Este artículo analiza los conceptos básicos de Softmax Regression y su implementación en Python usando la biblioteca TensorFlow.
¿Qué es la regresión Softmax?
La regresión Softmax (o regresión logística multinomial ) es una generalización de la regresión logística para el caso en el que queremos manejar varias clases.
Puede encontrar una introducción suave a la regresión lineal aquí:
Comprensión de la regresión logística
En la regresión logística binaria asumimos que las etiquetas eran binarias, es decir, para la  observación,
observación,
Pero considere un escenario en el que necesitamos clasificar una observación de dos o más etiquetas de clase. Por ejemplo, clasificación de dígitos. Aquí, las etiquetas posibles son:
En tales casos, podemos usar Softmax Regression .
Primero definamos nuestro modelo:
- Deje que el conjunto de datos tenga ‘m’ características y ‘n’ observaciones. Además, hay etiquetas de clase ‘k’, es decir, cada observación se puede clasificar como uno de los posibles valores objetivo ‘k’. Por ejemplo, si tenemos un conjunto de datos de 100 imágenes de dígitos escritos a mano de tamaño vectorial 28 × 28 para la clasificación de dígitos, tenemos n = 100, m = 28 × 28 = 784 y k = 10.
- Array
de características La array de características, , se representa como:
, se representa como:  Aquí,
Aquí,  denota los valores de
denota los valores de  características para la observación. La array tiene dimensiones:
características para la observación. La array tiene dimensiones:
- Array de peso
Definimos una array de peso como:
como: 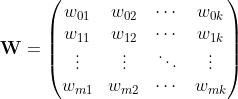 Aquí,
Aquí,  representa el peso asignado a la característica para la etiqueta de clase. La array tiene dimensiones:
representa el peso asignado a la característica para la etiqueta de clase. La array tiene dimensiones:  . Inicialmente, la array de pesos se llena usando alguna distribución normal.
. Inicialmente, la array de pesos se llena usando alguna distribución normal.
- Array de puntuación logit
Luego, definimos nuestra array de entrada neta (también llamada array de puntuación logit ) , como:
, como:
Z = XW
La array tiene dimensiones:
 .
.Actualmente, estamos tomando una columna adicional en la array de características
y una fila adicional en la array de peso, . Estas columnas y filas adicionales corresponden a los términos de sesgo asociados con cada predicción. Esto podría simplificarse definiendo una array adicional para el sesgo,  de tamaño donde
de tamaño donde  . (¡En la práctica, todo lo que necesitamos es un vector de tamaño
. (¡En la práctica, todo lo que necesitamos es un vector de tamaño  y algunas técnicas de transmisión para los términos de sesgo!)
y algunas técnicas de transmisión para los términos de sesgo!)Entonces, la array de puntuación final
es:Z = XW+b
donde
array tiene dimensiones  mientras que tiene dimensiones
mientras que tiene dimensiones  . ¡ Pero la array todavía tiene el mismo valor y dimensiones!
. ¡ Pero la array todavía tiene el mismo valor y dimensiones!Pero, ¿qué significa array
? En realidad,  es la probabilidad de la etiqueta j para la observación. ¡No es un valor de probabilidad adecuado, pero se puede considerar como una puntuación otorgada a cada etiqueta de clase para cada observación!
es la probabilidad de la etiqueta j para la observación. ¡No es un valor de probabilidad adecuado, pero se puede considerar como una puntuación otorgada a cada etiqueta de clase para cada observación!Definamos
 como el vector de puntuación logit para la observación.
como el vector de puntuación logit para la observación.Por ejemplo, deje que el vector
![Z_5 = [1.1, 2.0, 3.1, 5.2, 1.0, 1.5, 0.2, 0.1, 1.2, 0.4]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-080ae98e71957737ece9d382a960e171_l3.png "Rendered by QuickLaTeX.com") represente la puntuación de cada una de las etiquetas de clase
represente la puntuación de cada una de las etiquetas de clase  en el problema de clasificación de dígitos escrito a mano para la
en el problema de clasificación de dígitos escrito a mano para la  observación. Aquí, la puntuación máxima es 5,2, que corresponde a la etiqueta de clase ‘3’. Por lo tanto, nuestro modelo actualmente predice la observación/imagen como ‘3’.
observación. Aquí, la puntuación máxima es 5,2, que corresponde a la etiqueta de clase ‘3’. Por lo tanto, nuestro modelo actualmente predice la observación/imagen como ‘3’.
- Capa Softmax
Es más difícil entrenar el modelo utilizando valores de puntuación, ya que es difícil diferenciarlos al implementar el algoritmo Gradient Descent para minimizar la función de costo. Por lo tanto, necesitamos alguna función que normalice las puntuaciones logit y que las haga fácilmente diferenciables. Para convertir la arrayde puntuación en probabilidades, usamos la función Softmax .
Para un vector
 , la función softmax
, la función softmax  se define como:
se define como: 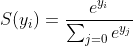 Entonces, la función softmax hará 2 cosas:
Entonces, la función softmax hará 2 cosas:1. convert all scores to probabilities. 2. sum of all probabilities is 1.
Recuerde que en el clasificador logístico binario, usamos la función sigmoidea para la misma tarea. ¡La función Softmax no es más que una generalización de la función sigmoidea! Ahora, esta función softmax calcula la probabilidad de que la
muestra de entrenamiento pertenezca a la clase  dado el vector logits como:
dado el vector logits como: 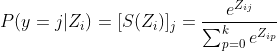
En forma de vector, simplemente podemos escribir: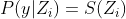
Para simplificar, denotemos el vector de probabilidad softmax para la observación.
el vector de probabilidad softmax para la observación.
- Array objetivo codificada en caliente
Dado que la función softmax nos proporciona un vector de probabilidades de cada etiqueta de clase para una observación dada, ¡necesitamos convertir el vector objetivo en el mismo formato para calcular la función de costo! En correspondencia con cada observación, hay un vector de destino (¡en lugar de un valor de destino!) Compuesto de solo ceros y unos donde la única etiqueta correcta se establece como 1. Esta técnica se denomina codificación one-hot. Consulte el diagrama que se proporciona a continuación para obtener una mejor comprensión: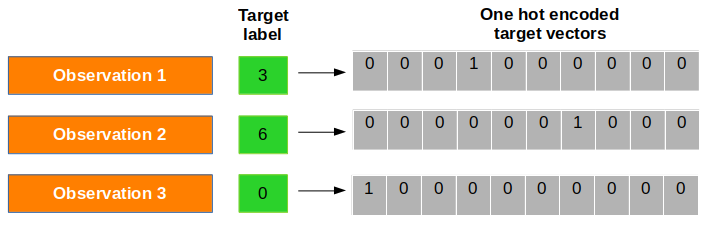
Ahora, denotamos el vector de codificación one-hot para la
observación como
- Función de costo
Ahora, necesitamos definir una función de costo para la cual, tenemos que comparar las probabilidades de softmax y el vector de destino codificado en caliente para la similitud. Usamos el concepto de Cross-Entropy para lo mismo. La entropía cruzada es una función de cálculo de distancia que toma las probabilidades calculadas de la función softmax y la array de codificación en caliente creada para calcular la distancia. Para las clases objetivo correctas, los valores de distancia serán menores y los valores de distancia serán mayores para las clases objetivo incorrectas. Definimos la entropía cruzada, para la observación con el vector de probabilidad softmax y el vector objetivo único, como:
para la observación con el vector de probabilidad softmax y el vector objetivo único, como: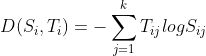
Y ahora, la función de costo
 puede definirse como la entropía cruzada promedio, es decir:
puede definirse como la entropía cruzada promedio, es decir: 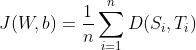
¡y la tarea es minimizar esta función de costo!
- Algoritmo de descenso de gradiente
Para aprender nuestro modelo softmax a través del descenso de gradiente, necesitamos calcular la derivada: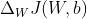 y
y 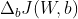 que luego usamos para actualizar los pesos y sesgos en la dirección opuesta del gradiente:
que luego usamos para actualizar los pesos y sesgos en la dirección opuesta del gradiente: 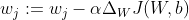 y
y 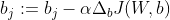 para cada clase donde
para cada clase donde  y
y  está aprendiendo tasa. este gradiente de costo, actualizamos iterativamente la array de peso hasta que alcanzamos un número específico de épocas (pasa sobre el conjunto de entrenamiento) o alcanzamos el umbral de costo deseado.
está aprendiendo tasa. este gradiente de costo, actualizamos iterativamente la array de peso hasta que alcanzamos un número específico de épocas (pasa sobre el conjunto de entrenamiento) o alcanzamos el umbral de costo deseado.
Implementación
Ahora implementemos Softmax Regression en el conjunto de datos de dígitos escritos a mano de MNIST usando la biblioteca TensorFlow .
Para una introducción suave a TensorFlow , siga este tutorial:
Introducción a TensorFlow
Paso 1: Importa las dependencias
En primer lugar, importamos las dependencias.
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt
Paso 2: Descarga los datos
TensorFlow le permite descargar y leer los datos MNIST automáticamente. Considere el código dado a continuación. Descargará y guardará datos en la carpeta, MNIST_data , en su directorio de proyecto actual y lo cargará en el programa actual.
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
Extracting MNIST_data/train-images-idx3-ubyte.gz Extracting MNIST_data/train-labels-idx1-ubyte.gz Extracting MNIST_data/t10k-images-idx3-ubyte.gz Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
Paso 3: comprender los datos
Ahora, tratamos de entender la estructura del conjunto de datos.
Los datos de MNIST se dividen en tres partes: 55 000 puntos de datos de entrenamiento ( mnist.train ), 10 000 puntos de datos de prueba ( mnist.test ) y 5000 puntos de datos de validación ( mnist.validation ).
Cada imagen tiene 28 píxeles por 28 píxeles que se ha aplanado en una array numpy 1-D de tamaño 784. El número de etiquetas de clase es 10. Cada etiqueta de destino ya se proporciona en forma codificada en caliente.
print("Shape of feature matrix:", mnist.train.images.shape)
print("Shape of target matrix:", mnist.train.labels.shape)
print("One-hot encoding for 1st observation:\n", mnist.train.labels[0])
# visualize data by plotting images
fig,ax = plt.subplots(10,10)
k = 0
for i in range(10):
for j in range(10):
ax[i][j].imshow(mnist.train.images[k].reshape(28,28), aspect='auto')
k += 1
plt.show()
Producción:
Shape of feature matrix: (55000, 784) Shape of target matrix: (55000, 10) One-hot encoding for 1st observation: [ 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
Paso 4: Definición del gráfico de cálculo
Ahora, creamos un gráfico de cálculo.
# number of features num_features = 784 # number of target labels num_labels = 10 # learning rate (alpha) learning_rate = 0.05 # batch size batch_size = 128 # number of epochs num_steps = 5001 # input data train_dataset = mnist.train.images train_labels = mnist.train.labels test_dataset = mnist.test.images test_labels = mnist.test.labels valid_dataset = mnist.validation.images valid_labels = mnist.validation.labels # initialize a tensorflow graph graph = tf.Graph() with graph.as_default(): """ defining all the nodes """ # Inputs tf_train_dataset = tf.placeholder(tf.float32, shape=(batch_size, num_features)) tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels)) tf_valid_dataset = tf.constant(valid_dataset) tf_test_dataset = tf.constant(test_dataset) # Variables. weights = tf.Variable(tf.truncated_normal([num_features, num_labels])) biases = tf.Variable(tf.zeros([num_labels])) # Training computation. logits = tf.matmul(tf_train_dataset, weights) + biases loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits( labels=tf_train_labels, logits=logits)) # Optimizer. optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss) # Predictions for the training, validation, and test data. train_prediction = tf.nn.softmax(logits) valid_prediction = tf.nn.softmax(tf.matmul(tf_valid_dataset, weights) + biases) test_prediction = tf.nn.softmax(tf.matmul(tf_test_dataset, weights) + biases)
Algunos puntos importantes a tener en cuenta:
- Para los datos de entrenamiento, usamos un marcador de posición que se alimentará en tiempo de ejecución con un minilote de entrenamiento. La técnica de usar minilotes para el modelo de entrenamiento usando descenso de gradiente se denomina descenso de gradiente estocástico .
Tanto en el descenso de gradiente (GD) como en el descenso de gradiente estocástico (SGD), actualiza un conjunto de parámetros de manera iterativa para minimizar una función de error. Mientras está en GD, debe ejecutar TODAS las muestras en su conjunto de entrenamiento para hacer una sola actualización de un parámetro en una iteración particular, en SGD, por otro lado, usa SOLO UNO o SUBCONJUNTO de muestra de entrenamiento de su conjunto de entrenamiento para hacer la actualización de un parámetro en una iteración particular. Si usa SUBSET, se llama Descenso de gradiente estocástico de minilotes. Por lo tanto, si la cantidad de muestras de entrenamiento es grande, de hecho, muy grande, entonces usar el descenso de gradiente puede llevar demasiado tiempo porque en cada iteración, cuando actualiza los valores de los parámetros, está ejecutando el conjunto de entrenamiento completo. Por otra parte, usar SGD será más rápido porque usa solo una muestra de entrenamiento y comienza a mejorar de inmediato desde la primera muestra. SGD a menudo converge mucho más rápido en comparación con GD, pero la función de error no se minimiza tan bien como en el caso de GD. A menudo, en la mayoría de los casos, la aproximación cercana que obtiene en SGD para los valores de los parámetros es suficiente porque alcanzan los valores óptimos y siguen oscilando allí.
- La array de peso se inicializa usando valores aleatorios siguiendo una distribución normal (truncada). Esto se logra utilizando el método tf.truncated_normal . Los sesgos se inicializan a cero usando el método tf.zeros .
- Ahora, multiplicamos las entradas con la array de peso y agregamos sesgos. Calculamos el softmax y la entropía cruzada usando tf.nn.softmax_cross_entropy_with_logits (es una operación en TensorFlow, porque es muy común y se puede optimizar). Tomamos el promedio de esta entropía cruzada en todos los ejemplos de entrenamiento usando el método tf.reduce_mean .
- Vamos a minimizar la pérdida usando el descenso de gradiente. Para esto, usamos tf.train.GradientDescentOptimizer .
- train_prediction , valid_prediction y test_prediction no son parte del entrenamiento, solo están aquí para que podamos informar cifras de precisión mientras entrenamos.
Paso 5: ejecutar el gráfico de cálculo
Dado que ya hemos construido el gráfico de cálculo, ahora es el momento de ejecutarlo a través de una sesión.
# utility function to calculate accuracy
def accuracy(predictions, labels):
correctly_predicted = np.sum(np.argmax(predictions, 1) == np.argmax(labels, 1))
accu = (100.0 * correctly_predicted) / predictions.shape[0]
return accu
with tf.Session(graph=graph) as session:
# initialize weights and biases
tf.global_variables_initializer().run()
print("Initialized")
for step in range(num_steps):
# pick a randomized offset
offset = np.random.randint(0, train_labels.shape[0] - batch_size - 1)
# Generate a minibatch.
batch_data = train_dataset[offset:(offset + batch_size), :]
batch_labels = train_labels[offset:(offset + batch_size), :]
# Prepare the feed dict
feed_dict = {tf_train_dataset : batch_data,
tf_train_labels : batch_labels}
# run one step of computation
_, l, predictions = session.run([optimizer, loss, train_prediction],
feed_dict=feed_dict)
if (step % 500 == 0):
print("Minibatch loss at step {0}: {1}".format(step, l))
print("Minibatch accuracy: {:.1f}%".format(
accuracy(predictions, batch_labels)))
print("Validation accuracy: {:.1f}%".format(
accuracy(valid_prediction.eval(), valid_labels)))
print("\nTest accuracy: {:.1f}%".format(
accuracy(test_prediction.eval(), test_labels)))
Producción:
Initialized Minibatch loss at step 0: 11.68728256225586 Minibatch accuracy: 10.2% Validation accuracy: 14.3% Minibatch loss at step 500: 2.239773750305176 Minibatch accuracy: 46.9% Validation accuracy: 67.6% Minibatch loss at step 1000: 1.0917563438415527 Minibatch accuracy: 78.1% Validation accuracy: 75.0% Minibatch loss at step 1500: 0.6598564386367798 Minibatch accuracy: 78.9% Validation accuracy: 78.6% Minibatch loss at step 2000: 0.24766433238983154 Minibatch accuracy: 91.4% Validation accuracy: 81.0% Minibatch loss at step 2500: 0.6181786060333252 Minibatch accuracy: 84.4% Validation accuracy: 82.5% Minibatch loss at step 3000: 0.9605385065078735 Minibatch accuracy: 85.2% Validation accuracy: 83.9% Minibatch loss at step 3500: 0.6315320730209351 Minibatch accuracy: 85.2% Validation accuracy: 84.4% Minibatch loss at step 4000: 0.812285840511322 Minibatch accuracy: 82.8% Validation accuracy: 85.0% Minibatch loss at step 4500: 0.5949224233627319 Minibatch accuracy: 80.5% Validation accuracy: 85.6% Minibatch loss at step 5000: 0.47554320096969604 Minibatch accuracy: 89.1% Validation accuracy: 86.2% Test accuracy: 86.5%
Algunos puntos importantes a tener en cuenta:
- En cada iteración, se selecciona un minilote eligiendo un valor de desplazamiento aleatorio usando el método np.random.randint .
- Para alimentar los marcadores de posición tf_train_dataset y tf_train_label , creamos un feed_dict como este:
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels} - Una forma abreviada de realizar un paso de cálculo es:
_, l, predictions = session.run([optimizer, loss, train_prediction], feed_dict=feed_dict)
Este Node devuelve los nuevos valores de pérdida y predicciones después de realizar el paso de optimización.
Esto nos lleva al final de la implementación. El código completo se puede encontrar aquí .
Finalmente, aquí hay algunos puntos para reflexionar:
- Puede intentar modificar los parámetros como la tasa de aprendizaje, el tamaño del lote, el número de épocas, etc. y lograr mejores resultados. También puede probar un optimizador diferente como tf.train.AdamOptimizer .
- La precisión del modelo anterior se puede mejorar mediante el uso de una red neuronal con una o más capas ocultas. Discutiremos su implementación usando TensorFlow en algunos artículos próximos.
- Regresión Softmax frente a clasificadores binarios k
Uno debe ser consciente de los escenarios en los que funciona la regresión softmax y en los que no. En muchos casos, es posible que necesite usar k clasificadores logísticos binarios diferentes para cada uno de los k valores posibles de la etiqueta de clase.Suponga que está trabajando en un problema de visión por computadora en el que intenta clasificar las imágenes en tres clases diferentes:
Caso 1: Suponga que sus clases son escena_interior, escena_urbana_exterior y escena_natural_exterior.
Caso 2: suponga que sus clases son escena_interior, imagen_en_blanco_y_negro e imagen_tiene_personas.
¿En qué caso usaría el clasificador de regresión Softmax y en qué caso usaría 3 clasificadores de regresión logística binaria ?
Esto dependerá de si las 3 clases son mutuamente excluyentes.
En el caso 1 , una escena puede ser indoor_scene, outdoor_urban_scene o outdoor_wilderness_scene. Entonces, asumiendo que cada ejemplo de entrenamiento está etiquetado exactamente con una de las 3 clases, deberíamos construir un clasificador softmax con k = 3.
Sin embargo, en el caso 2 , las clases no son mutuamente excluyentes ya que una escena puede ser interior y tener personas en ella. Entonces, en este caso, sería más apropiado construir 3 clasificadores de regresión logística binaria. De esta manera, para cada nueva escena, su algoritmo puede decidir por separado si cae en cada una de las 3 categorías.
Referencias:
- http://www.kdnuggets.com/2016/07/softmax-regression-related-logistic-regression.html
- https://classroom.udacity.com/courses/ud730
- http://ufldl.stanford.edu/wiki/index.php/Softmax_Regression
Este artículo es una contribución de Nikhil Kumar . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA