El análisis de regresión es una herramienta estadística para estimar la relación entre dos o más variables. Siempre hay una variable de respuesta y una o más variables predictoras. El análisis de regresión se usa ampliamente para ajustar los datos en consecuencia y más, prediciendo los datos para la previsión. Ayuda a las empresas y organizaciones a conocer el comportamiento de su producto en el mercado utilizando la variable dependiente/respuesta y la variable independiente/predictora. En este artículo, aprendamos sobre los diferentes tipos de regresión en la programación R con la ayuda de ejemplos.
Tipos de regresión en R
Hay principalmente tres tipos de regresión en la programación R que se usan ampliamente. Están:
Regresión lineal
El modelo de regresión lineal es uno de los más utilizados entre los tres tipos de regresión. En la regresión lineal, la relación se estima entre dos variables, es decir, una variable de respuesta y una variable de predicción. La regresión lineal produce una línea recta en el gráfico. Matemáticamente

dónde,
- x indica predictor o variable independiente
- y indica respuesta o variable dependiente
- a y b son coeficientes
Implementación en R
En la programación R, la función lm() se usa para crear un modelo de regresión lineal.
Sintaxis: lm (fórmula)
Parámetro:
fórmula: representa la fórmula en la que se deben ajustar los datos Para conocer más parámetros opcionales, use el siguiente comando en la consola: ayuda («lm»)
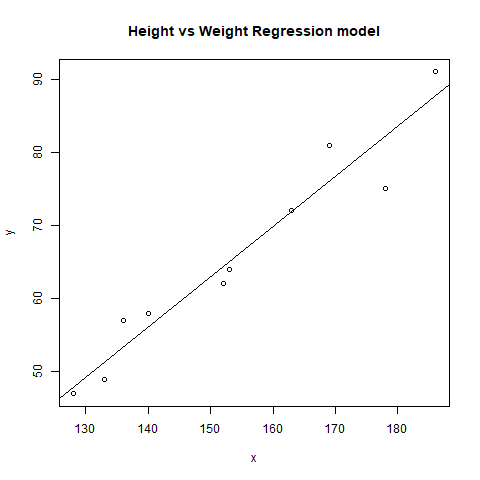
Ejemplo: En este ejemplo, tracemos la línea de regresión lineal en el gráfico y predigamos el peso usando la altura.
R
# R program to illustrate
# Linear Regression
# Height vector
x <- c(153, 169, 140, 186, 128,
136, 178, 163, 152, 133)
# Weight vector
y <- c(64, 81, 58, 91, 47, 57,
75, 72, 62, 49)
# Create a linear regression model
model <- lm(y~x)
# Print regression model
print(model)
# Find the weight of a person
# With height 182
df <- data.frame(x = 182)
res <- predict(model, df)
cat("\nPredicted value of a person
with height = 182")
print(res)
# Output to be present as PNG file
png(file = "linearRegGFG.png")
# Plot
plot(x, y, main = "Height vs Weight
Regression model")
abline(lm(y~x))
# Save the file.
dev.off()
Producción:
Call:
lm(formula = y ~ x)
Coefficients:
(Intercept) x
-39.7137 0.6847
Predicted value of a person with height = 182
1
84.9098
Regresión múltiple
La regresión múltiple es otro tipo de técnica de análisis de regresión que es una extensión del modelo de regresión lineal, ya que utiliza más de una variable predictora para crear el modelo. Matemáticamente,

Implementación en R
La regresión múltiple en la programación R usa la misma función lm() para crear el modelo.
Sintaxis: lm(fórmula, datos)
Parámetros:
- fórmula: representa la fórmula en la que se deben ajustar los datos
- datos: representa el marco de datos en el que se debe aplicar la fórmula
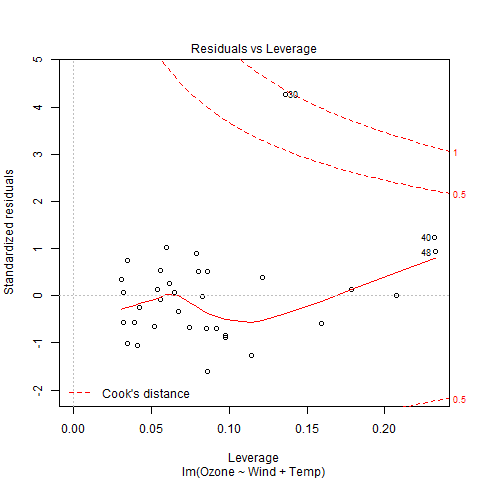
Ejemplo: Vamos a crear un modelo de regresión múltiple del conjunto de datos de calidad del aire presente en el paquete base R y trazar el modelo en el gráfico.
R
# R program to illustrate
# Multiple Linear Regression
# Using airquality dataset
input <- airquality[1:50,
c("Ozone", "Wind", "Temp")]
# Create regression model
model <- lm(Ozone~Wind + Temp,
data = input)
# Print the regression model
cat("Regression model:\n")
print(model)
# Output to be present as PNG file
png(file = "multipleRegGFG.png")
# Plot
plot(model)
# Save the file.
dev.off()
Producción:
Regression model:
Call:
lm(formula = Ozone ~ Wind + Temp, data = input)
Coefficients:
(Intercept) Wind Temp
-58.239 -0.739 1.329
Regresión logística
La regresión logística es otra técnica de análisis de regresión ampliamente utilizada y predice el valor con un rango. Además, se utiliza para predecir los valores de los datos categóricos. Por ejemplo, el correo electrónico es spam o no spam, ganador o perdedor, hombre o mujer, etc. Matemáticamente,

dónde,
- y representa la variable de respuesta
- z representa la ecuación de variables independientes o características
Implementación en R
En la programación R, la función glm() se usa para crear un modelo de regresión logística.
Sintaxis: glm(fórmula, datos, familia)
Parámetros:
- fórmula: representa una fórmula sobre la base de qué modelo debe ajustarse
- datos: representa el marco de datos en el que se debe aplicar la fórmula
- familia: representa el tipo de función a utilizar. “binomial” para regresión logística
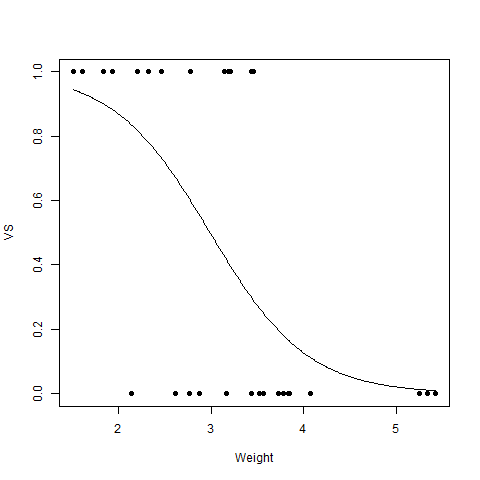
Ejemplo:
R
# R program to illustrate # Logistic Regression # Using mtcars dataset # To create the logistic model model <- glm(formula = vs ~ wt, family = binomial, data = mtcars) # Creating a range of wt values x <- seq(min(mtcars$wt), max(mtcars$wt), 0.01) # Predict using weight y <- predict(model, list(wt = x), type = "response") # Print model print(model) # Output to be present as PNG file png(file = "LogRegGFG.png") # Plot plot(mtcars$wt, mtcars$vs, pch = 16, xlab = "Weight", ylab = "VS") lines(x, y) # Saving the file dev.off()
Producción:
Call: glm(formula = vs ~ wt, family = binomial, data = mtcars)
Coefficients:
(Intercept) wt
5.715 -1.911
Degrees of Freedom: 31 Total (i.e. Null); 30 Residual
Null Deviance: 43.86
Residual Deviance: 31.37 AIC: 35.37
Publicación traducida automáticamente
Artículo escrito por utkarsh_kumar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA