Pandas proporciona varias estructuras de datos y operaciones para manipular datos numéricos y series temporales. Sin embargo, puede haber casos en los que falten algunos datos. En Pandas, los datos que faltan están representados por dos valores:
- Ninguno: Ninguno es un objeto único de Python que a menudo se usa para datos faltantes en el código de Python.
- NaN: NaN (un acrónimo de Not a Number), es un valor de punto flotante especial reconocido por todos los sistemas que usan la representación de punto flotante estándar IEEE
Los pandas tratan a Noney NaNcomo esencialmente intercambiables para indicar valores faltantes o nulos. Para eliminar valores nulos de un marco de datos, utilizamos dropna()esta función para eliminar filas/columnas de conjuntos de datos con valores nulos de diferentes maneras.
Sintaxis:
DataFrame.dropna(axis=0, how=’any’, thresh=Ninguno, subconjunto=Ninguno, inplace=False)Parámetros:
eje: el eje toma un valor int o de string para filas/columnas. La entrada puede ser 0 o 1 para Integer y ‘index’ o ‘columns’ para String.
how: how toma valor de string de solo dos tipos (‘cualquiera’ o ‘todos’). ‘cualquiera’ descarta la fila/columna si CUALQUIER valor es nulo y ‘todos’ descarta solo si TODOS los valores son nulos.
Thresh: Thresh toma un valor entero que indica la cantidad mínima de valores na que deben caer.
subconjunto: es una array que limita el proceso de eliminación a filas/columnas pasadas a través de la lista.
inplace: es un valor booleano que realiza los cambios en el marco de datos si es verdadero.
Código n. ° 1: eliminar filas con al menos 1 valor nulo.
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
df
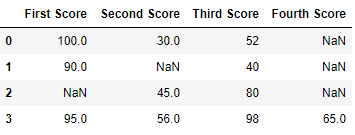
Now we drop rows with at least one Nan value (Null value)
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
# using dropna() function
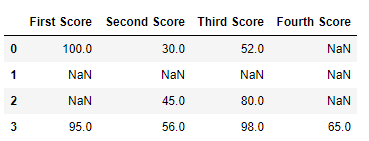
df.dropna()
Salida: 
Código #2: Eliminar filas si faltan todos los valores en esa fila.
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
df
Now we drop a rows whose all data is missing or contain null values(NaN)
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
# using dropna() function
df.dropna(how = 'all')
Producción: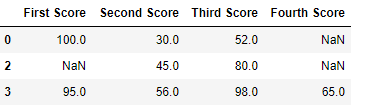
Código n. ° 3: descartar columnas con al menos 1 valor nulo.
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[60, 67, 68, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
df
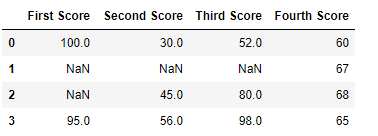
Now we drop a columns which have at least 1 missing values
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[60, 67, 68, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
# using dropna() function
df.dropna(axis = 1)
Producción :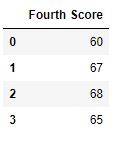
Código n.° 4: filas descartadas con al menos 1 valor nulo en el archivo CSV.
Nota: En esto, estamos usando un archivo CSV, para descargar el archivo CSV usado, haga clic aquí .
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# making new data frame with dropped NA values
new_data = data.dropna(axis = 0, how ='any')
new_data
Salida: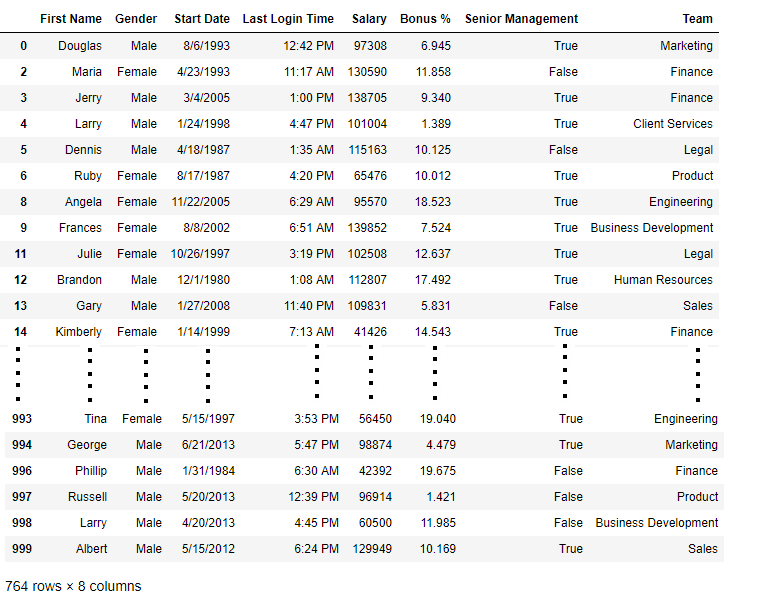
ahora comparamos los tamaños de los marcos de datos para que podamos saber cuántas filas tenían al menos 1 valor nulo
print("Old data frame length:", len(data))
print("New data frame length:", len(new_data))
print("Number of rows with at least 1 NA value: ",
(len(data)-len(new_data)))
Producción :
Old data frame length: 1000 New data frame length: 764 Number of rows with at least 1 NA value: 236
Dado que la diferencia es 236, había 236 filas que tenían al menos 1 valor nulo en cualquier columna.