En este artículo, discutiremos cómo reemplazar el valor negativo en la columna Pandas DataFrame con el último valor positivo anterior.
Al hacer esto, pueden surgir dos situaciones:
- El valor permanece sin modificar si no existe ningún valor positivo anterior
- Actualización del valor a 0 si no existe ningún valor positivo en curso
Vamos a discutir estos casos en detalle.
Caso 1: el valor permanece sin modificar si no existe un valor positivo en curso
Se declara una variable para almacenar el último valor positivo anterior inicializado con algún entero negativo grande. A continuación, se realiza una iteración del marco de datos por columnas.
- En caso de que el valor sea negativo, se reemplaza con la variable de valor anterior positivo, si existe, de lo contrario, permanece sin modificar.
- Y, en caso de que el valor sea positivo, se actualiza la variable anterior de valor positivo.
Ejemplo:
Python3
import pandas as pd
# creating a pandas dataframe
df = pd.DataFrame([[8, -2, 0, 3, 51, 2],
[6, -2, -5, -7, 0, -1],
[-1, -12, -5, 4, 5, 3]])
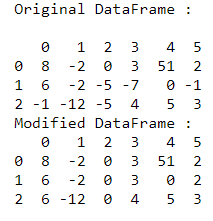
print("Original DataFrame : \n")
print(df)
# declaring a pre defined value
prec_val = -999
# iterate over columns
for i in range(df.shape[1]):
# resetting value over each column
prec_val = -999
# iterate over rows
for j in range(df.shape[0]):
# accessing the cell value
cell = df.at[j, i]
# check if cell value is negative
if(cell < 0):
# check if prec_val is not default
# set value
if(prec_val != -999):
# replace the cell value
df.at[j, i] = prec_val
else:
# store the latest value in variable
prec_val = df.at[j, i]
print("Modified DataFrame : ")
print(df)
Producción:
Caso 2: actualización del valor a 0 si no existe ningún valor positivo en curso
Este enfoque utiliza el concepto de enmascaramiento de marcos de datos para reemplazar los valores negativos del marco de datos. Los valores se recorren de izquierda a derecha en forma de columna, de arriba a abajo. En este enfoque, inicialmente, todos los valores < 0 en las celdas del marco de datos se convierten a NaN.
El método dataframe.ffill() de Pandas se utiliza para completar los valores faltantes en el marco de datos. ‘fill’ en este método significa ‘forward fill’ y propaga la última observación válida encontrada hacia adelante. La función ffill() se usa para completar los valores que faltan a lo largo del eje de índice que se especifica. Este método tiene la siguiente sintaxis:
Sintaxis: DataFrame.ffill(eje=Ninguno, en el lugar=Falso)
Parámetros:
- eje – {0, índice 1, columna}
- inplace : si es verdadero, complete el lugar.
A esto le sigue el método fillna() para llenar los valores NA/NaN usando el valor especificado. Aquí, llenamos los valores de NaN con 0, ya que es el valor entero positivo más bajo posible. Todos los valores negativos se convierten así en valores positivos. Este enfoque puede funcionar en marcos de datos que no tienen ningún valor de string almacenado. En caso de que no haya valores positivos anteriores, el valor negativo se reemplaza por 0.
Python3
import pandas as pd
# creating a pandas dataframe
data_frame = pd.DataFrame({'col1': [8, -2, 0, 3, 51, 2],
'col2': [-1, -2, -5, -7, 0, -1],
'col3': [-1, -12, -5, 4, 5, 3]})
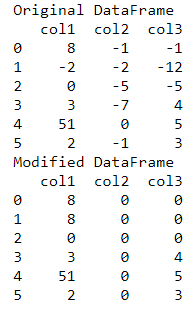
print("Original DataFrame")
print(data_frame)
# masking the data frame
data_frame = data_frame.mask(data_frame.lt(
0)).ffill().fillna(0).astype('int32')
print("Modified DataFrame")
print(data_frame)
Producción:
Publicación traducida automáticamente
Artículo escrito por codersgram9 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA