Los pandas usan varios métodos para remodelar el marco de datos y la serie. Veamos algo de ese método de remodelación.
Importemos primero un marco de datos.
# import pandas module
import pandas as pd
# making dataframe
df = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# it was print the first 5-rows
print(df.head())
Producción: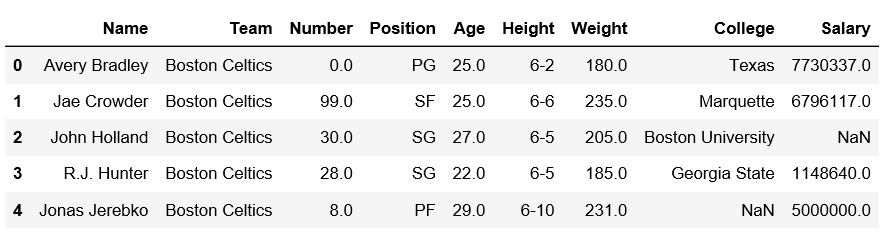
Usando el método stack():
El método Stack funciona con los objetos MultiIndex en DataFrame, devolviendo un DataFrame con un índice con un nuevo nivel más interno de etiquetas de fila. Cambia la mesa ancha por una mesa larga.
# import pandas module
import pandas as pd
# making dataframe
df = pd.read_csv("nba.csv")
# reshape the dataframe using stack() method
df_stacked = df.stack()
print(df_stacked.head(26))
Salida: 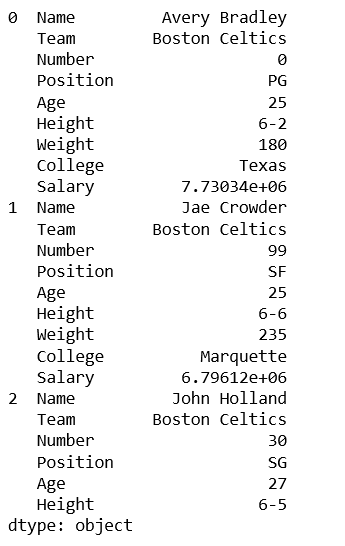
Usar el método unstack():unstack es similar al método stack, también funciona con objetos de índice múltiple en el marco de datos, produciendo un marco de datos remodelado con un nuevo nivel más interno de etiquetas de columna.
# import pandas module
import pandas as pd
# making dataframe
df = pd.read_csv("nba.csv")
# unstack() method
df_unstacked = df_stacked.unstack()
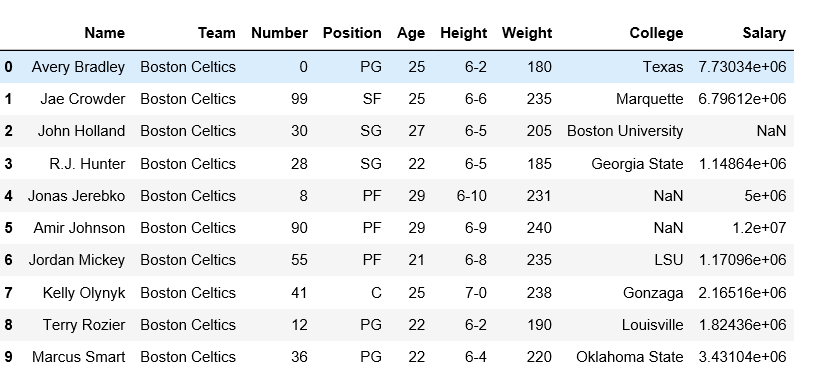
print(df_unstacked.head(10))
melt()Método de uso
: derretir en pandas remodelar el marco de datos de formato ancho a formato largo. Utiliza «id_vars[‘col_names’]» para derretir el marco de datos por nombres de columna.
# import pandas module
import pandas as pd
# making dataframe
df = pd.read_csv("nba.csv")
# it takes two columns "Name" and "Team"
df_melt = df.melt(id_vars =['Name', 'Team'])
print(df_melt.head(10))
Producción: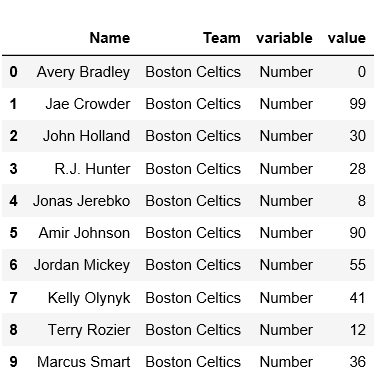
Publicación traducida automáticamente
Artículo escrito por soundarajthevan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA