En este artículo, vamos a seleccionar columnas en el marco de datos según la condición usando la función where() en Pyspark.
Vamos a crear un marco de datos de muestra con datos de empleados.
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display dataframe
dataframe.show()
Producción:

El método where()
Este método se utiliza para devolver el marco de datos en función de la condición dada. Puede tomar una condición y devuelve el marco de datos.
Sintaxis:
where(dataframe.column condition)
- Aquí el marco de datos es el marco de datos de entrada
- La columna es el nombre de la columna donde tenemos que plantear una condición.
El método select()
Después de aplicar la cláusula where, seleccionaremos los datos del marco de datos
Sintaxis:
dataframe.select('column_name').where(dataframe.column condition)
- Aquí el marco de datos es el marco de datos de entrada
- La columna es el nombre de la columna donde tenemos que plantear una condición.
Ejemplo 1: programa de Python para devolver ID según la condición
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# select ID where ID less than 3
dataframe.select('ID').where(dataframe.ID < 3).show()
Producción:
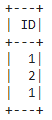
Ejemplo 2: Programa Python para seleccionar ID y nombre donde ID =4.
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# select ID and name where ID =4
dataframe.select(['ID', 'NAME']).where(dataframe.ID == 4).show()
Producción:

Ejemplo 3: programa de Python para seleccionar todas las columnas según la condición
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# select all columns e where name = sridevi
dataframe.select(['ID', 'NAME', 'Company']).where(
dataframe.NAME == 'sridevi').show()
Producción:

Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA