Mientras se preprocesan los datos con el marco de datos de pandas, es posible que sea necesario encontrar las filas que contienen texto específico. En este artículo, discutiremos métodos para encontrar las filas que contienen texto específico en las columnas o filas de un marco de datos en pandas.
Conjunto de datos en uso:
| trabajo | Rango de edad | Salario | Calificación crediticia | Ahorros | Buys_Hone |
|---|---|---|---|---|---|
| Propio | De edad mediana | Alto | Justa | 10000 | Sí |
| Gobierno | Joven | Bajo | Justa | 15000 | No |
| Privado | Sénior | Promedio | Excelente | 20000 | Sí |
| Propio | De edad mediana | Alto | Justa | 13000 | No |
| Propio | Joven | Bajo | Excelente | 17000 | Sí |
| Privado | Sénior | Promedio | Justa | 18000 | No |
| Gobierno | Joven | Promedio | Justa | 11000 | No |
| Privado | De edad mediana | Bajo | Excelente | 9000 | No |
| Gobierno | Sénior | Alto | Excelente | 14000 | Sí |
Método 1: Usar contiene()
Usando la función contains() de strings para filtrar las filas. Estamos filtrando las filas en función de la columna ‘Calificación crediticia’ del marco de datos convirtiéndolo en string seguido del método contiene de la clase de string. El método contains() toma un argumento y encuentra el patrón en los objetos que lo llaman.
Ejemplo:
Python3
# importing pandas as pd
import pandas as pd
# reading csv file
df = pd.read_csv("Assignment.csv")
# filtering the rows where Credit-Rating is Fair
df = df[df['Credit-Rating'].str.contains('Fair')]
print(df)
Producción :
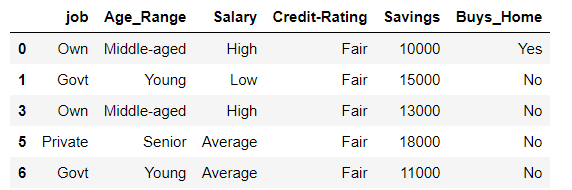
Filas que contienen Justo como Ahorro
Método 2: Usar itertuples()
Usar itertuples() para iterar filas con find para obtener filas que contengan el texto deseado. El método itertuple devuelve un iterador que produce una tupla con nombre para cada fila en el DataFrame. Funciona más rápido que el método iterrows() de pandas.
Ejemplo:
Python3
# importing pandas as pd
import pandas as pd
# reading csv file
df = pd.read_csv("Assignment.csv")
# filtering the rows where Age_Range contains Young
for x in df.itertuples():
if x[2].find('Young') != -1:
print(x)
Producción :
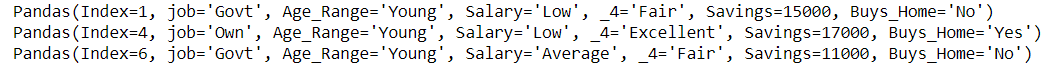
Filas con Age_Range como Young
Método 3: Usar iterrows()
Usar iterrows() para iterar filas con find para obtener filas que contengan el texto deseado. La función iterrows() devuelve el iterador que produce cada valor de índice junto con una serie que contiene los datos en cada fila. Es más lento en comparación con itertuples debido a la gran cantidad de verificación de tipos que realiza.
Ejemplo:
Python3
# importing pandas as pd
import pandas as pd
# reading csv file
df = pd.read_csv("Assignment.csv")
# filtering the rows where job is Govt
for index, row in df.iterrows():
if 'Govt' in row['job']:
print(index, row['job'], row['Age_Range'],
row['Salary'], row['Savings'], row['Credit-Rating'])
Producción :

Filas con trabajo como Gobierno
Método 4: Usar expresiones regulares
Usando expresiones regulares para encontrar las filas con el texto deseado. search() es un método del módulo re. re.search(patrón, string): Es similar a re.match() pero no nos limita a encontrar coincidencias solo al principio de la string. Estamos iterando sobre cada fila y comparando el trabajo en cada índice con ‘Gobierno’ para seleccionar solo esas filas.
Ejemplo:
Python3
# using regular expressions
from re import search
# import pandas as pd
import pandas as pd
# reading CSV file
df = pd.read_csv("Assignment.csv")
# iterating over rows with job as Govt and printing
for ind in df.index:
if search('Govt', df['job'][ind]):
print(df['job'][ind], df['Savings'][ind],
df['Age_Range'][ind], df['Credit-Rating'][ind])
Producción :

Filas donde el trabajo es Gobierno
Publicación traducida automáticamente
Artículo escrito por deveshkumarsharma y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA