Pandas es una biblioteca de código abierto con licencia BSD escrita en lenguaje Python. Pandas proporciona estructuras de datos y herramientas de análisis de datos de alto rendimiento, rápidas y fáciles de usar para manipular datos numéricos y series temporales. Pandas se basa en la biblioteca Numpy y está escrito en lenguajes como Python, Cython y C. En 2008, Wes McKinney desarrolló la biblioteca Pandas. En pandas, podemos importar datos de varios formatos de archivo como JSON, SQL, Microsoft Excel, etc. La función de marcos de datos se utiliza para cargar y manipular los datos.
A veces necesitamos remodelar el marco de datos de Pandas para realizar el análisis de una mejor manera. La remodelación juega un papel crucial en el análisis de datos. Los pandas brindan funciones como derretir y derretir para remodelar.
Pandas.melt()
melt() se usa para convertir un marco de datos ancho en una forma más larga. Esta función se puede utilizar cuando existen requisitos para considerar una columna específica como identificador.
Sintaxis: pandas.melt(marco, id_vars=Ninguno, value_vars=Ninguno, var_name=Ninguno, value_name=’valor’, col_level=Ninguno)
Ejemplo 1:
Inicialice el marco de datos con datos sobre ‘ Días ‘, ‘ Pacientes ‘ y ‘ Recuperación ‘.
Python3
# importing pandas library import pandas as pd # creating and initializing a list values = [['Monday', 65000, 50000], ['Tuesday', 68000, 45000], ['Wednesday', 70000, 55000], ['Thursday', 60000, 47000], ['Friday', 49000, 25000], ['Saturday', 54000, 35000], ['Sunday', 100000, 70000]] # creating a pandas dataframe df = pd.DataFrame(values, columns=['DAYS', 'PATIENTS', 'RECOVERY']) # displaying the data frame df
Producción:
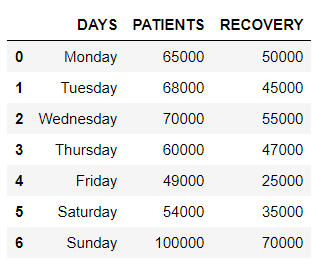
Ahora, remodelamos el marco de datos usando pandas.melt() alrededor de la columna ‘DÍAS ‘.
Python3
# melting with DAYS as column identifier reshaped_df = df.melt(id_vars=['DAYS']) # displaying the reshaped data frame reshaped_df
Producción:
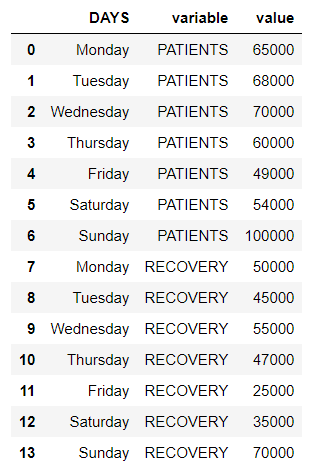
Ejemplo 2:
Ahora, en el marco de datos utilizado anteriormente, se introduce una nueva columna llamada ‘ Muertes ‘.
Python3
# importing pandas library import pandas as pd # creating and initializing a dataframe values = [['Monday', 65000, 50000, 1500], ['Tuesday', 68000, 45000, 7250], ['Wednesday', 70000, 55000, 1400], ['Thursday', 60000, 47000, 4200], ['Friday', 49000, 25000, 3000], ['Saturday', 54000, 35000, 2000], ['Sunday', 100000, 70000, 4550]] # creating a pandas dataframe df = pd.DataFrame(values, columns=['DAYS', 'PATIENTS', 'RECOVERY', 'DEATHS']) # displaying the data frame df
Producción:
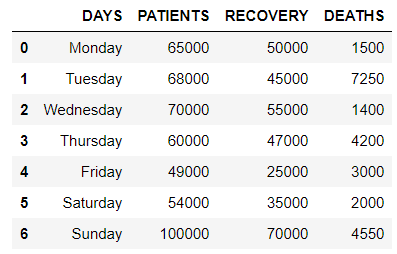
remodelamos el marco de datos usando pandas.melt() alrededor de la columna ‘ PACIENTES ‘.
Python3
# reshaping data frame # using pandas.melt() reshaped_df = df.melt(id_vars=['PATIENTS']) # displaying the reshaped data frame reshaped_df
Producción:
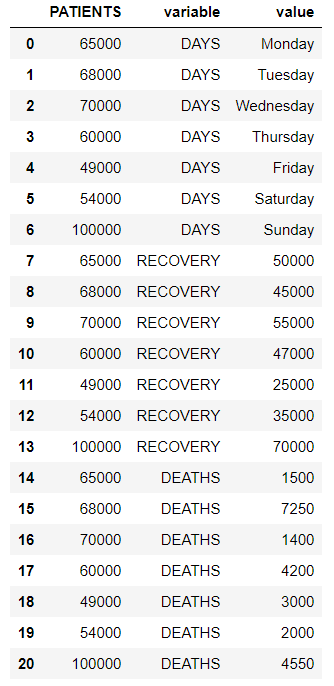
Pandas.pivot()/ función sin fundir
Pivoting, Unmelting o Reverse Melting se usa para convertir una columna con múltiples valores en varias columnas propias.
Sintaxis: DataFrame.pivot(índice=Ninguno, columnas=Ninguno, valores=Ninguno)
Ejemplo 1:
Cree un marco de datos que contenga los datos de ID, Nombre, Marcas y Deportes de 6 estudiantes.
Python3
# importing pandas library import pandas as pd # creating and initializing a list values = [[101, 'Rohan', 455, 'Football'], [111, 'Elvish', 250, 'Chess'], [192, 'Deepak', 495, 'Cricket'], [201, 'Sai', 400, 'Ludo'], [105, 'Radha', 350, 'Badminton'], [118, 'Vansh', 450, 'Badminton']] # creating a pandas dataframe df = pd.DataFrame(values, columns=['ID', 'Name', 'Marks', 'Sports']) # displaying the data frame df
Producción:
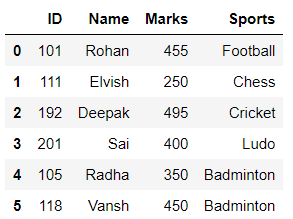
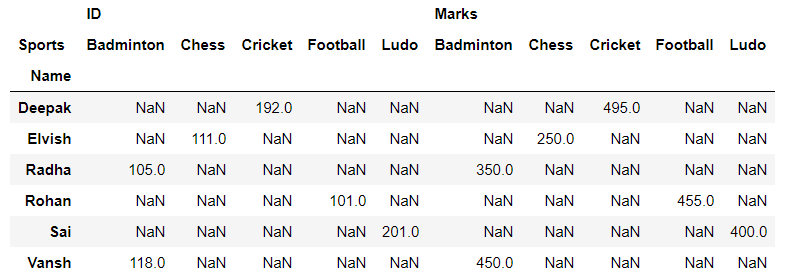
Unmelting alrededor de la columna Deportes:
Python3
# unmelting reshaped_df = df.pivot(index='Name', columns='Sports') # displaying the reshaped data frame reshaped_df
Producción:
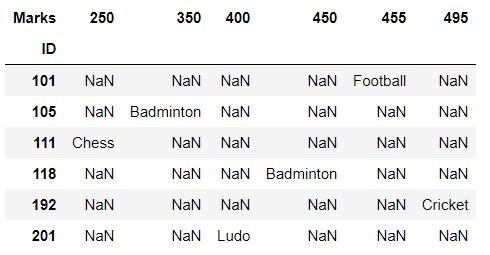
Ejemplo 2:
Considere el mismo marco de datos utilizado en el ejemplo anterior. La desfusión también se puede hacer en base a más de una columna.
Python3
reshaped_df = df.pivot('ID', 'Marks', 'Sports')
# displaying the reshaped data frame
reshaped_df
Producción:
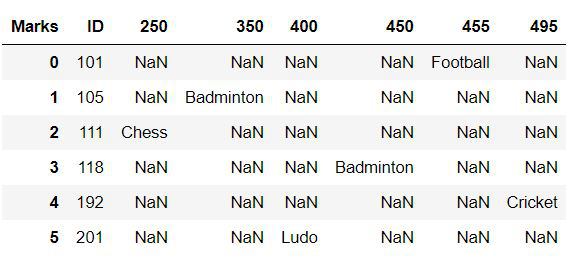
Pero el marco de datos remodelado parece poco diferente del original en términos de índice. Para obtener el índice también establecido como marco de datos original, use la función reset_index() en el marco de datos reformado.
Python3
reshaped_df = df.pivot('ID', 'Marks', 'Sports')
# reseting index
df_new = reshaped_df.reset_index()
# displaying the reshaped data frame
df_new
Producción:
Publicación traducida automáticamente
Artículo escrito por vanshgaur14866 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA