Veamos cómo podemos seleccionar la fila con el valor máximo y mínimo en el marco de datos de Pandas con la ayuda de diferentes ejemplos.
Considere este conjunto de datos.
# importing pandas and numpy
import pandas as pd
import numpy as np
# data of 2018 drivers world championship
dict1 ={'Driver':['Hamilton', 'Vettel', 'Raikkonen',
'Verstappen', 'Bottas', 'Ricciardo',
'Hulkenberg', 'Perez', 'Magnussen',
'Sainz', 'Alonso', 'Ocon', 'Leclerc',
'Grosjean', 'Gasly', 'Vandoorne',
'Ericsson', 'Stroll', 'Hartley', 'Sirotkin'],
'Points':[408, 320, 251, 249, 247, 170, 69, 62, 56,
53, 50, 49, 39, 37, 29, 12, 9, 6, 4, 1],
'Age':[33, 31, 39, 21, 29, 29, 31, 28, 26, 24, 37,
22, 21, 32, 22, 26, 28, 20, 29, 23]}
# creating dataframe using DataFrame constructor
df = pd.DataFrame(dict1)
print(df.head(10))
Producción: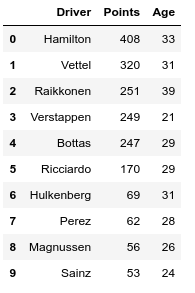
Usando max en Dataframe –
Código n.º 1: Muestra el máximo en las columnas Conductor, Puntos y Edad.
# importing pandas and numpy
import pandas as pd
import numpy as np
# data of 2018 drivers world championship
dict1 ={'Driver':['Hamilton', 'Vettel', 'Raikkonen',
'Verstappen', 'Bottas', 'Ricciardo',
'Hulkenberg', 'Perez', 'Magnussen',
'Sainz', 'Alonso', 'Ocon', 'Leclerc',
'Grosjean', 'Gasly', 'Vandoorne',
'Ericsson', 'Stroll', 'Hartley', 'Sirotkin'],
'Points':[408, 320, 251, 249, 247, 170, 69, 62, 56,
53, 50, 49, 39, 37, 29, 12, 9, 6, 4, 1],
'Age':[33, 31, 39, 21, 29, 29, 31, 28, 26, 24, 37,
22, 21, 32, 22, 26, 28, 20, 29, 23]}
# creating dataframe using DataFrame constructor
df = pd.DataFrame(dict1)
# the result shows max on
# Driver, Points, Age columns.
print(df.max())
Salida: 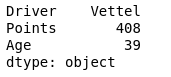
Código #2: Quién anotó el máximo de puntos
# importing pandas and numpy
import pandas as pd
import numpy as np
# data of 2018 drivers world championship
dict1 ={'Driver':['Hamilton', 'Vettel', 'Raikkonen',
'Verstappen', 'Bottas', 'Ricciardo',
'Hulkenberg', 'Perez', 'Magnussen',
'Sainz', 'Alonso', 'Ocon', 'Leclerc',
'Grosjean', 'Gasly', 'Vandoorne',
'Ericsson', 'Stroll', 'Hartley', 'Sirotkin'],
'Points':[408, 320, 251, 249, 247, 170, 69, 62, 56,
53, 50, 49, 39, 37, 29, 12, 9, 6, 4, 1],
'Age':[33, 31, 39, 21, 29, 29, 31, 28, 26, 24, 37,
22, 21, 32, 22, 26, 28, 20, 29, 23]}
# creating dataframe using DataFrame constructor
df = pd.DataFrame(dict1)
# Who scored more points ?
print(df[df.Points == df.Points.max()])
Producción:
Código #3: ¿Cuál es la edad máxima?
# importing pandas and numpy
import pandas as pd
import numpy as np
# data of 2018 drivers world championship
dict1 ={'Driver':['Hamilton', 'Vettel', 'Raikkonen',
'Verstappen', 'Bottas', 'Ricciardo',
'Hulkenberg', 'Perez', 'Magnussen',
'Sainz', 'Alonso', 'Ocon', 'Leclerc',
'Grosjean', 'Gasly', 'Vandoorne',
'Ericsson', 'Stroll', 'Hartley', 'Sirotkin'],
'Points':[408, 320, 251, 249, 247, 170, 69, 62, 56,
53, 50, 49, 39, 37, 29, 12, 9, 6, 4, 1],
'Age':[33, 31, 39, 21, 29, 29, 31, 28, 26, 24, 37,
22, 21, 32, 22, 26, 28, 20, 29, 23]}
# creating dataframe using DataFrame constructor
df = pd.DataFrame(dict1)
# what is the maximum age ?
print(df.Age.max())
Producción:![]()
Código n.º 4: qué fila tiene la edad máxima en el marco de datos | ¿Quién es el conductor más viejo?
# importing pandas and numpy
import pandas as pd
import numpy as np
# data of 2018 drivers world championship
dict1 ={'Driver':['Hamilton', 'Vettel', 'Raikkonen',
'Verstappen', 'Bottas', 'Ricciardo',
'Hulkenberg', 'Perez', 'Magnussen',
'Sainz', 'Alonso', 'Ocon', 'Leclerc',
'Grosjean', 'Gasly', 'Vandoorne',
'Ericsson', 'Stroll', 'Hartley', 'Sirotkin'],
'Points':[408, 320, 251, 249, 247, 170, 69, 62, 56,
53, 50, 49, 39, 37, 29, 12, 9, 6, 4, 1],
'Age':[33, 31, 39, 21, 29, 29, 31, 28, 26, 24, 37,
22, 21, 32, 22, 26, 28, 20, 29, 23]}
# creating dataframe using DataFrame constructor
df = pd.DataFrame(dict1)
# Which row has maximum age |
# who is the oldest driver ?
print(df[df.Age == df.Age.max()])
Producción:
Usando min en Dataframe –
Código n.º 1: Muestra min en las columnas Conductor, Puntos, Edad.
# importing pandas and numpy
import pandas as pd
import numpy as np
# data of 2018 drivers world championship
dict1 ={'Driver':['Hamilton', 'Vettel', 'Raikkonen',
'Verstappen', 'Bottas', 'Ricciardo',
'Hulkenberg', 'Perez', 'Magnussen',
'Sainz', 'Alonso', 'Ocon', 'Leclerc',
'Grosjean', 'Gasly', 'Vandoorne',
'Ericsson', 'Stroll', 'Hartley', 'Sirotkin'],
'Points':[408, 320, 251, 249, 247, 170, 69, 62, 56,
53, 50, 49, 39, 37, 29, 12, 9, 6, 4, 1],
'Age':[33, 31, 39, 21, 29, 29, 31, 28, 26, 24, 37,
22, 21, 32, 22, 26, 28, 20, 29, 23]}
# creating dataframe using DataFrame constructor
df = pd.DataFrame(dict1)
# the result shows min on
# Driver, Points, Age columns.
print(df.min())
Producción: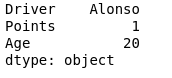
Código #2: Quién anotó menos puntos
# importing pandas and numpy
import pandas as pd
import numpy as np
# data of 2018 drivers world championship
dict1 ={'Driver':['Hamilton', 'Vettel', 'Raikkonen',
'Verstappen', 'Bottas', 'Ricciardo',
'Hulkenberg', 'Perez', 'Magnussen',
'Sainz', 'Alonso', 'Ocon', 'Leclerc',
'Grosjean', 'Gasly', 'Vandoorne',
'Ericsson', 'Stroll', 'Hartley', 'Sirotkin'],
'Points':[408, 320, 251, 249, 247, 170, 69, 62, 56,
53, 50, 49, 39, 37, 29, 12, 9, 6, 4, 1],
'Age':[33, 31, 39, 21, 29, 29, 31, 28, 26, 24, 37,
22, 21, 32, 22, 26, 28, 20, 29, 23]}
# creating dataframe using DataFrame constructor
df = pd.DataFrame(dict1)
# Who scored less points ?
print(df[df.Points == df.Points.min()])
Salida: 
Código n.º 3: qué fila tiene una edad mínima en el marco de datos | quien es el conductor mas joven
# importing pandas and numpy
import pandas as pd
import numpy as np
# data of 2018 drivers world championship
dict1 ={'Driver':['Hamilton', 'Vettel', 'Raikkonen',
'Verstappen', 'Bottas', 'Ricciardo',
'Hulkenberg', 'Perez', 'Magnussen',
'Sainz', 'Alonso', 'Ocon', 'Leclerc',
'Grosjean', 'Gasly', 'Vandoorne',
'Ericsson', 'Stroll', 'Hartley', 'Sirotkin'],
'Points':[408, 320, 251, 249, 247, 170, 69, 62, 56,
53, 50, 49, 39, 37, 29, 12, 9, 6, 4, 1],
'Age':[33, 31, 39, 21, 29, 29, 31, 28, 26, 24, 37,
22, 21, 32, 22, 26, 28, 20, 29, 23]}
# creating dataframe using DataFrame constructor
df = pd.DataFrame(dict1)
# Which row has maximum age |
# who is the youngest driver ?
print(df[df.Age == df.Age.min()])
Producción: