La siguiente tabla muestra las propiedades de cierre de los lenguajes formales:
REG = lenguaje regular
DCFL = lenguajes deterministas libres de contexto,
CFL = lenguajes libres de contexto,
CSL = lenguajes sensibles al contexto,
RC = recursivo.
RE = Enumerable recursivo
Considere que L y M son lenguajes regulares:
- La estrella de Kleene –
∑*, es un operador unario en un conjunto de símbolos o strings, ∑, que da el conjunto infinito de todas las strings posibles de todas las longitudes posibles sobre ∑ incluyendo λ. - Kleen Plus:
el conjunto ∑+ es el conjunto infinito de todas las strings posibles de todas las longitudes posibles sobre ∑ excluyendo λ. - Complemento –
El complemento de una lengua L (con respecto a un alfabeto E tal que E * contiene L) es E*–L. Dado que E* es seguramente regular, el complemento de un lenguaje regular siempre es regular. - Operador inverso:
dado el idioma L, L R es el conjunto de strings cuya inversión está en L. - Complemento –
El complemento de una lengua L (con respecto a un alfabeto E tal que E * contiene L) es E*–L. Dado que E* es seguramente regular, el complemento de un lenguaje regular siempre es regular. - Unión –
Sean L y M los lenguajes de las expresiones regulares R y S, respectivamente. Entonces R+S es una expresión regular cuyo idioma es (LUM). - Intersección –
Sean L y M los lenguajes de las expresiones regulares R y S, respectivamente, entonces es una expresión regular cuyo lenguaje es L intersección M. - Operador de diferencia establecida:
si L y M son idiomas regulares, también lo es L – M = strings en L pero no en M. - Homomorfismo:
un homomorfismo en un alfabeto es una función que da una string para cada símbolo en ese alfabeto. - Homomorfismo inverso:
sea h un homomorfismo y L un idioma cuyo alfabeto es el idioma de salida de h. h -1 (L) = {w | h(w) está en L}. - Sustitución:
la sustitución es una asignación de letra a idioma, que también se extiende a una asignación de string a idioma. Al identificar un lenguaje singleton {x} a la tx, los morfismos se ven como casos especiales de sustituciones. - Cociente izquierdo – Cociente izquierdo, o cociente de una lengua L por una palabra w es La lengua Lw = {x ∈ Σ* | wx ∈ L}
El cociente correcto de L1 con L2 es el conjunto de todas las strings x donde puede elegir algo de y de L2 y agregarlo a x para obtener algo de L1. Es decir, x está en el cociente si hay y en L2 para lo cual xy está en L1.)
| Operaciones | REGISTRO | DCFL | CFL | CSL | RC | RE |
| Unión | Y | norte | Y | Y | Y | Y |
| Intersección | Y | norte | norte | Y | Y | Y |
| Establecer diferencia | Y | norte | norte | Y | Y | norte |
| Complementar | Y | Y | norte | Y | Y | norte |
| Intersección con un lenguaje regular | Y | Y | Y | Y | Y | Y |
| Unión con una lengua regular | Y | Y | Y | Y | Y | Y |
| Concatenación | Y | norte | Y | Y | Y | Y |
| Estrella Kleene | Y | norte | Y | Y | Y | Y |
| Kleene más | Y | norte | Y | Y | Y | Y |
| Inversión | Y | Y | Y | Y | Y | Y |
| Homomorfismo sin épsilon | Y | norte | Y | Y | Y | Y |
| homomorfismo | Y | norte | Y | norte | norte | Y |
| Homomorfismo inverso | Y | Y | Y | Y | Y | Y |
| Sustitución sin épsilon | Y | norte | Y | Y | Y | Y |
| Sustitución | Y | norte | Y | norte | norte | Y |
| Subconjunto | norte | norte | norte | norte | norte | norte |
| Diferencia izquierda con un lenguaje regular (L-Regular) | Y | Y | Y | Y | Y | Y |
| Diferencia Correcta con un Lenguaje Regular (Regular-R) | Y | Y | norte | Y | Y | norte |
| Cociente izquierdo con un lenguaje regular | Y | Y | Y | norte | Y | Y |
| Cociente correcto con un lenguaje regular | Y | Y | Y | norte | Y | Y |
NOTA: si hacemos la unión, la intersección o la diferencia de conjunto de cualquier idioma con el idioma normal, el idioma no cambia.
Ejemplo
- CFL
Siempre es una buena idea convertir las operaciones secundarias en operaciones primarias.
Sean L 1 y L 2 dos idiomas.
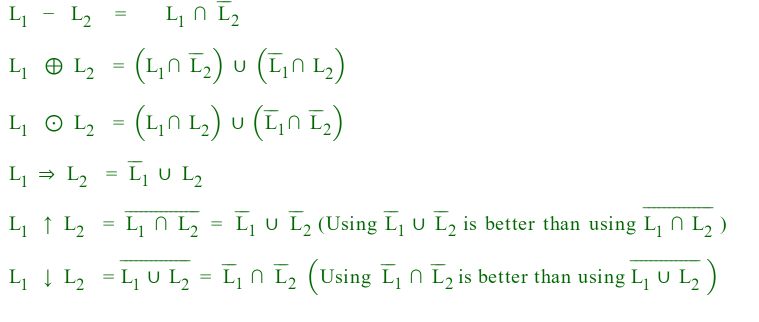
NOTA: Para
Publicación traducida automáticamente
Artículo escrito por siddharth_25 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA