La regularización es una forma de técnica de regresión que reduce, regulariza o restringe las estimaciones del coeficiente hacia 0 (o cero). En esta técnica, se agrega una penalización a los diversos parámetros del modelo para reducir la libertad del modelo dado. El concepto de Regularización se puede clasificar a grandes rasgos en:
Implementación en R
En el lenguaje R , para realizar la Regularización necesitamos instalar un puñado de paquetes antes de comenzar a trabajar en ellos. Los paquetes requeridos son
- paquete glmnet para regresión de cresta y regresión de lazo
- paquete dplyr para limpieza de datos
- paquete psych para realizar o calcular la función de seguimiento de una array
- paquete de intercalación
Para instalar estos paquetes tenemos que usar install.packages() en R Console. Después de instalar los paquetes con éxito, incluimos estos paquetes en nuestro R Script usando el comando library() . Para implementar la técnica de regresión de Regularización necesitamos seguir cualquiera de los tres tipos de técnicas de regularización.
Regresión de cresta
La Regresión Ridge es una versión modificada de la regresión lineal y también se conoce como Regularización L2 . A diferencia de la regresión lineal, la función de pérdida se modifica para minimizar la complejidad del modelo y esto se hace agregando algún parámetro de penalización que es equivalente al cuadrado del valor o magnitud del coeficiente. Básicamente, para implementar Ridge Regression en R vamos a utilizar el paquete “ glmnet ”. La función se utilizará para determinar la regresión de la cresta.
Ejemplo:
En este ejemplo, implementaremos la técnica de regresión de crestas en el conjunto de datos mtcars para una mejor ilustración. Nuestra tarea es predecir las millas por galón sobre la base de otras características de los automóviles. Vamos a usar la función para establecer la semilla para la reproducibilidad. Vamos a establecer el valor de lambda de tres maneras:
- realizando una validación cruzada de 10 veces
- en base a la información derivada
- lambda óptima basada en ambos criterios
R
# Regularization
# Ridge Regression in R
# Load libraries, get data & set
# seed for reproducibility
set.seed(123)
library(glmnet)
library(dplyr)
library(psych)
data("mtcars")
# Center y, X will be standardized
# in the modelling function
y <- mtcars %>% select(mpg) %>%
scale(center = TRUE, scale = FALSE) %>%
as.matrix()
X <- mtcars %>% select(-mpg) %>% as.matrix()
# Perform 10-fold cross-validation to select lambda
lambdas_to_try <- 10^seq(-3, 5, length.out = 100)
# Setting alpha = 0 implements ridge regression
ridge_cv <- cv.glmnet(X, y, alpha = 0,
lambda = lambdas_to_try,
standardize = TRUE, nfolds = 10)
# Plot cross-validation results
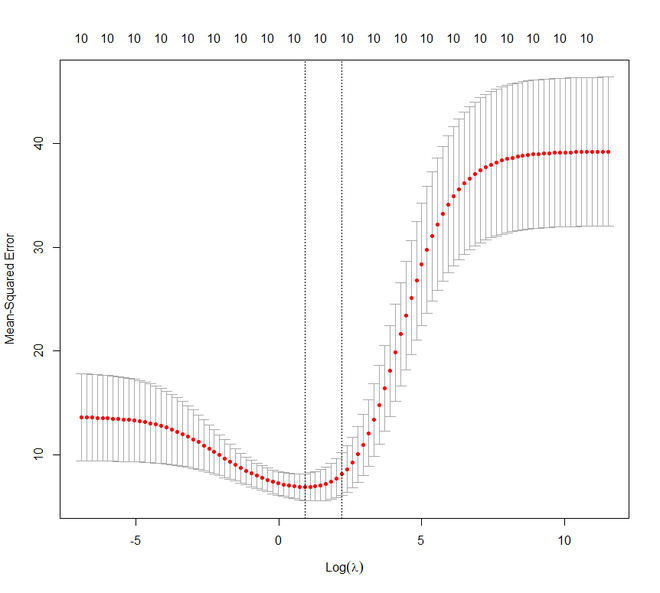
plot(ridge_cv)
# Best cross-validated lambda
lambda_cv <- ridge_cv$lambda.min
# Fit final model, get its sum of squared
# residuals and multiple R-squared
model_cv <- glmnet(X, y, alpha = 0, lambda = lambda_cv,
standardize = TRUE)
y_hat_cv <- predict(model_cv, X)
ssr_cv <- t(y - y_hat_cv) %*% (y - y_hat_cv)
rsq_ridge_cv <- cor(y, y_hat_cv)^2
# selecting lambda based on the information
X_scaled <- scale(X)
aic <- c()
bic <- c()
for (lambda in seq(lambdas_to_try))
{
# Run model
model <- glmnet(X, y, alpha = 0,
lambda = lambdas_to_try[lambda],
standardize = TRUE)
# Extract coefficients and residuals (remove first
# row for the intercept)
betas <- as.vector((as.matrix(coef(model))[-1, ]))
resid <- y - (X_scaled %*% betas)
# Compute hat-matrix and degrees of freedom
ld <- lambdas_to_try[lambda] * diag(ncol(X_scaled))
H <- X_scaled %*% solve(t(X_scaled) %*% X_scaled + ld)
%*% t(X_scaled)
df <- tr(H)
# Compute information criteria
aic[lambda] <- nrow(X_scaled) * log(t(resid) %*% resid)
+ 2 * df
bic[lambda] <- nrow(X_scaled) * log(t(resid) %*% resid)
+ 2 * df * log(nrow(X_scaled))
}
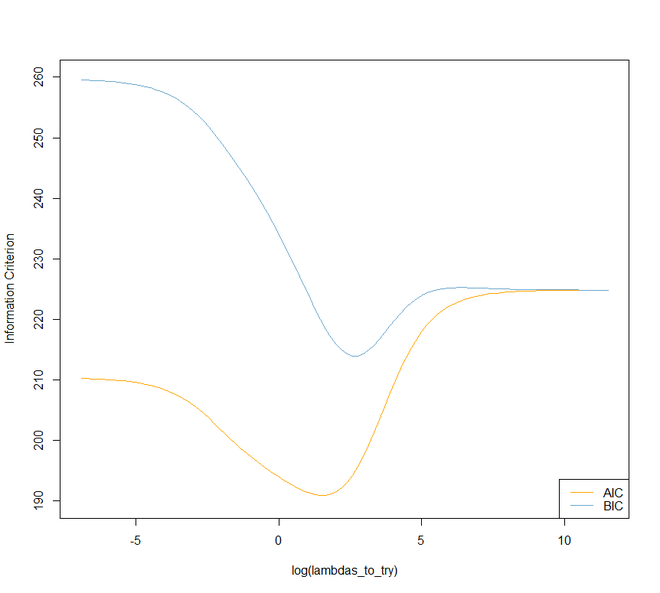
# Plot information criteria against tried values of lambdas
plot(log(lambdas_to_try), aic, col = "orange", type = "l",
ylim = c(190, 260), ylab = "Information Criterion")
lines(log(lambdas_to_try), bic, col = "skyblue3")
legend("bottomright", lwd = 1, col = c("orange", "skyblue3"),
legend = c("AIC", "BIC"))
# Optimal lambdas according to both criteria
lambda_aic <- lambdas_to_try[which.min(aic)]
lambda_bic <- lambdas_to_try[which.min(bic)]
# Fit final models, get their sum of
# squared residuals and multiple R-squared
model_aic <- glmnet(X, y, alpha = 0, lambda = lambda_aic,
standardize = TRUE)
y_hat_aic <- predict(model_aic, X)
ssr_aic <- t(y - y_hat_aic) %*% (y - y_hat_aic)
rsq_ridge_aic <- cor(y, y_hat_aic)^2
model_bic <- glmnet(X, y, alpha = 0, lambda = lambda_bic,
standardize = TRUE)
y_hat_bic <- predict(model_bic, X)
ssr_bic <- t(y - y_hat_bic) %*% (y - y_hat_bic)
rsq_ridge_bic <- cor(y, y_hat_bic)^2
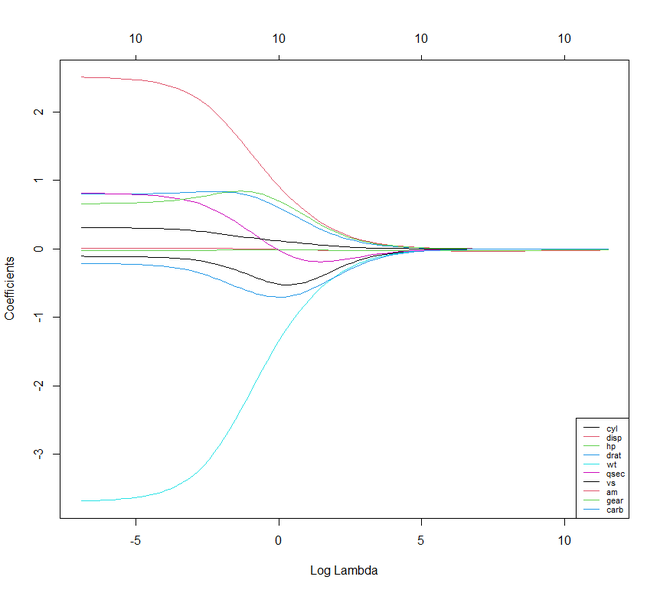
# The higher the lambda, the more the
# coefficients are shrinked towards zero.
res <- glmnet(X, y, alpha = 0, lambda = lambdas_to_try,
standardize = FALSE)
plot(res, xvar = "lambda")
legend("bottomright", lwd = 1, col = 1:6,
legend = colnames(X), cex = .7)
Producción:
Regresión de lazo
Avanzando hacia la regresión de Lasso . También se conoce como Regresión L1, Operador de selección y Contracción mínima absoluta. También es una versión modificada de Regresión lineal donde nuevamente se modifica la función de pérdida para minimizar la complejidad del modelo. Esto se hace limitando la suma de los valores absolutos de los coeficientes del modelo. En R, podemos implementar la regresión de lazo usando el mismo paquete » glmnet » como la regresión de cresta.
Ejemplo:
De nuevo en este ejemplo, estamos usando el conjunto de datos mtcars . Aquí también vamos a establecer el valor lambda como en el ejemplo anterior.
R
# Regularization
# Lasso Regression
# Load libraries, get data & set
# seed for reproducibility
set.seed(123)
library(glmnet)
library(dplyr)
library(psych)
data("mtcars")
# Center y, X will be standardized in the modelling function
y <- mtcars %>% select(mpg) %>% scale(center = TRUE,
scale = FALSE) %>%
as.matrix()
X <- mtcars %>% select(-mpg) %>% as.matrix()
# Perform 10-fold cross-validation to select lambda
lambdas_to_try <- 10^seq(-3, 5, length.out = 100)
# Setting alpha = 1 implements lasso regression
lasso_cv <- cv.glmnet(X, y, alpha = 1,
lambda = lambdas_to_try,
standardize = TRUE, nfolds = 10)
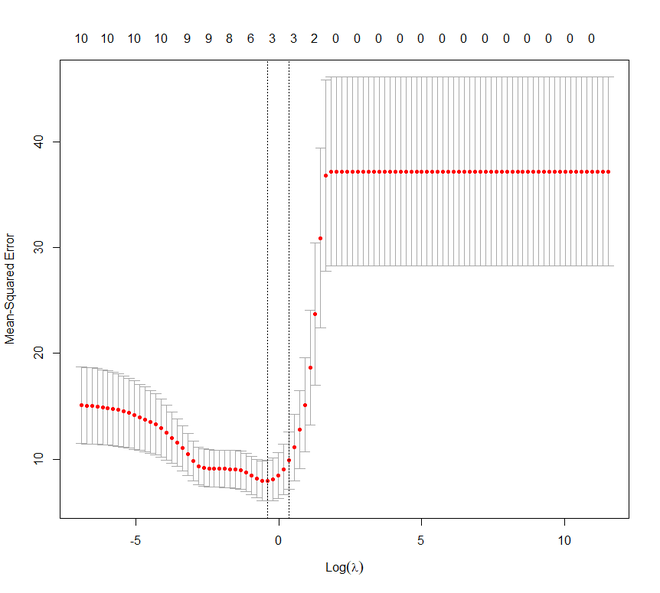
# Plot cross-validation results
plot(lasso_cv)
# Best cross-validated lambda
lambda_cv <- lasso_cv$lambda.min
# Fit final model, get its sum of squared
# residuals and multiple R-squared
model_cv <- glmnet(X, y, alpha = 1, lambda = lambda_cv,
standardize = TRUE)
y_hat_cv <- predict(model_cv, X)
ssr_cv <- t(y - y_hat_cv) %*% (y - y_hat_cv)
rsq_lasso_cv <- cor(y, y_hat_cv)^2
# The higher the lambda, the more the
# coefficients are shrinked towards zero.
res <- glmnet(X, y, alpha = 1, lambda = lambdas_to_try,
standardize = FALSE)
plot(res, xvar = "lambda")
legend("bottomright", lwd = 1, col = 1:6,
legend = colnames(X), cex = .7)
Producción:
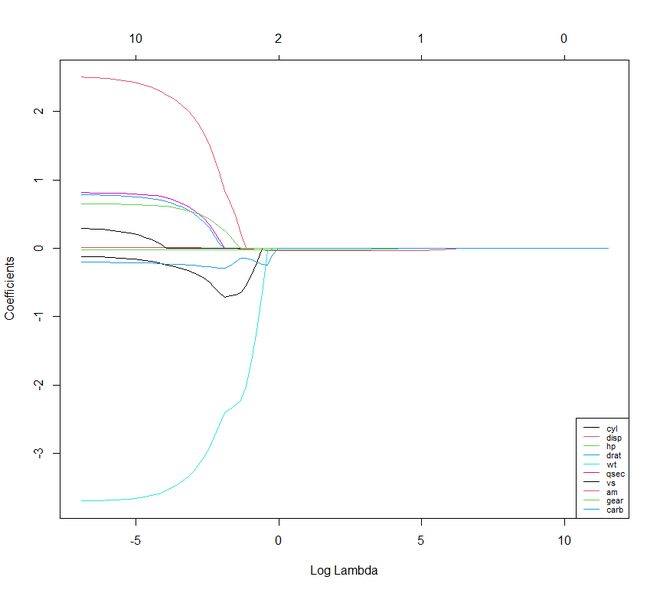
Si comparamos las técnicas de Lasso y Ridge Regression, notaremos que ambas técnicas son más o menos iguales. Pero hay pocas características en las que se diferencian entre sí.
- A diferencia de Ridge, Lasso puede establecer algunos de sus parámetros en cero.
- En ridge el coeficiente del predictor que está correlacionado es similar. Mientras que en lazo solo uno de los coeficientes del predictor es mayor y el resto tiende a cero.
- Ridge funciona bien si existen muchos parámetros enormes o grandes que tienen el mismo valor. Mientras que lasso funciona bien si existe solo un pequeño número de parámetros definidos o significativos y el resto tiende a cero.
Regresión neta elástica
Ahora pasaremos a la regresión neta elástica . La regresión neta elástica se puede establecer como la combinación convexa de la regresión de lazo y cresta. Incluso aquí podemos trabajar con el paquete glmnet . Pero ahora veremos cómo se puede usar el paquete caret para implementar la regresión de red elástica.
Ejemplo:
R
# Regularization
# Elastic Net Regression
library(caret)
# Set training control
train_control <- trainControl(method = "repeatedcv",
number = 5,
repeats = 5,
search = "random",
verboseIter = TRUE)
# Train the model
elastic_net_model <- train(mpg ~ .,
data = cbind(y, X),
method = "glmnet",
preProcess = c("center", "scale"),
tuneLength = 25,
trControl = train_control)
# Check multiple R-squared
y_hat_enet <- predict(elastic_net_model, X)
rsq_enet <- cor(y, y_hat_enet)^2
print(y_hat_enet)
print(rsq_enet)
Producción:
> print(y_hat_enet)
Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive Hornet Sportabout Valiant
2.13185747 1.76214273 6.07598463 0.50410531 -3.15668592 0.08734383
Duster 360 Merc 240D Merc 230 Merc 280 Merc 280C Merc 450SE
-5.23690809 2.82725225 2.85570982 -0.19421572 -0.16329225 -4.37306992
Merc 450SL Merc 450SLC Cadillac Fleetwood Lincoln Continental Chrysler Imperial Fiat 128
-3.83132657 -3.88886320 -8.00151118 -8.29125966 -8.08243188 6.98344302
Honda Civic Toyota Corolla Toyota Corona Dodge Challenger AMC Javelin Camaro Z28
8.30013895 7.74742320 3.93737683 -3.13404917 -2.56900144 -5.17326892
Pontiac Firebird Fiat X1-9 Porsche 914-2 Lotus Europa Ford Pantera L Ferrari Dino
-4.02993835 7.36692700 5.87750517 6.69642869 -2.02711333 0.06597788
Maserati Bora Volvo 142E
-5.90030273 4.83362156
> print(rsq_enet)
[,1]
mpg 0.8485501