SQL Server es una base de datos versátil y es la base de datos relacional más utilizada en muchas industrias de software. En este artículo, veamos la tabla SQL Lock en SQL Server tomando algunos ejemplos prácticos. Como cumple con los requisitos de atomicidad (A), consistencia (C), aislamiento (I) y durabilidad (D), se denomina base de datos relacional. Para mantener los mecanismos ACID, en SQL Server se mantiene un bloqueo.
Al usar Azure Data Studio, veamos los conceptos del mecanismo de bloqueo comenzando con la creación de la base de datos, la creación de tablas, bloqueos, etc. Azure Data Studio funciona bien para entornos Windows 10, Mac y Linux. Se puede instalar desde aquí.
Creación de base de datos:
Comando para crear la base de datos. Aquí GEEKSFORGEEKS es el nombre de la base de datos.
--CREATE DATABASE <dbname>;
Crear base de datos GEEKSFORGEEKS:
Activar la base de datos
USE GEEKSFORGEEKS;

Una vez que la base de datos se activa, en la parte superior, se mostrará el nombre de la base de datos
Agregar las tablas a la base de datos:
Creación de una tabla con clave principal. Aquí ID es una CLAVE PRINCIPAL, lo que significa que cada autor tendrá su propia ID
CREATE TABLE Authors ( ID INT NOT NULL PRIMARY KEY, <other column name1> <datatype> <null/not null>, .......... );
Si se especifica explícitamente «NOT NULL», esa columna debe tener valores. Si no se especifica, por defecto es “NULL”.

La tabla con el nombre «Autores» se crea en la base de datos «GEEKSFORGEEKS»
Insertar filas en la tabla:
Habrá escenarios como que podemos agregar todas las columnas o algunos valores de columna a la tabla. El motivo es que algunas columnas pueden requerir valores nulos de forma predeterminada.
Ejemplo 1 :
INSERT INTO <table_name> (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);
Aquí estamos tomando en consideración las columnas mencionadas y, por lo tanto, solo los valores requeridos son insertados por la consulta anterior.
Ejemplo 2:
INSERT INTO <table_name> VALUES (value1, value2, value3, ...);
Aquí no estamos especificando ningún medio de columna, todos los valores de todas las columnas deben insertarse.
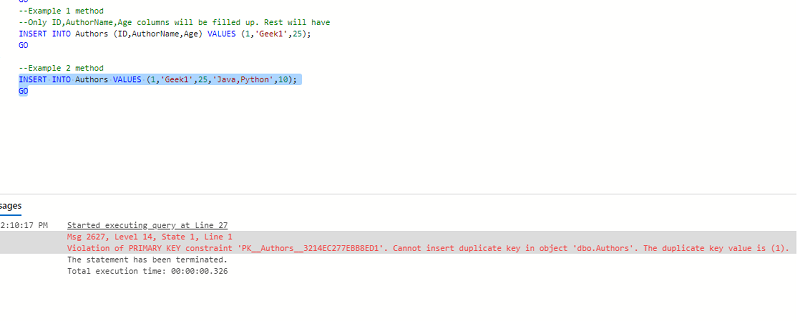
Violation of PRIMARY KEY constraint 'PK__Authors__3214EC277EBB8ED1'. Cannot insert duplicate key in object 'dbo.Authors'. The duplicate key value is (1).
Los errores anteriores ocurridos en la captura de pantalla anterior muestran que la columna «ID» es única y no debe tener valores duplicados
Ahora, corrijamos eso y consultemos la tabla usando:
SELECT * FROM <tablename>

Salida clara para los métodos aplicados del Ejemplo 1 y el Ejemplo 2
Se observa que la Fila 1 tiene valores ‘Nulos’ en lugar de las columnas ‘Conjuntos de habilidades’ y ‘Número de publicaciones’. La razón es que no hemos especificado valores para esas columnas, ha tomado valores nulos predeterminados.
- Bloqueos SQL:
SQL Server es una base de datos relacional, la consistencia de los datos es un mecanismo importante y se puede lograr mediante SQL Locks. Se establece un bloqueo en SQL Server cuando comienza una transacción y se libera cuando finaliza. Hay diferentes tipos de bloqueos.
- Bloqueos compartidos (S): cuando se necesita leer el objeto, se producirá este tipo de bloqueo, pero no es dañino.
- Bloqueos exclusivos (X): evita otras transacciones como insertar/actualizar/eliminar, etc. Por lo tanto, no se pueden realizar modificaciones en un objeto bloqueado.
- Bloqueos de actualización (U): más o menos similar al bloqueo exclusivo, pero aquí la operación se puede ver como «fase de lectura» y «fase de escritura». Especialmente durante la fase de lectura, se evitan otras transacciones.
- Bloqueos de intención: cuando SQL Server tiene el bloqueo compartido (S) o el bloqueo exclusivo (X) en una fila, entonces el bloqueo de intención está sobre la mesa.
- Bloqueos de intención regulares: Intención exclusiva (IX), Intención compartida (IS) e Intención de actualización (IU).
- Bloqueos de conversión: compartido con intención exclusiva (SIX), compartido con intención de actualización (SIU) y actualización con intención exclusiva (UIX).
La jerarquía de bloqueo comienza en la base de datos, luego en la tabla y luego en la fila.
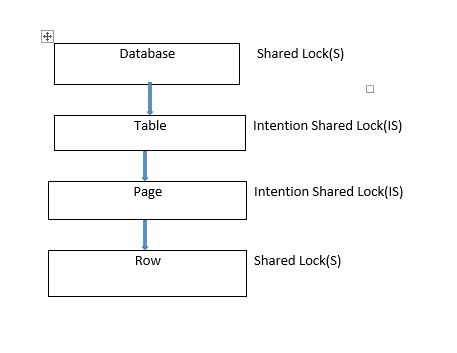
El bloqueo compartido a nivel de base de datos es muy importante ya que evita que se elimine la base de datos o que se restaure una copia de seguridad de la base de datos sobre la base de datos en uso.
Ocurrencias de bloqueo cuando se emite una instrucción «SELECT».
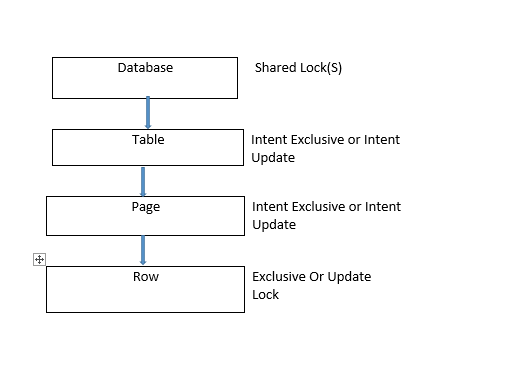
Durante la ejecución de la instrucción DML, es decir, durante la inserción/actualización/eliminación.
Con nuestro ejemplo, veamos los mecanismos de bloqueo.
--Let us create an open transaction and analyze the locked resource. BEGIN TRAN Let us update the Skillsets column for ID = 1 UPDATE Authors SET Skillsets='Java,Android,PHP' where ID=1 select @@SPID
![]()
select * from sys.dm_tran_locks WHERE request_session_id=<our session id. here it is 52>
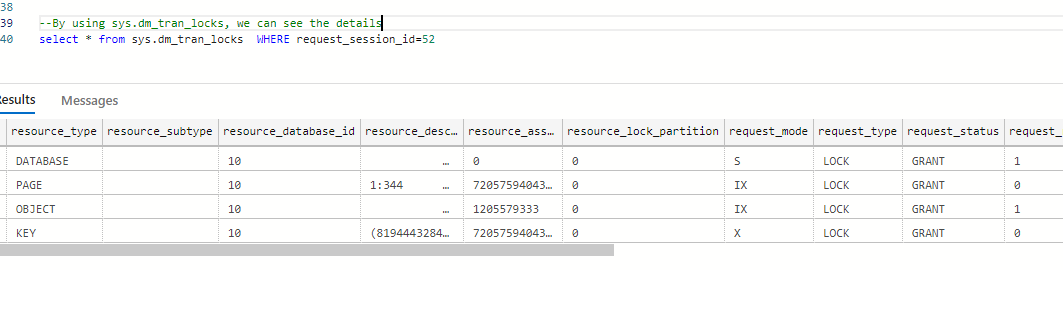
Insertemos algunos registros más (casi alrededor de 100 registros) en la tabla y luego, usando una transacción, actualicemos algunas columnas y apliquemos en paralelo la consulta de selección también.
--Let us create an open transaction and analyze the locked resources. BEGIN TRAN --Let us update the Skillsets when ID < 20 UPDATE Authors SET Skillsets='Java,Android,R Programming' where ID < 20 --Let us update the Skillsets when ID >= 25 UPDATE Authors SET Skillsets='Android,IOS,R Programming' where ID >= 25 --Other DML statements like Update/Delete. This statement must be taking a long time --(if there are huge updates are happening) as previous statement itself --is either not committed or rolled back yet SELECT * FROM Authors; select @@SPID
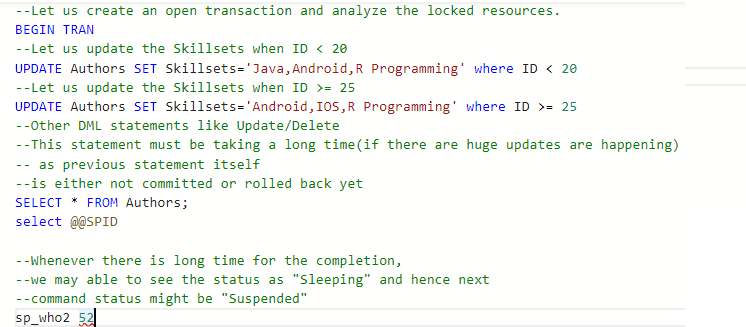
En realidad, cuando la transacción de comando anterior aún no está completa (si hay registros enormes, al menos 100 registros) y la actualización se realiza en todas y cada una de las filas y antes de completarla, si estamos procediendo con otro conjunto de comandos como «seleccionar»
Luego, hay posibilidades de que el estado sea «En espera» (Consultas que se están ejecutando) y «Suspendido» (Consultas que están detenidas)
¿Cómo superar el proceso en ejecución hasta ahora?
KILL <spid> -> Kill the session
(O) Dentro de una transacción, después de cada consulta, aplicar
COMMIT -> TO COMMIT THE CHANGES ROLLBACK -> TO ROLLBACK THE CHANGES
Al hacer este proceso, estamos haciendo cumplir la operación para que se comprometa o se revierta (depende de los requisitos, debe llevarse a cabo)
Pero a menos que sepamos que se requiere todo el proceso o no, no podemos confirmar ni revertir la transacción.
Manera alternativa :
Al usar NOLOCK con SELECT QUERY, podemos superar
SELECT * FROM Authors WITH (NOLOCK);
Para el estado de la declaración SELECT usando el comando sp_who2. La consulta se ejecuta sin esperar a que la transacción UPDATE se complete con éxito y libere el bloqueo en la tabla,
SELECT * FROM Authors WITH (READUNCOMMITTED); --This way also we can do
Conclusión :
Los bloqueos de SQL son muy importantes para cualquier RDBMS. SQL Server los maneja de las maneras mencionadas.
Publicación traducida automáticamente
Artículo escrito por priyarajtt y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA