A veces necesitamos remodelar el marco de datos de Pandas para realizar el análisis de una mejor manera. La remodelación juega un papel crucial en el análisis de datos. Los pandas brindan funciones como derretir y derretir para remodelar. En este artículo, veremos qué es Pandas Melt y cómo usarlo para cambiar la forma de Wide to Tidy con identificadores.
Pandas Melt(): Pandas.melt() desvía un DataFrame de formato ancho a formato largo. La función Pandas melt() se utiliza para cambiar el diseño de DataFrame de ancho a largo. Se utiliza para realizar una configuración particular del objeto DataFrame donde al menos un segmento se completa como identificador. Todo el resto de tramos se tratan como calidades y no pivotan a la línea pivote y sólo dos tramos, variable y valor.
Sintaxis: Pandas.melt(column_level=Ninguno, variable_name=Ninguno, Value_name=’valor’, value_vars=Ninguno, id_vars=Ninguno, marco)
Parámetros:
- marco : marco de datos
- id_vars[tupla, lista o ndarray, opcional] : columna(s) para usar como variables de identificación.
- value_vars[tupla, lista o ndarray, opcional] : Columna(s) para anular el pivote. Si no se especifica, usa todas las columnas que no están configuradas como id_vars.
- var_name[scalar] : Nombre a usar para la columna ‘variable’. Si es Ninguno, usa marco.columnas.nombre o ‘variable’.
- value_name[scalar, default ‘value’] : Nombre a usar para la columna ‘valor’.
- col_level[int o string, opcional] : si las columnas son un índice múltiple, use este nivel para derretir.
Ejemplo 1:
Python3
# Load the libraries
import numpy as np
import pandas as pd
from scipy.stats import poisson
# We will use scipy.stats to create
# random numbers from Poisson distribution.
np.random.seed(seed = 128)
p1 = poisson.rvs(mu = 10, size = 3)
p2 = poisson.rvs(mu = 15, size = 3)
p3 = poisson.rvs(mu = 20, size = 3)
# Declaring the dataframe
data = pd.DataFrame({"P1":p1,
"P2":p2,
"P3":p3})
# Dataframe
print(" Wide Dataframe")
display(data)
data.melt()
# Change the names of the columns
data.melt(var_name = ["Sample"]).head()
# Specify a name for the values
print("\n Tidy Dataframe")
data.melt(var_name = "Sample",
value_name = "Count").head()
Producción:

Explicación: En este ejemplo, creamos tres conjuntos de datos usando la distribución de Poisson y creamos un marco de datos usando pandas. Luego, usando la función melt(), remodelamos los datos en forma larga en dos columnas y cambiamos el nombre de las dos columnas. La primera columna se llama «variable» de forma predeterminada y contiene los nombres de columna/variable. Y la segunda columna se llama «valor» y contiene los datos del marco de datos de formato ancho.
Ejemplo 2:
Python3
import pandas as pd
data = pd.DataFrame({'Name': {0: 'Samrat', 1: 'Tomar', 2: 'Verma'},
'Score': {0: '99', 1: '98', 2: '97'},
'Age': {0: 22, 1: 31, 2: 33}})
pd.melt(data, id_vars=['Name'], value_vars=['Score'])
display(pd.melt(data, id_vars=['Name'], value_vars=['Score']))
Producción:
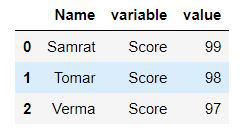
Explicación: En este ejemplo, creamos un marco de datos usando pandas. Luego, usando la función melt(), remodelamos los datos en forma larga en tres columnas y especificamos el Nombre como la identificación y la variable como Puntaje de la persona y el valor como sus puntajes. Además de la columna «id», la primera columna se llama «variable» de forma predeterminada y contiene los nombres de columna/variable. Y la segunda columna se llama «valor» y contiene los datos del marco de datos de formato ancho.
Publicación traducida automáticamente
Artículo escrito por samrat2825 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA