La regresión polinomial es una forma de regresión lineal en la que la relación entre la variable independiente x y la variable dependiente y se modela como un polinomio de grado n. La regresión polinomial ajusta una relación no lineal entre el valor de x y la media condicional correspondiente de y, indicada como E(y|x). Básicamente agrega los términos cuadráticos o polinómicos a la regresión. Generalmente, este tipo de regresión se usa para una variable resultante y un predictor.
Necesidad de regresión polinomial
- A diferencia del conjunto de datos lineales, si uno intenta aplicar un modelo lineal en un conjunto de datos no lineales sin ninguna modificación, habrá un resultado muy insatisfactorio y drástico.
- Esto puede provocar un aumento de la función de pérdida, una disminución de la precisión y una alta tasa de error.
- A diferencia del modelo lineal, el modelo polinomial cubre más puntos de datos.
Aplicaciones de la regresión polinomial
Generalmente, la regresión polinomial se utiliza en los siguientes escenarios:
- Tasa de crecimiento de los tejidos.
- Progresión de las epidemias relacionadas con la enfermedad.
- Fenómeno de distribución de los isótopos de carbono en sedimentos lacustres.
Explicación de la regresión polinomial en la programación R
La regresión polinomial también se conoce como regresión lineal polinomial, ya que depende de los coeficientes dispuestos linealmente en lugar de las variables. En R , si uno quiere implementar la regresión polinomial, debe instalar los siguientes paquetes:
- paquete tidyverse para una mejor visualización y manipulación.
- Paquete de intercalación para un flujo de trabajo de aprendizaje automático más fluido y sencillo.
Después de la instalación adecuada de los paquetes, es necesario configurar los datos correctamente. Para eso, primero se necesita dividir los datos en dos conjuntos (conjunto de entrenamiento y conjunto de prueba). Entonces uno puede visualizar los datos en varias parcelas. En R, para ajustar una regresión polinomial, primero se deben generar números pseudoaleatorios usando la función set.seed(n) .
La regresión polinómica agrega términos polinómicos o cuadráticos a la ecuación de regresión de la siguiente manera:
medv = b0 + b1 * lstat + b2 * lstat 2
dónde
mdev: es el valor medio de la casa
lstat: es la variable predictora
En R, para crear un predictor x 2 se debe usar la función I() , de la siguiente manera: I(x 2 ) . Esto eleva x a la potencia 2. La regresión polinomial se puede calcular en R de la siguiente manera:
lm(medv ~ lstat + I(lstat^2), data = train.data)
Para el siguiente ejemplo, tomemos el conjunto de datos de Boston del paquete MASS.
Ejemplo:
r
# R program to illustrate
# Polynomial regression
# Importing required library
library(tidyverse)
library(caret)
theme_set(theme_classic())
# Load the data
data("Boston", package = "MASS")
# Split the data into training and test set
set.seed(123)
training.samples <- Boston$medv %>%
createDataPartition(p = 0.8, list = FALSE)
train.data <- Boston[training.samples, ]
test.data <- Boston[-training.samples, ]
# Build the model
model <- lm(medv ~ poly(lstat, 5, raw = TRUE),
data = train.data)
# Make predictions
predictions <- model %>% predict(test.data)
# Model performance
modelPerfomance = data.frame(
RMSE = RMSE(predictions, test.data$medv),
R2 = R2(predictions, test.data$medv)
)
print(lm(medv ~ lstat + I(lstat^2), data = train.data))
print(modelPerfomance)
Producción:
Call:
lm(formula = medv ~ lstat + I(lstat^2), data = train.data)
Coefficients:
(Intercept) lstat I(lstat^2)
42.5736 -2.2673 0.0412
RMSE R2
1 5.270374 0.6829474
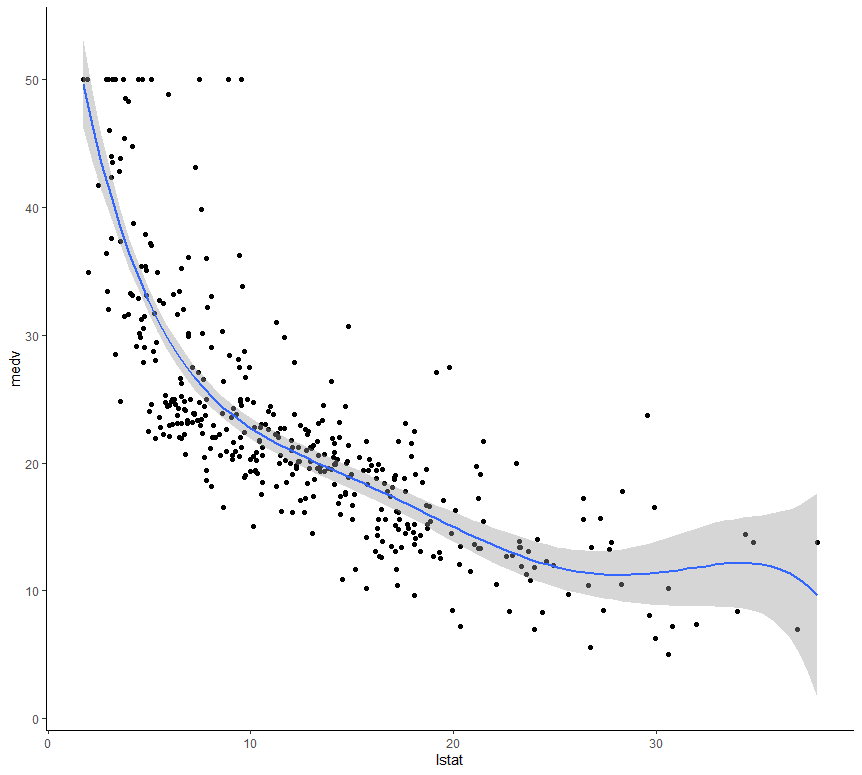
Trazado gráfico de regresión polinomial
En R, si uno quiere trazar un gráfico para la salida generada al implementar la regresión polinomial, puede usar la función ggplot() .
Ejemplo:
r
# R program to illustrate
# Graph plotting in
# Polynomial regression
# Importing required library
library(tidyverse)
library(caret)
theme_set(theme_classic())
# Load the data
data("Boston", package = "MASS")
# Split the data into training and test set
set.seed(123)
training.samples <- Boston$medv %>%
createDataPartition(p = 0.8, list = FALSE)
train.data <- Boston[training.samples, ]
test.data <- Boston[-training.samples, ]
# Build the model
model <- lm(medv ~ poly(lstat, 5, raw = TRUE), data = train.data)
# Make predictions
predictions <- model %>% predict(test.data)
# Model performance
data.frame(RMSE = RMSE(predictions, test.data$medv),
R2 = R2(predictions, test.data$medv))
ggplot(train.data, aes(lstat, medv) ) + geom_point() +
stat_smooth(method = lm, formula = y ~ poly(x, 5, raw = TRUE))
Producción: