of bucket size= "+bucket_size);
}
else
{
System.out.println("Packet loss = "
+(input_pkt_size-(size_left)));
//full size
storage=bucket_size;
System.out.println("Buffer size= "+storage+
" out of bucket size= "+bucket_size);
}
storage-=output_pkt_size;
}
}
}
Python3
# initial packets in the bucket
storage = 0;
# total no. of times bucket content is checked
no_of_queries = 4;
# total no. of packets that can
# be accommodated in the bucket
bucket_size = 10
# no. of packets that enters the bucket at a time
input_pkt_size = 4
# no. of packets that exits the bucket at a time
output_pkt_size = 1
for i in range(0,no_of_queries): #space left
size_left = bucket_size - storage;
if input_pkt_size <= size_left:
# update storage
storage += input_pkt_size
print("Buffer size = {} out of bucket size= {} ".format(storage, bucket_size))
else:
print("Packet loss = ", (input_pkt_size-(size_left)),end=" ");
# full size
storage=bucket_size;
print("Buffer size= {} out of bucket size = {}".format(storage, bucket_size));
storage -= output_pkt_size;
# This code is contributed by Arpit Jain
Producción
Buffer size= 4 out of bucket size= 10 Buffer size= 7 out of bucket size= 10 Buffer size= 10 out of bucket size= 10 Packet loss = 3 Buffer size= 10 out of bucket size= 10
Diferencia entre cubos Leaky y Token –
| Cubo agujereado | Cubo de fichas |
|---|---|
| Cuando el host tiene que enviar un paquete, el paquete se arroja al cubo. | En este balde con fugas se almacenan tokens generados a intervalos regulares de tiempo. |
| Fugas de balde a tasa constante | El cubo tiene capacidad máxima. |
| El tráfico en ráfagas se convierte en tráfico uniforme por balde con fugas. | Si hay un paquete listo, se elimina un token del depósito y se envía el paquete. |
| En la práctica, el cubo es una salida de cola finita a una tasa finita | Si no hay un token en el depósito, el paquete no se puede enviar. |
Alguna ventaja del token Bucket sobre el balde con fugas:
- Si el cubo está lleno en el token Cubo, los tokens se descartan, no los paquetes. Mientras está en el balde con fugas, los paquetes se descartan.
- Token Bucket puede enviar ráfagas grandes a una velocidad más rápida, mientras que el depósito con fugas siempre envía paquetes a una velocidad constante.
Este artículo es una contribución de Abhishek Kumar y Himanshu Gupta . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA