En este artículo, discutiremos cómo resumir varias columnas de data.table por grupo en el lenguaje de programación R.
Creación de tabla para demostración:
R
# load data.table package
library("data.table")
# create data table with 3 columns
# items
# weight and #cost
data <- data.table( items= c("chocos","milk","drinks","drinks",
"milk","milk","chocos","milk",
"honey","honey"),
weight= c(10,20,34,23,12,45,23,
12,34,34),
cost= c(120,345,567,324,112,345,
678,100,45,67))
# display
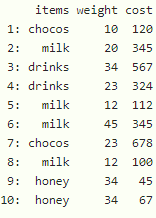
data
Producción:
Podemos resumir las múltiples columnas de 4 maneras:
- Al encontrar el promedio
- Al encontrar la suma
- Al encontrar el valor mínimo
- Al encontrar el valor máximo
podemos hacer esto usando la función lapply()
Sintaxis: datatable[, lapply(.SD, resumen_función), por = columna]
dónde
- datatable es la tabla de datos de entrada
- lpply() se usa para contener dos parámetros
- el primer parámetro es .SD es un objeto R estándar
- el segundo parámetro es una función de resumen que toma funciones de resumen para resumir la tabla de datos
- por es el nombre de la columna en la que se agrupan los datos en función de esta columna
Ejemplo 1: programa R para resumir la tabla de datos por suma y valor medio
R
# load data.table package
library("data.table")
# create data table with 3 columns
# items
# weight and #cost
data <- data.table( items= c("chocos","milk","drinks","drinks",
"milk","milk","chocos","milk",
"honey","honey"),
weight= c(10,20,34,23,12,45,23,
12,34,34),
cost= c(120,345,567,324,112,345,
678,100,45,67))
# group by sum with items column
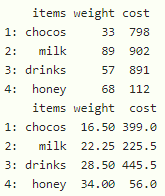
print(data[, lapply(.SD, sum), by = items])
# group by average with items column
print(data[, lapply(.SD, mean), by = items])
Producción:
Ejemplo 2: programa R para resumir la tabla de datos por valor mínimo y máximo
R
# load data.table package
library("data.table")
# create data table with 3 columns
# items weight and #cost
data <- data.table( items= c("chocos","milk","drinks","drinks",
"milk","milk","chocos","milk",
"honey","honey"),
weight= c(10,20,34,23,12,45,23,
12,34,34),
cost= c(120,345,567,324,112,345,
678,100,45,67))
# group by minimum with items column
print(data[, lapply(.SD, min), by = items])
# group by maximum with items column
print(data[, lapply(.SD, max), by = items])
Producción:
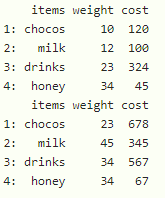
Publicación traducida automáticamente
Artículo escrito por gottumukkalabobby y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA