Planteamiento del Problema: La tarea es construir un detector de intrusiones en la red, un modelo predictivo capaz de distinguir entre malas conexiones, llamadas intrusiones o ataques , y buenas conexiones normales.
Introducción: el
sistema de detección de intrusiones es una aplicación de software para detectar intrusiones en la red utilizando varios algoritmos de aprendizaje automático. IDS monitorea una red o sistema en busca de actividad maliciosa y protege una red informática del acceso no autorizado de los usuarios, incluido quizás el personal interno. La tarea de aprendizaje del detector de intrusos es construir un modelo predictivo (es decir, un clasificador) capaz de distinguir entre ‘malas conexiones’ (intrusión/ataques) y ‘buenas conexiones (normales)’.
Los ataques se dividen en cuatro categorías principales:
- #DOS: denegación de servicio, por ejemplo, syn flood;
- #R2L: acceso no autorizado desde una máquina remota, por ejemplo, adivinar la contraseña;
- #U2R: acceso no autorizado a privilegios de superusuario local (raíz), por ejemplo, varios ataques de «desbordamiento de búfer»;
- #probing: vigilancia y otro sondeo, por ejemplo, escaneo de puertos.
Conjunto de datos utilizado : conjunto de datos de la Copa KDD 1999
Descripción del conjunto de datos: Archivos de datos:
- kddcup.names: una lista de características.
- kddcup.data.gz : El conjunto de datos completo
- kddcup.data_10_percent.gz : Un subconjunto del 10 %.
- kddcup.newtestdata_10_percent_unlabeled.gz
- kddcup.testdata.unlabeled.gz
- kddcup.testdata.unlabeled_10_percent.gz
- corregido.gz: datos de prueba con etiquetas corregidas.
- training_attack_types: una lista de tipos de intrusión.
- typo-correction.txt: una breve nota sobre un error tipográfico en el conjunto de datos que se ha corregido
Características:
| nombre de la función | descripción | escribe |
| duración | duración (número de segundos) de la conexión | continuo |
| tipo_de_protocolo | tipo de protocolo, por ejemplo, tcp, udp, etc. | discreto |
| Servicio | servicio de red en el destino, por ejemplo, http, telnet, etc. | discreto |
| src_bytes | número de bytes de datos desde el origen hasta el destino | continuo |
| dst_bytes | número de bytes de datos desde el destino hasta el origen | continuo |
| bandera | estado normal o de error de la conexión | discreto |
| tierra | 1 si la conexión es desde/hacia el mismo host/puerto; 0 de lo contrario | discreto |
| fragmento_equivocado | número de fragmentos «incorrectos» | continuo |
| urgente | número de paquetes urgentes | continuo |
Tabla 1: Características básicas de las conexiones TCP individuales.
| nombre de la función | descripción | escribe |
| caliente | número de indicadores «calientes» | continuo |
| num_failed_logins | número de intentos fallidos de inicio de sesión | continuo |
| conectado | 1 si inició sesión correctamente; 0 de lo contrario | discreto |
| num_comprometido | número de condiciones «comprometidas» | continuo |
| root_shell | 1 si se obtiene shell raíz; 0 de lo contrario | discreto |
| su_intentado | 1 si se intentó el comando «su root»; 0 de lo contrario | discreto |
| núm_raíz | número de accesos «root» | continuo |
| num_archivo_creaciones | número de operaciones de creación de archivos | continuo |
| num_shells | número de avisos de shell | continuo |
| num_acceso_archivos | número de operaciones en archivos de control de acceso | continuo |
| num_outbound_cmds | número de comandos salientes en una sesión ftp | continuo |
| is_hot_login | 1 si el inicio de sesión pertenece a la lista «caliente»; 0 de lo contrario | discreto |
| es_guest_login | 1 si el inicio de sesión es un inicio de sesión de «invitado»; 0 de lo contrario | discreto |
Tabla 2: Características del contenido dentro de una conexión sugerida por el conocimiento del dominio.
| nombre de la función | descripción | escribe |
| contar | número de conexiones al mismo host que la conexión actual en los últimos dos segundos | continuo |
| Nota: Las siguientes características se refieren a estas conexiones del mismo host. | ||
| tasa_serror | % de conexiones que tienen errores “SYN” | continuo |
| tasa_de_error | % de conexiones que tienen errores “REJ” | continuo |
| misma_tarifa_srv | % de conexiones al mismo servicio | continuo |
| diff_srv_rate | % de conexiones a diferentes servicios | continuo |
| srv_count | número de conexiones al mismo servicio que la conexión actual en los últimos dos segundos | continuo |
| Nota: Las siguientes características se refieren a estas conexiones del mismo servicio. | ||
| tasa_srv_serror | % de conexiones que tienen errores “SYN” | continuo |
| srv_rerror_tasa | % de conexiones que tienen errores “REJ” | continuo |
| tasa_host_diff_srv | % de conexiones a diferentes hosts | continuo |
Tabla 3: Características del tráfico calculadas utilizando una ventana de tiempo de dos segundos.
Varios algoritmos aplicados: Gaussian Naive Bayes, árbol de decisión, bosque aleatorio, máquina de vectores de soporte, regresión logística.
Enfoque utilizado: he aplicado varios algoritmos de clasificación que se mencionan anteriormente en el conjunto de datos KDD y comparo sus resultados para construir un modelo predictivo.
Paso 1 – Preprocesamiento de datos:
Código: Importación de bibliotecas y lista de funciones de lectura del archivo ‘kddcup.names’.
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import time
# reading features list
with open("..\\kddcup.names", 'r') as f:
print(f.read())
Código: agregar columnas al conjunto de datos y agregar un nuevo nombre de columna «objetivo» al conjunto de datos.
cols ="""duration,
protocol_type,
service,
flag,
src_bytes,
dst_bytes,
land,
wrong_fragment,
urgent,
hot,
num_failed_logins,
logged_in,
num_compromised,
root_shell,
su_attempted,
num_root,
num_file_creations,
num_shells,
num_access_files,
num_outbound_cmds,
is_host_login,
is_guest_login,
count,
srv_count,
serror_rate,
srv_serror_rate,
rerror_rate,
srv_rerror_rate,
same_srv_rate,
diff_srv_rate,
srv_diff_host_rate,
dst_host_count,
dst_host_srv_count,
dst_host_same_srv_rate,
dst_host_diff_srv_rate,
dst_host_same_src_port_rate,
dst_host_srv_diff_host_rate,
dst_host_serror_rate,
dst_host_srv_serror_rate,
dst_host_rerror_rate,
dst_host_srv_rerror_rate"""
columns =[]
for c in cols.split(', '):
if(c.strip()):
columns.append(c.strip())
columns.append('target')
print(len(columns))
Producción:
42
Código: Lectura del archivo ‘attack_types’.
with open("..\\training_attack_types", 'r') as f:
print(f.read())
Producción:
back dos buffer_overflow u2r ftp_write r2l guess_passwd r2l imap r2l ipsweep probe land dos loadmodule u2r multihop r2l neptune dos nmap probe perl u2r phf r2l pod dos portsweep probe rootkit u2r satan probe smurf dos spy r2l teardrop dos warezclient r2l warezmaster r2l
Código: Creación de un diccionario de tipos_de_ataque
attacks_types = {
'normal': 'normal',
'back': 'dos',
'buffer_overflow': 'u2r',
'ftp_write': 'r2l',
'guess_passwd': 'r2l',
'imap': 'r2l',
'ipsweep': 'probe',
'land': 'dos',
'loadmodule': 'u2r',
'multihop': 'r2l',
'neptune': 'dos',
'nmap': 'probe',
'perl': 'u2r',
'phf': 'r2l',
'pod': 'dos',
'portsweep': 'probe',
'rootkit': 'u2r',
'satan': 'probe',
'smurf': 'dos',
'spy': 'r2l',
'teardrop': 'dos',
'warezclient': 'r2l',
'warezmaster': 'r2l',
}
Código: leyendo el conjunto de datos (‘kddcup.data_10_percent.gz’) y agregando la función de tipo de ataque en el conjunto de datos de entrenamiento donde la función de tipo de ataque tiene 5 valores distintos, es decir, dos, normal, probe, r2l, u2r.
path = "..\\kddcup.data_10_percent.gz" df = pd.read_csv(path, names = columns) # Adding Attack Type column df['Attack Type'] = df.target.apply(lambda r:attacks_types[r[:-1]]) df.head()
Código: forma del marco de datos y obtener el tipo de datos de cada característica
df.shape
Producción:
(494021, 43)
Código: encontrar valores faltantes de todas las características.
df.isnull().sum()
Producción:
duration 0 protocol_type 0 service 0 flag 0 src_bytes 0 dst_bytes 0 land 0 wrong_fragment 0 urgent 0 hot 0 num_failed_logins 0 logged_in 0 num_compromised 0 root_shell 0 su_attempted 0 num_root 0 num_file_creations 0 num_shells 0 num_access_files 0 num_outbound_cmds 0 is_host_login 0 is_guest_login 0 count 0 srv_count 0 serror_rate 0 srv_serror_rate 0 rerror_rate 0 srv_rerror_rate 0 same_srv_rate 0 diff_srv_rate 0 srv_diff_host_rate 0 dst_host_count 0 dst_host_srv_count 0 dst_host_same_srv_rate 0 dst_host_diff_srv_rate 0 dst_host_same_src_port_rate 0 dst_host_srv_diff_host_rate 0 dst_host_serror_rate 0 dst_host_srv_serror_rate 0 dst_host_rerror_rate 0 dst_host_srv_rerror_rate 0 target 0 Attack Type 0 dtype: int64
No se encontró ningún valor faltante, por lo que podemos continuar con nuestro próximo paso.
Código: encontrar características categóricas
# Finding categorical features
num_cols = df._get_numeric_data().columns
cate_cols = list(set(df.columns)-set(num_cols))
cate_cols.remove('target')
cate_cols.remove('Attack Type')
cate_cols
Producción:
['service', 'flag', 'protocol_type']
Visualización de características categóricas mediante gráfico de barras
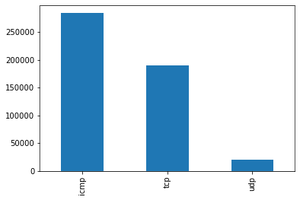
Tipo de protocolo: Notamos que ICMP es el más presente en los datos utilizados, luego TCP y casi 20000 paquetes de tipo UDP
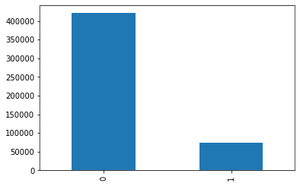
loged_in (1 si se inició sesión correctamente; 0 en caso contrario): notamos que solo 70000 paquetes se iniciaron correctamente.
Distribución de características de destino:
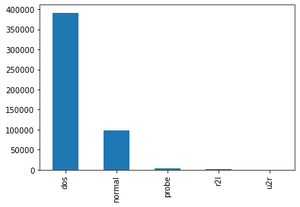
Tipo de ataque (los tipos de ataque agrupados por ataque, es lo que predeciremos)
Código: Correlación de datos: encuentre las variables altamente correlacionadas mediante el mapa de calor e ignórelas para el análisis.
df = df.dropna('columns')# drop columns with NaN
df = df[[col for col in df if df[col].nunique() > 1]]# keep columns where there are more than 1 unique values
corr = df.corr()
plt.figure(figsize =(15, 12))
sns.heatmap(corr)
plt.show()
Producción:
Código:
# This variable is highly correlated with num_compromised and should be ignored for analysis.
#(Correlation = 0.9938277978738366)
df.drop('num_root', axis = 1, inplace = True)
# This variable is highly correlated with serror_rate and should be ignored for analysis.
#(Correlation = 0.9983615072725952)
df.drop('srv_serror_rate', axis = 1, inplace = True)
# This variable is highly correlated with rerror_rate and should be ignored for analysis.
#(Correlation = 0.9947309539817937)
df.drop('srv_rerror_rate', axis = 1, inplace = True)
# This variable is highly correlated with srv_serror_rate and should be ignored for analysis.
#(Correlation = 0.9993041091850098)
df.drop('dst_host_srv_serror_rate', axis = 1, inplace = True)
# This variable is highly correlated with rerror_rate and should be ignored for analysis.
#(Correlation = 0.9869947924956001)
df.drop('dst_host_serror_rate', axis = 1, inplace = True)
# This variable is highly correlated with srv_rerror_rate and should be ignored for analysis.
#(Correlation = 0.9821663427308375)
df.drop('dst_host_rerror_rate', axis = 1, inplace = True)
# This variable is highly correlated with rerror_rate and should be ignored for analysis.
#(Correlation = 0.9851995540751249)
df.drop('dst_host_srv_rerror_rate', axis = 1, inplace = True)
# This variable is highly correlated with srv_rerror_rate and should be ignored for analysis.
#(Correlation = 0.9865705438845669)
df.drop('dst_host_same_srv_rate', axis = 1, inplace = True)
Producción:
Código: Mapeo de funciones: aplique el mapeo de funciones en funciones como: ‘protocol_type’ y ‘flag’.
# protocol_type feature mapping
pmap = {'icmp':0, 'tcp':1, 'udp':2}
df['protocol_type'] = df['protocol_type'].map(pmap)
Código:
# flag feature mapping
fmap = {'SF':0, 'S0':1, 'REJ':2, 'RSTR':3, 'RSTO':4, 'SH':5, 'S1':6, 'S2':7, 'RSTOS0':8, 'S3':9, 'OTH':10}
df['flag'] = df['flag'].map(fmap)
Producción:
Código: elimine características irrelevantes como ‘servicio’ antes de modelar
df.drop('service', axis = 1, inplace = True)
Paso 2 – Modelado
Código: importar bibliotecas y dividir el conjunto de datos
from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler
Código:
# Splitting the dataset df = df.drop(['target', ], axis = 1) print(df.shape) # Target variable and train set y = df[['Attack Type']] X = df.drop(['Attack Type', ], axis = 1) sc = MinMaxScaler() X = sc.fit_transform(X) # Split test and train data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.33, random_state = 42) print(X_train.shape, X_test.shape) print(y_train.shape, y_test.shape)
Producción:
(494021, 31) (330994, 30) (163027, 30) (330994, 1) (163027, 1)
Aplique varios algoritmos de clasificación de aprendizaje automático, como Support Vector Machines, Random Forest, Naive Bayes, Decision Tree, Logistic Regression para crear diferentes modelos.
Código: implementación de Python de Gaussian Naive Bayes
# Gaussian Naive Bayes
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
clfg = GaussianNB()
start_time = time.time()
clfg.fit(X_train, y_train.values.ravel())
end_time = time.time()
print("Training time: ", end_time-start_time)
Producción:
Training time: 1.1145250797271729
Código:
start_time = time.time()
y_test_pred = clfg.predict(X_train)
end_time = time.time()
print("Testing time: ", end_time-start_time)
Producción:
Testing time: 1.543299674987793
Código:
print("Train score is:", clfg.score(X_train, y_train))
print("Test score is:", clfg.score(X_test, y_test))
Producción:
Train score is: 0.8795114110829804 Test score is: 0.8790384414851528
Código: implementación de Python del árbol de decisión
# Decision Tree
from sklearn.tree import DecisionTreeClassifier
clfd = DecisionTreeClassifier(criterion ="entropy", max_depth = 4)
start_time = time.time()
clfd.fit(X_train, y_train.values.ravel())
end_time = time.time()
print("Training time: ", end_time-start_time)
Producción:
Training time: 2.4408750534057617
start_time = time.time()
y_test_pred = clfd.predict(X_train)
end_time = time.time()
print("Testing time: ", end_time-start_time)
Producción:
Testing time: 0.1487727165222168
print("Train score is:", clfd.score(X_train, y_train))
print("Test score is:", clfd.score(X_test, y_test))
Producción:
Train score is: 0.9905829108684749 Test score is: 0.9905230421954646
Código: implementación de código Python de Random Forest
from sklearn.ensemble import RandomForestClassifier
clfr = RandomForestClassifier(n_estimators = 30)
start_time = time.time()
clfr.fit(X_train, y_train.values.ravel())
end_time = time.time()
print("Training time: ", end_time-start_time)
Producción:
Training time: 17.084914684295654
start_time = time.time()
y_test_pred = clfr.predict(X_train)
end_time = time.time()
print("Testing time: ", end_time-start_time)
Producción:
Testing time: 0.1487727165222168
print("Train score is:", clfr.score(X_train, y_train))
print("Test score is:", clfr.score(X_test, y_test))
Producción:
Train score is: 0.99997583037759 Test score is: 0.9996933023364228
Código: implementación de Python del clasificador de vectores de soporte
from sklearn.svm import SVC
clfs = SVC(gamma = 'scale')
start_time = time.time()
clfs.fit(X_train, y_train.values.ravel())
end_time = time.time()
print("Training time: ", end_time-start_time)
Producción:
Training time: 218.26840996742249
Código:
start_time = time.time()
y_test_pred = clfs.predict(X_train)
end_time = time.time()
print("Testing time: ", end_time-start_time)
Producción:
Testing time: 126.5087513923645
Código:
print("Train score is:", clfs.score(X_train, y_train))
print("Test score is:", clfs.score(X_test, y_test))
Producción:
Train score is: 0.9987552644458811 Test score is: 0.9987916112055059
Código: implementación de Python de regresión logística
from sklearn.linear_model import LogisticRegression
clfl = LogisticRegression(max_iter = 1200000)
start_time = time.time()
clfl.fit(X_train, y_train.values.ravel())
end_time = time.time()
print("Training time: ", end_time-start_time)
Producción:
Training time: 92.94222283363342
Código:
start_time = time.time()
y_test_pred = clfl.predict(X_train)
end_time = time.time()
print("Testing time: ", end_time-start_time)
Producción:
Testing time: 0.09605908393859863
Código:
print("Train score is:", clfl.score(X_train, y_train))
print("Test score is:", clfl.score(X_test, y_test))
Producción:
Train score is: 0.9935285835997028 Test score is: 0.9935286792985211
Código: implementación de Python de Gradient Descent
from sklearn.ensemble import GradientBoostingClassifier
clfg = GradientBoostingClassifier(random_state = 0)
start_time = time.time()
clfg.fit(X_train, y_train.values.ravel())
end_time = time.time()
print("Training time: ", end_time-start_time)
Producción:
Training time: 633.2290260791779
start_time = time.time()
y_test_pred = clfg.predict(X_train)
end_time = time.time()
print("Testing time: ", end_time-start_time)
Producción:
Testing time: 2.9503915309906006
print("Train score is:", clfg.score(X_train, y_train))
print("Test score is:", clfg.score(X_test, y_test))
Producción:
Train score is: 0.9979304760811374 Test score is: 0.9977181693829856
Código: analice la precisión del entrenamiento y las pruebas de cada modelo.
names = ['NB', 'DT', 'RF', 'SVM', 'LR', 'GB'] values = [87.951, 99.058, 99.997, 99.875, 99.352, 99.793] f = plt.figure(figsize =(15, 3), num = 10) plt.subplot(131) plt.bar(names, values)
Producción: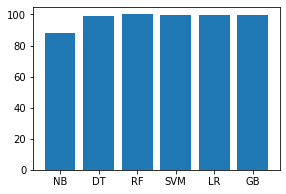
Código:
names = ['NB', 'DT', 'RF', 'SVM', 'LR', 'GB'] values = [87.903, 99.052, 99.969, 99.879, 99.352, 99.771] f = plt.figure(figsize =(15, 3), num = 10) plt.subplot(131) plt.bar(names, values)
Producción: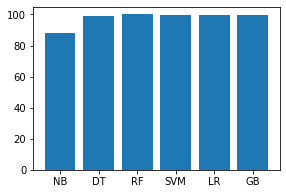
Código: Analiza el tiempo de entrenamiento y prueba de cada modelo.
names = ['NB', 'DT', 'RF', 'SVM', 'LR', 'GB'] values = [1.11452, 2.44087, 17.08491, 218.26840, 92.94222, 633.229] f = plt.figure(figsize =(15, 3), num = 10) plt.subplot(131) plt.bar(names, values)
Producción: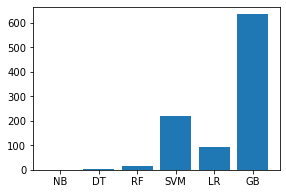
Código:
names = ['NB', 'DT', 'RF', 'SVM', 'LR', 'GB'] values = [1.54329, 0.14877, 0.199471, 126.50875, 0.09605, 2.95039] f = plt.figure(figsize =(15, 3), num = 10) plt.subplot(131) plt.bar(names, values)
Producción: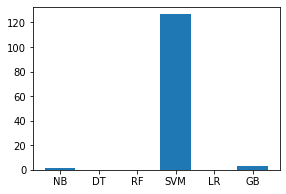
Enlace de implementación: https://github.com/mudgalabhay/intrusion-detection-system/blob/master/main.ipynb
Conclusión: el análisis anterior de diferentes modelos establece que el modelo del árbol de decisiones se ajusta mejor a nuestros datos teniendo en cuenta tanto la precisión como la complejidad del tiempo.
Enlaces: el código completo se carga en mi cuenta de github: https://github.com/mudgalabhay/intrusion-detection-system
Publicación traducida automáticamente
Artículo escrito por mudgalabhay57 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA