Generalmente, en cualquier dispositivo se prefieren memorias que sean grandes (en términos de capacidad), rápidas y asequibles. Pero las tres cualidades no se pueden lograr al mismo tiempo. El costo de la memoria depende de su velocidad y capacidad. Con el Sistema de memoria jerárquica , los tres se pueden lograr simultáneamente.
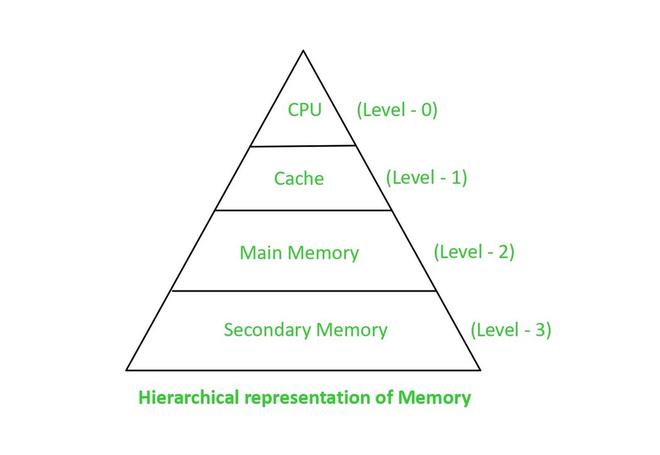
Jerarquía de memoria
El caché es una parte de la jerarquía presente junto a la CPU. Se utiliza para almacenar los datos e instrucciones de uso frecuente. Generalmente es muy costoso, es decir, cuanto mayor es la memoria caché, mayor es el costo. Por lo tanto, se utiliza en capacidades más pequeñas para minimizar los costos. Para compensar su menor capacidad, se debe asegurar que se utiliza en todo su potencial.
La optimización del rendimiento de la memoria caché garantiza que se utilice de manera muy eficiente en todo su potencial.
Tiempo promedio de acceso a la memoria (AMAT):
AMAT ayuda a analizar la memoria caché y su rendimiento. Cuanto menor sea el AMAT , mejor será el rendimiento. AMAT se puede calcular como,
AMAT = Hit Ratio * Cache access time + Miss Ratio * Main memory access time
= (h * tc) + (1-h) * (tc + tm)
Nota: Solo se accede a la memoria principal cuando se produce un error de memoria caché. Por lo tanto, el tiempo de caché también se incluye en el tiempo de acceso a la memoria principal.
Ejemplo 1: ¿Cuál es el tiempo promedio de acceso a la memoria para una máquina con una tasa de aciertos de caché del 75 % y un tiempo de acceso a caché de 3 ns y un tiempo de acceso a memoria principal de 110 ns?
Solución:
Average Memory Access Time(AMAT)= (h * tc) + (1-h) * (tc + tm)
Given,
Hit Ratio(h) = 75/100 = 3/4 = 0.75
Miss Ratio (1-h) = 1-0.75 = 0.25
Cache access time(tc) = 3ns
Main memory access time(effectively) = tc + tm = 3 + 110 = 113 ns
Average Memory Access Time(AMAT) = (0.75 * 3) + (0.25 * (3+110))
= 2.25 + 28.25
= 30.5 ns
Note: AMAT can also be calculated as Hit Time + (Miss Rate * Miss Penalty)
Ejemplo 2: Calcular AMAT cuando Hit Time es 0,9 ns, Miss Rate es 0,04 y Miss Penalty es 80 ns.
Solución :
Average Memory Access Time(AMAT) = Hit Time + (Miss Rate * Miss Penalty)
Here, Given,
Hit time = 0.9 ns
Miss Rate = 0.04
Miss Penalty = 80 ns
Average Memory Access Time(AMAT) = 0.9 + (0.04*80)
= 0.9 + 3.2
= 4.1 ns
Por lo tanto, si se reducen el tiempo de acierto, la tasa de fallas y la penalización de fallas, el AMAT se reduce, lo que a su vez garantiza un rendimiento óptimo de la memoria caché.
Métodos para reducir el tiempo de acierto, la tasa de fallas y la penalización por fallas:
Métodos para reducir el Hit Time:
1. Cachés pequeños y simples: si se requiere menos hardware para la implementación de cachés, entonces disminuye el tiempo de acierto debido a la ruta crítica más corta a través del hardware.
2. Evite la traducción de direcciones durante la indexación: las cachés que usan direcciones físicas para la indexación se conocen como caché física. Los cachés que utilizan las direcciones virtuales para la indexación se conocen como caché virtual. La traducción de direcciones se puede evitar mediante el uso de cachés virtuales. Por lo tanto, ayudan a reducir el tiempo de acierto.
Métodos para reducir la tasa de fallas:
1. Tamaño de bloque más grande: si se aumenta el tamaño de bloque, la localidad espacial se puede explotar de manera eficiente, lo que da como resultado una reducción de las tasas de fallas. Pero puede resultar en un aumento de las penalizaciones por fallos. El tamaño no se puede extender más allá de cierto punto, ya que afecta negativamente el punto de aumento de la tasa de fallas. Debido a que un tamaño de bloque más grande implica una menor cantidad de bloques, lo que resulta en un aumento de las fallas por conflicto.
2. Tamaño de caché más grande: el aumento del tamaño de caché da como resultado una disminución de las fallas de capacidad, lo que reduce la tasa de fallas. Pero aumentan el tiempo de impacto y el consumo de energía.
3. Mayor asociatividad: una mayor asociatividad da como resultado una disminución de las fallas en los conflictos. Por lo tanto, ayuda a reducir la tasa de fallas.
Métodos para reducir Miss Penalty:
1. Cachés de varios niveles: si solo hay un nivel de caché, debemos decidir entre mantener el tamaño de la caché pequeño para reducir el tiempo de acierto o hacerlo más grande para reducir la tasa de fallas. Ambos se pueden lograr simultáneamente introduciendo caché en los siguientes niveles.
Supongamos, si se considera un caché de dos niveles:
- La memoria caché de primer nivel es más pequeña y tiene ciclos de reloj más rápidos que los de la CPU.
- La caché de segundo nivel es más grande que la caché de primer nivel pero tiene ciclos de reloj más rápidos en comparación con la memoria principal. Este gran tamaño ayuda a evitar mucho acceso a la memoria principal. Por lo tanto, también ayuda a reducir la penalización por fallo.
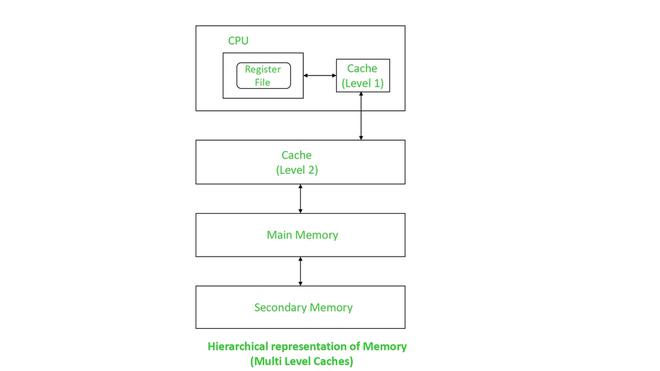
Representación jerárquica de la Memoria
2. Primera palabra crítica y reinicio temprano: generalmente, el procesador requiere una palabra del bloque a la vez. Por lo tanto, no hay necesidad de esperar hasta que se cargue el bloque completo antes de enviar la palabra solicitada. Esto se logra usando:
- La palabra crítica primero: También se le llama palabra solicitada primero. En este método, la palabra exacta requerida se solicita de la memoria y, tan pronto como llega, se envía al procesador. De esta manera, se logran dos cosas, el procesador continúa la ejecución y las otras palabras del bloque se leen al mismo tiempo.
- Reinicio anticipado: en este método, las palabras se recuperan en el orden normal. Cuando llega la palabra solicitada, se envía inmediatamente al procesador que continúa la ejecución con la palabra solicitada.
Estos son los métodos básicos a través de los cuales se puede optimizar el rendimiento de la memoria caché.
Publicación traducida automáticamente
Artículo escrito por patibandalp01 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA