La regresión de Ridge es un algoritmo de clasificación que funciona en parte porque no requiere estimadores imparciales. La regresión de Ridge minimiza la suma residual de los cuadrados de los predictores en un modelo dado. La regresión de cresta incluye una reducción de la estimación de los coeficientes hacia cero.
Regresión de cresta en R
La regresión de Ridge es un algoritmo de regresión regularizado que realiza una regularización L2 que agrega una penalización L2, que es igual al cuadrado de la magnitud de los coeficientes. Todos los coeficientes se reducen por el mismo factor, es decir, ninguno se elimina. La regularización L2 no dará como resultado modelos dispersos. La regresión de cresta agrega sesgo para hacer que las estimaciones sean aproximaciones confiables a los valores reales de la población. La regresión de cresta procede agregando un pequeño valor k a los elementos diagonales de la array de correlación, es decir, la regresión de cresta recibió su nombre porque se cree que la diagonal de unos en la array de correlación es una cresta.
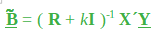
Aquí, k es una cantidad positiva menor que 1 (generalmente menor que 0,3). La cantidad de sesgo en el estimador viene dada por:
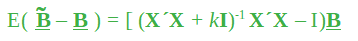
La array de covarianza viene dada por:

Existe un valor de k para el cual el error cuadrático medio (MSE, es decir, la varianza más el sesgo al cuadrado) del estimador de cresta es menor que el estimador de mínimos cuadrados. El valor apropiado de k depende de los verdaderos coeficientes de regresión (que se están estimando) y la optimización de la solución de cresta.
- Cuando lambda = 0, la regresión de cresta es igual a la regresión de mínimos cuadrados.
- Cuando lambda = infinito, todos los coeficientes se reducen a cero.
Además, la pena ideal está entre 0 e infinito. Implementemos la regresión de Ridge en la programación R.
Implementación de regresión de cresta en R
El conjunto de datos
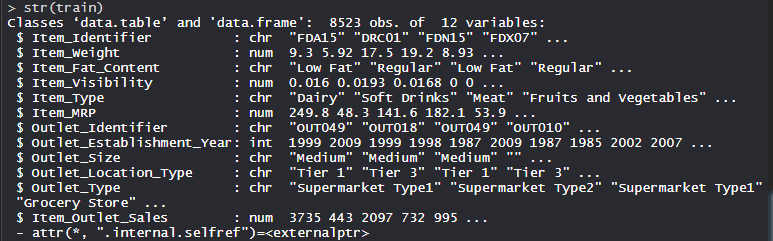
gran centro comercialEl conjunto de datos consta de 1559 productos en 10 tiendas en diferentes ciudades. Se han definido ciertos atributos de cada producto y tienda. Consta de 12 características, es decir, Item_Identifier (es una identificación de producto única asignada a cada artículo distinto), Item_Weight (incluye el peso del producto), Item_Fat_Content (describe si el producto es bajo en grasa o no), Item_Visibility (menciona el porcentaje de la área de exhibición total de todos los productos en una tienda asignados a un producto en particular), Item_Type (describe la categoría de alimentos a la que pertenece el artículo), Item_MRP (Precio máximo de venta al público (precio de lista) del producto), Outlet_Identifier (ID de tienda único asignado. Consiste en una string alfanumérica de longitud 6), Outlet_Establishment_Year (menciona el año en que se estableció la tienda),
R
# Loading data
train = fread("Train_UWu5bXk.csv")
test = fread("Test_u94Q5KV.csv")
# Structure
str(train)
Producción:
Realización de regresión de cresta en conjunto de datos
Usando el algoritmo de regresión de Ridge en el conjunto de datos que incluye 12 funciones con 1559 productos en 10 tiendas en diferentes ciudades.
R
# Installing Packages
install.packages("data.table")
install.packages("dplyr")
install.packages("glmnet")
install.packages("ggplot2")
install.packages("caret")
install.packages("xgboost")
install.packages("e1071")
install.packages("cowplot")
# load packages
library(data.table) # used for reading and manipulation of data
library(dplyr) # used for data manipulation and joining
library(glmnet) # used for regression
library(ggplot2) # used for ploting
library(caret) # used for modeling
library(xgboost) # used for building XGBoost model
library(e1071) # used for skewness
library(cowplot) # used for combining multiple plots
# Loading datasets
train = fread("Train_UWu5bXk.csv")
test = fread("Test_u94Q5KV.csv")
# Setting test dataset
# Combining datasets
# add Item_Outlet_Sales to test data
test[, Item_Outlet_Sales := NA]
combi = rbind(train, test)
# Missing Value Treatment
missing_index = which(is.na(combi$Item_Weight))
for(i in missing_index)
{
item = combi$Item_Identifier[i]
combi$Item_Weight[i] =
mean(combi$Item_Weight[combi$Item_Identifier == item],
na.rm = T)
}
# Replacing 0 in Item_Visibility with mean
zero_index = which(combi$Item_Visibility == 0)
for(i in zero_index)
{
item = combi$Item_Identifier[i]
combi$Item_Visibility[i] =
mean(combi$Item_Visibility[combi$Item_Identifier == item],
na.rm = T)
}
# Label Encoding
# To convert categorical in numerical
combi[, Outlet_Size_num := ifelse(Outlet_Size == "Small", 0,
ifelse(Outlet_Size == "Medium", 1, 2))]
combi[, Outlet_Location_Type_num :=
ifelse(Outlet_Location_Type == "Tier 3", 0,
ifelse(Outlet_Location_Type == "Tier 2", 1, 2))]
combi[, c("Outlet_Size", "Outlet_Location_Type") := NULL]
# One Hot Encoding
# To convert categorical in numerical
ohe_1 = dummyVars("~.", data = combi[, -c("Item_Identifier",
"Outlet_Establishment_Year",
"Item_Type")], fullRank = T)
ohe_df = data.table(predict(ohe_1, combi[, -c("Item_Identifier",
"Outlet_Establishment_Year",
"Item_Type")]))
combi = cbind(combi[, "Item_Identifier"], ohe_df)
# Remove skewness
skewness(combi$Item_Visibility)
skewness(combi$price_per_unit_wt)
# log + 1 to avoid division by zero
combi[, Item_Visibility := log(Item_Visibility + 1)]
# Scaling and Centering data
num_vars = which(sapply(combi, is.numeric)) # index of numeric features
num_vars_names = names(num_vars)
combi_numeric = combi[, setdiff(num_vars_names, "Item_Outlet_Sales"),
with = F]
prep_num = preProcess(combi_numeric, method=c("center", "scale"))
combi_numeric_norm = predict(prep_num, combi_numeric)
# removing numeric independent variables
combi[, setdiff(num_vars_names, "Item_Outlet_Sales") := NULL]
combi = cbind(combi, combi_numeric_norm)
# splitting data back to train and test
train = combi[1:nrow(train)]
test = combi[(nrow(train) + 1):nrow(combi)]
# Removing Item_Outlet_Sales
test[, Item_Outlet_Sales := NULL]
# Model Building :Lasso Regression
set.seed(123)
control = trainControl(method ="cv", number = 5)
Grid_la_reg = expand.grid(alpha = 1, lambda = seq(0.001,
0.1, by = 0.0002))
# Model Building : Ridge Regression
set.seed(123)
control = trainControl(method ="cv", number = 5)
Grid_ri_reg = expand.grid(alpha = 0, lambda = seq(0.001, 0.1,
by = 0.0002))
# Training Ridge Regression model
Ridge_model = train(x = train[, -c("Item_Identifier",
"Item_Outlet_Sales")],
y = train$Item_Outlet_Sales,
method = "glmnet",
trControl = control,
tuneGrid = Grid_reg
)
Ridge_model
# mean validation score
mean(Ridge_model$resample$RMSE)
# Plot
plot(Ridge_model, main="Ridge Regression")
Producción:
- Modelo Ridge_model:
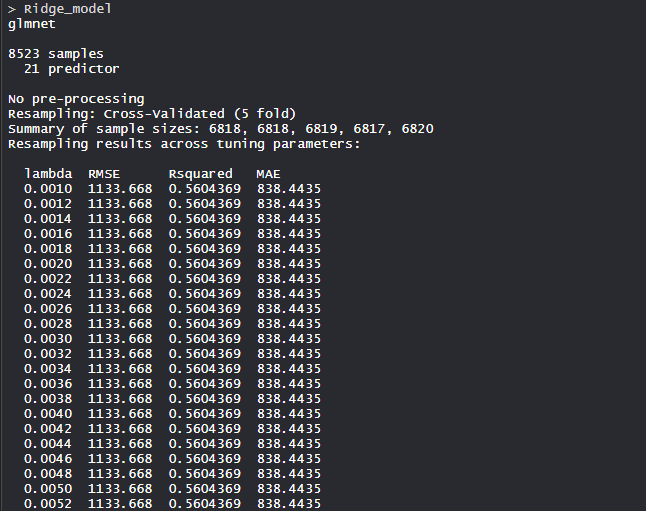
El modelo de regresión de Ridge utiliza el valor alfa como 0 y el valor lambda como 0,1. Se utilizó RMSE para seleccionar el modelo óptimo utilizando el valor más pequeño.
- Puntuación media de validación:

Puntuación media de validación
La puntuación media de validación del modelo es 1133,668.
- Gráfico:
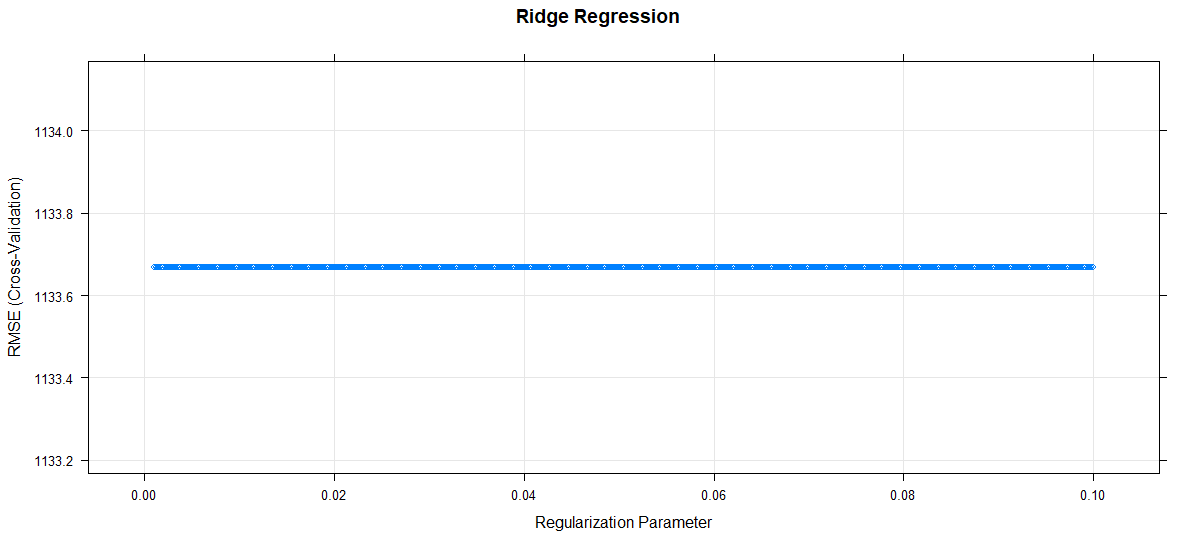
El parámetro de regularización aumenta, RMSE permanece constante.