Requisito previo: multiprocesamiento en Python | Conjunto 1 , Conjunto 2
Este artículo analiza dos conceptos importantes relacionados con el multiprocesamiento en Python:
- Sincronización entre procesos
- Agrupación de procesos
Sincronización entre procesos
La sincronización de procesos se define como un mecanismo que asegura que dos o más procesos concurrentes no ejecuten simultáneamente algún segmento de programa en particular conocido como sección crítica .
La sección crítica se refiere a las partes del programa donde se accede al recurso compartido.
Por ejemplo, en el siguiente diagrama, 3 procesos intentan acceder al recurso compartido o a la sección crítica al mismo tiempo.
Los accesos simultáneos a recursos compartidos pueden conducir a una condición de carrera .
Una condición de carrera ocurre cuando dos o más procesos pueden acceder a datos compartidos e intentan cambiarlos al mismo tiempo. Como resultado, los valores de las variables pueden ser impredecibles y variar según los tiempos de los cambios de contexto de los procesos.
Considere el siguiente programa para comprender el concepto de condición de carrera:
# Python program to illustrate
# the concept of race condition
# in multiprocessing
import multiprocessing
# function to withdraw from account
def withdraw(balance):
for _ in range(10000):
balance.value = balance.value - 1
# function to deposit to account
def deposit(balance):
for _ in range(10000):
balance.value = balance.value + 1
def perform_transactions():
# initial balance (in shared memory)
balance = multiprocessing.Value('i', 100)
# creating new processes
p1 = multiprocessing.Process(target=withdraw, args=(balance,))
p2 = multiprocessing.Process(target=deposit, args=(balance,))
# starting processes
p1.start()
p2.start()
# wait until processes are finished
p1.join()
p2.join()
# print final balance
print("Final balance = {}".format(balance.value))
if __name__ == "__main__":
for _ in range(10):
# perform same transaction process 10 times
perform_transactions()
Si ejecuta el programa anterior, obtendrá algunos valores inesperados como este:
Final balance = 1311 Final balance = 199 Final balance = 558 Final balance = -2265 Final balance = 1371 Final balance = 1158 Final balance = -577 Final balance = -1300 Final balance = -341 Final balance = 157
En el programa anterior, se realizan 10000 retiros y 10000 transacciones de depósito con un saldo inicial de 100. El saldo final esperado es 100, pero lo que obtenemos en 10 iteraciones de la función perform_transactions son algunos valores diferentes.
Esto sucede debido al acceso simultáneo de procesos al saldo de datos compartidos . Esta imprevisibilidad en el valor del equilibrio no es más que una condición de carrera .
Tratemos de entenderlo mejor usando los diagramas de secuencia que se dan a continuación. Estas son las diferentes secuencias que se pueden producir en el ejemplo anterior para una sola acción de retiro y depósito.
- Esta es una secuencia posible que da una respuesta incorrecta ya que ambos procesos leen el mismo valor y lo escriben de nuevo en consecuencia.
p1 p2 balance lectura (equilibrio)
actual = 100100 lectura (equilibrio)
actual = 100100 saldo=actual-1=99
escribir(saldo)99 saldo=actual+1=101
escribir(saldo)101 - Estas son 2 secuencias posibles que se desean en el escenario anterior.
p1 p2 balance lectura (equilibrio)
actual = 100100 saldo=actual-1=99
escribir(saldo)99 lectura (saldo)
actual = 9999 saldo=actual+1=100
escribir(saldo)100 p1 p2 balance lectura (equilibrio)
actual = 100100 saldo=actual+1=101
escribir(saldo)101 lectura (equilibrio)
actual = 101101 balance=actual-1=100
escribir(saldo)100
Uso de candados
El módulo de multiprocesamiento proporciona una clase de bloqueo para hacer frente a las condiciones de carrera. El bloqueo se implementa mediante un objeto Semaphore proporcionado por el sistema operativo.
Un semáforo es un objeto de sincronización que controla el acceso de múltiples procesos a un recurso común en un entorno de programación paralelo. Es simplemente un valor en un lugar designado en el almacenamiento del sistema operativo (o kernel) que cada proceso puede verificar y luego cambiar. Dependiendo del valor que se encuentre, el proceso puede usar el recurso o encontrará que ya está en uso y debe esperar un tiempo antes de volver a intentarlo. Los semáforos pueden ser binarios (0 o 1) o pueden tener valores adicionales. Por lo general, un proceso que usa semáforos verifica el valor y luego, si usa el recurso, cambia el valor para reflejar esto, de modo que los usuarios de semáforos posteriores sepan que deben esperar.
Considere el ejemplo dado a continuación:
# Python program to illustrate
# the concept of locks
# in multiprocessing
import multiprocessing
# function to withdraw from account
def withdraw(balance, lock):
for _ in range(10000):
lock.acquire()
balance.value = balance.value - 1
lock.release()
# function to deposit to account
def deposit(balance, lock):
for _ in range(10000):
lock.acquire()
balance.value = balance.value + 1
lock.release()
def perform_transactions():
# initial balance (in shared memory)
balance = multiprocessing.Value('i', 100)
# creating a lock object
lock = multiprocessing.Lock()
# creating new processes
p1 = multiprocessing.Process(target=withdraw, args=(balance,lock))
p2 = multiprocessing.Process(target=deposit, args=(balance,lock))
# starting processes
p1.start()
p2.start()
# wait until processes are finished
p1.join()
p2.join()
# print final balance
print("Final balance = {}".format(balance.value))
if __name__ == "__main__":
for _ in range(10):
# perform same transaction process 10 times
perform_transactions()
Producción:
Final balance = 100 Final balance = 100 Final balance = 100 Final balance = 100 Final balance = 100 Final balance = 100 Final balance = 100 Final balance = 100 Final balance = 100 Final balance = 100
Tratemos de entender el código anterior paso a paso:
- En primer lugar, se crea un objeto Lock usando:
lock = multiprocessing.Lock()
- Luego, el bloqueo se pasa como argumento de la función de destino:
p1 = multiprocessing.Process(target=withdraw, args=(balance,lock)) p2 = multiprocessing.Process(target=deposit, args=(balance,lock))
- En la sección crítica de la función de destino, aplicamos el bloqueo mediante el método lock.acquire() . Tan pronto como se adquiere un bloqueo, ningún otro proceso puede acceder a su sección crítica hasta que se libera el bloqueo mediante el método lock.release() .
lock.acquire() balance.value = balance.value - 1 lock.release()
Como puede ver en los resultados, el saldo final siempre es 100 (que es el resultado final esperado).
Agrupación entre procesos
Consideremos un programa simple para encontrar cuadrados de números en una lista dada.
# Python program to find # squares of numbers in a given list def square(n): return (n*n) if __name__ == "__main__": # input list mylist = [1,2,3,4,5] # empty list to store result result = [] for num in mylist: result.append(square(num)) print(result)
Producción:
[1, 4, 9, 16, 25]
Es un programa simple para calcular cuadrados de elementos de una lista dada. En un sistema multinúcleo/multiprocesador, considere el siguiente diagrama para comprender cómo funcionará el programa anterior:
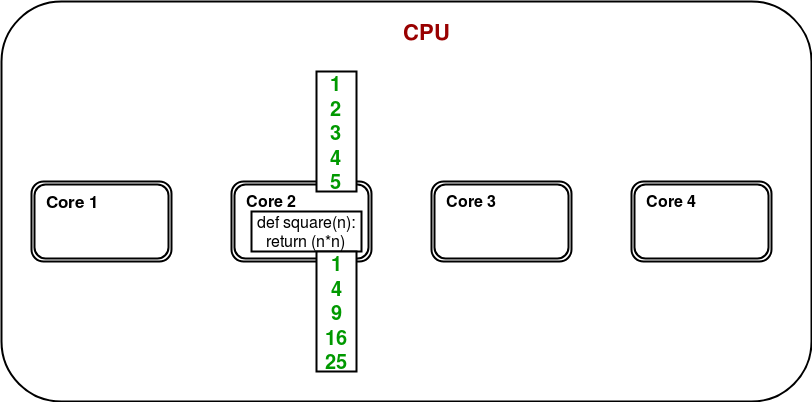
Solo uno de los núcleos se usa para la ejecución del programa y es muy posible que otros núcleos permanezcan inactivos.
Para utilizar todos los núcleos, el módulo de multiprocesamiento proporciona una clase Pool . La clase Pool representa un grupo de procesos de trabajo. Tiene métodos que permiten descargar tareas a los procesos de trabajo de diferentes maneras. Considere el siguiente diagrama:
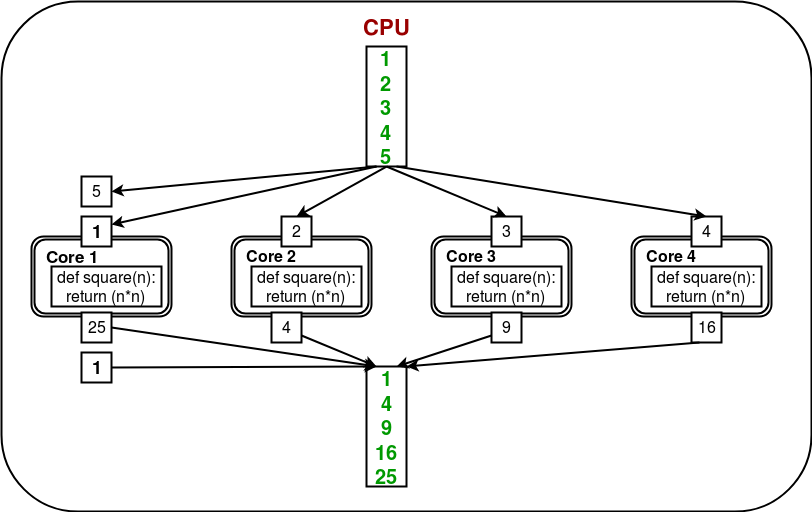
Aquí, la tarea se descarga/distribuye entre los núcleos/procesos automáticamente por el objeto Pool . El usuario no necesita preocuparse por crear procesos explícitamente.
Considere el programa dado a continuación:
# Python program to understand
# the concept of pool
import multiprocessing
import os
def square(n):
print("Worker process id for {0}: {1}".format(n, os.getpid()))
return (n*n)
if __name__ == "__main__":
# input list
mylist = [1,2,3,4,5]
# creating a pool object
p = multiprocessing.Pool()
# map list to target function
result = p.map(square, mylist)
print(result)
Producción:
Worker process id for 2: 4152 Worker process id for 1: 4151 Worker process id for 4: 4151 Worker process id for 3: 4153 Worker process id for 5: 4152 [1, 4, 9, 16, 25]
Tratemos de entender el código anterior paso a paso:
- Creamos un objeto Pool usando:
p = multiprocessing.Pool()Hay algunos argumentos para obtener más control sobre la descarga de tareas. Estos son:
- procesos: especifique el número de procesos de trabajo.
- maxtasksperchild: especifique el número máximo de tareas que se asignarán por niño.
Se puede hacer que todos los procesos en un grupo realicen alguna inicialización usando estos argumentos:
- initializer: especifique una función de inicialización para los procesos de trabajo.
- initargs: argumentos que se pasarán al inicializador.
- Ahora, para realizar alguna tarea, tenemos que asignarla a alguna función. En el ejemplo anterior, asignamos mylist a la función cuadrada . Como resultado, el contenido de mylist y la definición de cuadrado se distribuirán entre los núcleos.
result = p.map(square, mylist) - Una vez que todos los procesos de trabajo terminan su tarea, se devuelve una lista con el resultado final.
Este artículo es una contribución de Nikhil Kumar . Si le gusta GeeksforGeeks y le gustaría contribuir, también puede escribir un artículo usando contribuya.geeksforgeeks.org o envíe su artículo por correo a contribuya@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA