El aprendizaje automático es un subconjunto de la inteligencia artificial que proporciona a una máquina la capacidad de aprender automáticamente sin ser programada explícitamente. La máquina en tales casos mejora a partir de la experiencia sin intervención humana y ajusta las acciones en consecuencia. Es principalmente de 3 tipos:
K-vecinos más cercanos
El algoritmo K-vecino más cercano crea un límite imaginario para clasificar los datos. Cuando se agregan nuevos puntos de datos para la predicción, el algoritmo agrega ese punto a la línea límite más cercana. Sigue el principio de » Los pájaros del mismo plumaje vuelan juntos «. Este algoritmo se puede implementar fácilmente en el lenguaje R.
Algoritmo K-NN
- Seleccione K, el número de vecinos.
- Calcula la distancia euclidiana del número K de vecinos.
- Tome los K vecinos más cercanos según la distancia euclidiana calculada.
- Cuente el número de puntos de datos en cada categoría entre estos K vecinos.
- El nuevo punto de datos se asigna a la categoría para la cual el número del vecino es máximo.
Implementación en R
El conjunto de datos: una población de muestra de 400 personas compartió su edad, sexo y salario con una empresa de productos, y si compraron el producto o no (0 significa no, 1 significa sí). Descargue el conjunto de datos Advert.csv
R
# Importing the dataset
dataset = read.csv('Advertisement.csv')
head(dataset, 10)
Producción:
| ID de usuario | Género | Años | Salario Estimado | comprado | |
| 0 | 15624510 | Masculino | 19 | 19000 | 0 |
| 1 | 15810944 | Masculino | 35 | 20000 | 0 |
| 2 | 15668575 | Femenino | 26 | 43000 | 0 |
| 3 | 15603246 | Femenino | 27 | 57000 | 0 |
| 4 | 15804002 | Masculino | 19 | 76000 | 0 |
| 5 | 15728773 | Masculino | 27 | 58000 | 0 |
| 6 | 15598044 | Femenino | 27 | 84000 | 0 |
| 7 | 15694829 | Femenino | 32 | 150000 | 1 |
| 8 | 15600575 | Masculino | 25 | 33000 | 0 |
| 9 | 15727311 | Femenino | 35 | 65000 | 0 |
R
# Encoding the target
# feature as factor
dataset$Purchased = factor(dataset$Purchased,
levels = c(0, 1))
# Splitting the dataset into
# the Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$Purchased,
SplitRatio = 0.75)
training_set = subset(dataset,
split == TRUE)
test_set = subset(dataset,
split == FALSE)
# Feature Scaling
training_set[-3] = scale(training_set[-3])
test_set[-3] = scale(test_set[-3])
# Fitting K-NN to the Training set
# and Predicting the Test set results
library(class)
y_pred = knn(train = training_set[, -3],
test = test_set[, -3],
cl = training_set[, 3],
k = 5,
prob = TRUE)
# Making the Confusion Matrix
cm = table(test_set[, 3], y_pred)
- El conjunto de entrenamiento contiene 300 entradas.
- El conjunto de prueba contiene 100 entradas.
Confusion matrix result: [[64][4] [3][29]]
Visualización de los datos de entrenamiento:
R
# Visualising the Training set results
# Install ElemStatLearn if not present
# in the packages using(without hashtag)
# install.packages('ElemStatLearn')
library(ElemStatLearn)
set = training_set
#Building a grid of Age Column(X1)
# and Estimated Salary(X2) Column
X1 = seq(min(set[, 1]) - 1,
max(set[, 1]) + 1,
by = 0.01)
X2 = seq(min(set[, 2]) - 1,
max(set[, 2]) + 1,
by = 0.01)
grid_set = expand.grid(X1, X2)
# Give name to the columns of matrix
colnames(grid_set) = c('Age',
'EstimatedSalary')
# Predicting the values and plotting
# them to grid and labelling the axes
y_grid = knn(train = training_set[, -3],
test = grid_set,
cl = training_set[, 3],
k = 5)
plot(set[, -3],
main = 'K-NN (Training set)',
xlab = 'Age', ylab = 'Estimated Salary',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid),
length(X1), length(X2)),
add = TRUE)
points(grid_set, pch = '.',
col = ifelse(y_grid == 1,
'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1,
'green4', 'red3'))
Producción:

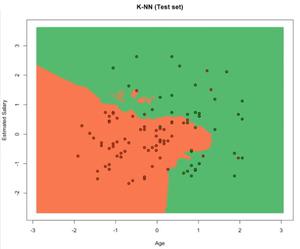
Visualización de los datos de prueba:
R
# Visualising the Test set results
library(ElemStatLearn)
set = test_set
# Building a grid of Age Column(X1)
# and Estimated Salary(X2) Column
X1 = seq(min(set[, 1]) - 1,
max(set[, 1]) + 1,
by = 0.01)
X2 = seq(min(set[, 2]) - 1,
max(set[, 2]) + 1,
by = 0.01)
grid_set = expand.grid(X1, X2)
# Give name to the columns of matrix
colnames(grid_set) = c('Age',
'EstimatedSalary')
# Predicting the values and plotting
# them to grid and labelling the axes
y_grid = knn(train = training_set[, -3],
test = grid_set,
cl = training_set[, 3], k = 5)
plot(set[, -3],
main = 'K-NN (Test set)',
xlab = 'Age', ylab = 'Estimated Salary',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid),
length(X1), length(X2)),
add = TRUE)
points(grid_set, pch = '.', col =
ifelse(y_grid == 1,
'springgreen3', 'tomato'))
points(set, pch = 21, bg =
ifelse(set[, 3] == 1,
'green4', 'red3'))
Producción:
Ventajas
- No hay período de entrenamiento.
- KNN es un algoritmo de aprendizaje basado en instancias, por lo tanto, un aprendiz perezoso.
- KNN no deriva ninguna función discriminatoria de la tabla de entrenamiento, tampoco hay período de entrenamiento.
- KNN almacena el conjunto de datos de entrenamiento y lo usa para hacer predicciones en tiempo real.
- Los nuevos datos se pueden agregar sin problemas y no afectarán la precisión del algoritmo, ya que no se necesita capacitación para los datos recién agregados.
- Solo se requieren dos parámetros para implementar el algoritmo KNN, es decir, el valor de K y la función de distancia euclidiana.
Desventajas
- El costo de calcular la distancia entre cada punto existente y el nuevo punto es enorme en el nuevo conjunto de datos, lo que reduce el rendimiento del algoritmo.
- Se vuelve difícil para el algoritmo calcular la distancia en cada dimensión porque el algoritmo no funciona bien con datos de alta dimensión, es decir, datos con una gran cantidad de características.
- Existe la necesidad de escalar características (estandarización y normalización) antes de aplicar el algoritmo KNN a cualquier conjunto de datos, de lo contrario, KNN puede generar predicciones incorrectas.
- KNN es sensible al ruido en los datos.