En este artículo, vamos a colocar las filas en el marco de datos de PySpark. Consideraremos las condiciones más comunes, como eliminar filas con valores nulos, eliminar filas duplicadas, etc. Todas estas condiciones usan diferentes funciones y las discutiremos en detalle.
Cubriremos los siguientes temas:
- Suelte filas con condición usando las palabras clave where() y filter().
- Soltar filas con NA o valores faltantes
- Soltar filas con valores nulos
- Eliminar filas duplicadas.
- Eliminar filas duplicadas según la columna
Creando Dataframe para demostración:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of students data
data = [["1", "sravan", "vignan"],
["2", "ojaswi", "vvit"],
["3", "rohith", "vvit"],
["4", "sridevi", "vignan"],
["6", "ravi", "vrs"],
["5", "gnanesh", "iit"]]
# specify column names
columns = ['ID', 'NAME', 'college']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
print('Actual data in dataframe')
dataframe.show()
Producción:

Soltar filas con condición usando la función where() y filter()
Aquí vamos a soltar la fila con la condición usando las funciones where() y filter().
where(): Esta función se utiliza para comprobar la condición y dar los resultados. Eso significa que elimina las filas según la condición.
Sintaxis: dataframe.where(condición)
filter(): esta función se usa para verificar la condición y dar los resultados, lo que significa que elimina las filas según la condición.
Sintaxis: dataframe.filter(condición)
Ejemplo 1: Uso de Where()
Programa de Python para soltar filas donde ID menos de 4
Python3
# drop rows with id less than 4 dataframe.where(dataframe.ID>4).show()
Producción:

Soltar filas con la universidad ‘vrs’:
Python3
# drop rows with college vrs dataframe.where(dataframe.college != 'vrs').show()
Producción:

Ejemplo 2: Uso de la función filter()
Programa de Python para soltar filas con id = 4
Python3
# drop rows with id 4 dataframe.filter(dataframe.ID!='4').show()
Producción:

Soltar filas con valores NA usando dropna
Los valores NA son el valor que falta en el marco de datos, vamos a eliminar las filas que tienen los valores que faltan. Se representan como nulos, al usar el método dropna() podemos filtrar las filas.
Sintaxis: dataframe.dropna()
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data with 5 row values
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 2"],
[None, "bobby", "company 3"],
["1", "sravan", "company 1"],
["2", "ojaswi", None],
["4", "rohith", "company 2"],
["5", "gnanesh", "company 1"],
["2", None, "company 2"],
["3", "bobby", "company 3"],
["4", "rohith", "company 2"]]
# specify column names
columns = ['Employee ID', 'Employee NAME', 'Company Name']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display actual dataframe
dataframe.show()
# drop missing values
dataframe = dataframe.dropna()
# display dataframe after dropping null values
dataframe.show()
Producción:

Soltar filas con valores nulos usando isNotNull
Aquí estamos eliminando las filas con valores nulos, estamos usando la función isNotNull() para eliminar las filas
Sintaxis: dataframe.where(dataframe.column.isNotNull())
Programa de Python para eliminar valores nulos en función de una columna en particular
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data with 5 row values
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 2"],
[None, "bobby", "company 3"],
["1", "sravan", "company 1"],
["2", "ojaswi", None],
[None, "rohith", "company 2"],
["5", "gnanesh", "company 1"],
["2", None, "company 2"],
["3", "bobby", "company 3"],
["4", "rohith", "company 2"]]
# specify column names
columns = ['ID', 'Employee NAME', 'Company Name']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
dataframe.show()
# removing null values in ID column
dataframe.where(dataframe.ID.isNotNull()).show()
Producción:

Eliminar filas duplicadas
Las filas duplicadas significan que las filas son las mismas en el marco de datos, vamos a eliminar esas filas usando la función dropDuplicates().
Ejemplo 1: código de Python para eliminar filas duplicadas.
Sintaxis: dataframe.dropDuplicates()
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data with 5 row values
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 2"],
["3", "bobby", "company 3"],
["1", "sravan", "company 1"],
["2", "ojaswi", "company 2"],
["6", "rohith", "company 2"],
["5", "gnanesh", "company 1"],
["2", "ojaswi", "company 2"],
["3", "bobby", "company 3"],
["4", "rohith", "company 2"]]
# specify column names
columns = ['ID', 'Employee NAME', 'Company Name']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
dataframe.show()
# remove the duplicates
dataframe.dropDuplicates().show()
Producción:
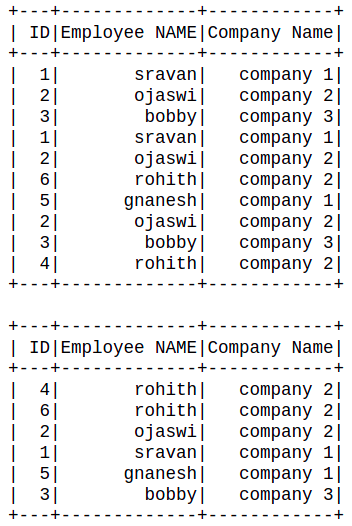
Ejemplo 2: elimine los duplicados en función del nombre de la columna.
Sintaxis: dataframe.dropDuplicates([‘column_name’])
Código de Python para eliminar duplicados según el nombre del empleado
Python3
# remove the duplicates dataframe.dropDuplicates(['Employee NAME']).show()
Producción:

Eliminar filas duplicadas mediante el uso de una función distinta
Podemos eliminar filas duplicadas usando una función distinta.
Sintaxis: dataframe.distinct()
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data with 5 row values
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 2"],
["3", "bobby", "company 3"],
["1", "sravan", "company 1"],
["2", "ojaswi", "company 2"],
["6", "rohith", "company 2"],
["5", "gnanesh", "company 1"],
["2", "ojaswi", "company 2"],
["3", "bobby", "company 3"],
["4", "rohith", "company 2"]]
# specify column names
columns = ['ID', 'Employee NAME', 'Company Name']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# remove the duplicates by using distinct function
dataframe.distinct().show()
Producción:

Publicación traducida automáticamente
Artículo escrito por gottumukkalabobby y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA